避免过度拟合之正则化(转)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了避免过度拟合之正则化(转)相关的知识,希望对你有一定的参考价值。
“越少的假设,越好的结果”
商业情景:
当我们选择一种模式去拟合数据时,过度拟合是常见问题。一般化的模型往往能够避免过度拟合,但在有些情况下需要手动降低模型的复杂度,缩减模型相关属性。
让我们来考虑这样一个模型。在课堂中有10个学生。我们试图通过他们过去的成绩预测他们未来的成绩。共有5个男生和5个女生。女生的平均成绩为60而男生的平均成绩为80.全部学生的平均成绩为70.
现在有如下几种预测方法:
1 用70分作为全班成绩的预测
2 预测男生的成绩为80分,而女生的成绩为60分。这是一个简单的模型,但预测效果要好于第一个模型。
3 我们可以将预测模型继续细化,例如用每个人上次考试的成绩作为下次成绩的预测值。这个分析粒度已经达到了可能导致严重错误的级别。
从统计学上讲,第一个模型叫做拟合不足,第二个模型可能达到了成绩预测的最好效果,而第三个模型就存在过度拟合了。
接下来让我们看一张曲线拟合图

上图中Y与自变量X之间呈现了二次函数的关系。采用一个阶数较高的多项式函数对训练集进行拟合时可以产生非常精确的拟合结果但是在测试集上的预测效果比较差。接下来,我们将简要的介绍一些避免过度拟合的方法,并将主要介绍正则化的方法。
避免过度拟合的方法
1 交叉验证: 交叉验证是一轮验证的最简单的形式,每次我们将样本等分为k份,留一份作为测试样本并将其他作为训练样本。通过对训练样本的学习得到模型,将模型用于预测测试样本。循环上述步骤,使每一份样本都曾作为测试集。为了保持较低的方法,k值较大的交叉验证模型比较受青睐。
2 停止法: 停止法为初学者避免过度拟合提供了循环次数的指导
3 剪枝法: 剪枝法在GART (决策树)模型中应用广泛。它用于去掉对于预测提升效果较小的节点。
4 正则化: 这是我们将详细介绍的方法。该方法对目标函数的变量个数引入损失函数的概念。也就是说,正则化方法通过使很多变量的系数为0而降低模型的维度,减少损失。
正则化基础
给定一些自变量X,建立一个简单的因变量y与X之间的回归模型。回归方程类似于:
y = a1x1 + a2x2 + a3x3 + a4x4 .......
在上述方程中a1, a2, a3 …为回归系数,而x1, x2, x3 ..为自变量。给定自变量和因变量,基于目标函数估计回归系数a1, a2 , a3 …。对于线性回归模型目标函数为:
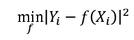
如果存在大量的x1 , x2 , x3 因变量,则可能出现过度拟合的问题。因此我们引入新的惩罚项构成新的目标函数来估计回归系数。在这种修正下,目标函数变为:

方程中的新加项可以是回归系数的平方和乘以一个参数λ。 如果λ=0 过度拟合上限的情景。λ趋于无穷则回归问题变为求y的均值。最优化λ需要找到训练样本和测试样本的的预测准确性之间的一个平衡点。
理解正则化的数学基础
存在各种各样的方法计算回归系数。一种非常常用的方法为坐标下降法。坐标下降是一种迭代方法,在给定初始值后不断寻找使得目标函数最小的收敛的回归系数值。因此我们集中处理回归系数的偏导数。在没有给出更多的导数信息前,我直接给出最后的迭代方程:
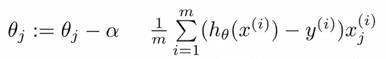 (1)
(1)
这里的θ是估计的回归系数,α为学习参数。现在我们引入损失函数,在对回归系数的平方求偏导数以后,将转化为线性形式。最终的迭代方程如下:
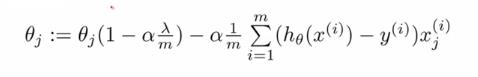 (2)
(2)
如果仔细观察该方程你会发现,ϑ每次迭代的开始点略小于之前的迭代结果。这是(1)与(2)两个迭代方程的唯一区别。而迭代方程(2)试图寻找绝对值最小的收敛的ϑ值。
结束语
在这篇文章中我们简单的介绍了正则化的思想。当然相关的概念远比我们介绍的深入。在接下来的一些文章中我们会继续介绍一些正则化的概念。
原文作者: TAVISH SRIVASTAVA
翻译: F.xy
原文链接:http://www.analyticsvidhya.com/blog/2015/02/avoid-over-fitting-regularization/
http://www.cnblogs.com/yymn/p/4646383.html
以上是关于避免过度拟合之正则化(转)的主要内容,如果未能解决你的问题,请参考以下文章