Opencv2.4.9源码分析——Cascade Classification
Posted zhaocj
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Opencv2.4.9源码分析——Cascade Classification相关的知识,希望对你有一定的参考价值。
前两篇文章分别介绍了级联分类器的原理和源码解析,下面我们给出一个具体的应用实例。
下面我们以车牌识别为例,具体讲解OpenCV的级联分类器的用法。在这里我们只对蓝底白字的普通车牌进行识别判断,对于其他车牌不在考虑范围内。而且车牌是正面照,略微倾斜可以,倾斜程度太大也是不在识别范围内的。
我们通过不同渠道共收集了1545幅符合要求的带有车牌图像的照片(很遗憾,我只能得到这么多车牌照片,如果能再多一些就更好了!),通过ACDSee软件手工把车牌图像从照片中剪切出来,并统一保存为jpg格式。为便于后续处理,我们把文件名按照数字顺序命名,如图8所示。然后我们把这些车牌图像保存到pos文件夹内。

图8 蓝底白字车牌图像
需要注意的是,在这里我们没有必要把车牌图像缩放成统一的尺寸(即正样本图像的大小),更没有必要把它们转换成灰度图像,这些工作完全可以由系统完成。我们只需要告诉系统车牌图像文件、车牌的位置,以及车牌的尺寸大小即可。
为了高效的完成上述工作,我们编写了以下代码:
#include "opencv2/core/core.hpp"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include <iostream>
#include <fstream>
#include <string>
using namespace cv;
using namespace std;
int main( int argc, char** argv )
{
ofstream postxt("pos.txt",ios::out); //创建pox.txt文件
if ( !postxt.is_open() )
{
cout<<"can not creat pos txt file!";
return false;
}
//N表示车牌图像的总数,c表示最终可以利用的车牌样本图像的数量
int N = 1545, c = 0;
int width, height, i;
String filename;
Mat posimage;
for(i=0;i<N;i++) //遍历所有车牌图像
{
filename = to_string(i) + ".jpg"; //得到当前车牌图像的文件名
posimage = imread("pos\\\\" + filename); //打开当前车牌图像
if ( posimage.empty() )
{
cout<<"can not open "+ filename +" file!"<<endl;
continue;
}
width = posimage.size().width; //当前车牌图像的宽
height = posimage.size().height; //当前车牌图像的高
//如果当前车牌图像的宽小于60,或高小于20,则剔除该车牌图像
if(width < 60 || height < 20)
{
cout<<filename +" too small!"<<endl;
continue;
}
//把当前车牌图像的信息写入pos.txt文件内
postxt<<"pos/" + filename + " 1 0 0 " + to_string(width) + " " + to_string(height)<<endl;
c++; //累计
}
cout<<c; //终端输出c值
postxt.close(); //关闭pos.txt文件
return 0;
}
执行完该程序后,在终端输出得到的c值为1390,这说明有155(1545-1390)个车牌图像由于尺寸过小而被剔除。另外,在当前目录下我们还得到了pos.txt文件,该文件正是系统所需要的,它的文件内容如图9所示。
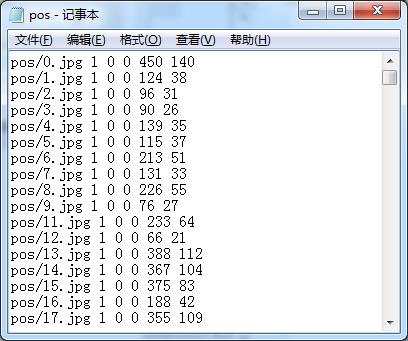
图9 pos.txt文件
在pos.txt文件中,每一行代表一个图像文件。我们以第一行为例,它表示pos文件夹内的0.jpg文件,后面的“1”表示该文件只有一个样本图像(即车牌),再后面的“0 0”表示该样本图像的左上角坐标,由于我们已经对图像进行了剪切,每个jpg文件就是一幅完成的车牌,所以所有行的这三个变量都是“1 0 0”。最后的“450 140”表示0.jpg文件的宽和高。
我们收集了10589幅大小不同的不含车牌图像的无水印、无logo、无日期的照片。这些照片统一转换为jpg格式,并且也是按照数字的顺序命名,如图10所示。然后我们把这些照片放入neg文件夹内。
图10 不含车牌图像的照片
这些照片的尺寸没有要求,只要大于正样本图像的尺寸即可,因为系统是对这些照片进行剪切,从而得到与正样本图像尺寸相同的负样本图像,所以一幅照片可以得到若干个负样本图像。这些照片尽量保证多样性,并且每幅照片的内容尽可能的丰富,当然最重要的一点是不能含有车牌信息。
我们还需要为系统提供一个保存有这些照片信息的文本文件。同样的,我们也写了一段简单的程序来完成这个工作:
#include "opencv2/core/core.hpp"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include <iostream>
#include <fstream>
#include <string>
using namespace cv;
using namespace std;
int main( int argc, char** argv )
{
ofstream negtxt("neg.txt",ios::out); //创建neg.txt文件
if ( !negtxt.is_open() )
{
cout<<"can not creat neg txt file!";
return false;
}
//N表示照片的总数,c表示最终得到的照片的数量
int N = 10589, c=0;
int i;
String filename;
Mat posimage;
for(i=0;i<N;i++)
{
filename = to_string(i) + ".jpg"; //照片文件名
posimage = imread("neg\\\\" + filename); //打开当前照片
if ( posimage.empty() )
{
cout<<"can not open "+ filename +" file!"<<endl;
continue;
}
negtxt<<"neg/" + filename<<endl; //向neg.txt文件写入照片文件名
c++; //累加
}
cout<<c; //终端输出c值
negtxt.close(); //关闭neg.txt文件
return 0;
}
执行完该程序后,在当前目录下得到了neg.txt文件,它的文件内容如图11所示。
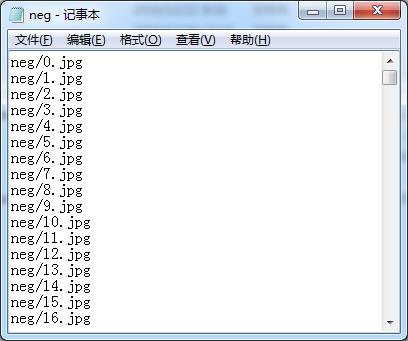
图11 neg.txt文件
以上内容准备好后,我们就可以利用Opencv提供的相关程序得到能够识别车牌的级联分类器了。
首先在D盘下新建plate文件夹,我们把前面提到的保存有大量照片图像的pos和neg这两个文件夹、以及pos.txt和neg.txt这两个文本文件复制到plate文件夹内,再在plate文件夹内新建data文件夹(后面需要)。由于本人的电脑是64位win7系统,编译器使用的是Microsoft Visual Studio 2012,因此需要从opencv/build/x64/vc11/bin文件夹内复制opencv_createsamples.exe和opencv_traincascade.exe这两个文件到plate文件夹内。opencv_createsamples.exe用于创建系统所需的正样本vec文件,opencv_traincascade.exe用于训练级联分类器。这两个文件都需要在命令行下运行。
opencv_createsamples.exe所需的参数较多,这里我们只把要用到的参数进行讲解:
-info:用于表示含有车牌照片的文本文件,即pos.txt
-bg:用于表示不含车牌照片的文本文件,即neg.txt
-vec:输出的正样本vec文件名,我们把这个文件命名为pos.vec
-num:车牌照片图像的数量,即1390
-w:正样本图像的宽(像素)
-h:正样本图像的高(像素)
后两个参数需要我们根据实际情况填写,由于我们只对蓝底白字的车牌进行识别,这类车牌的实际尺寸为440mm×140mm,我们必须要保持正样本图像的宽和高也是这个比例,而且宽和高不能过大,更不能过小。综合考虑,我们选择:-w为58,-h为18。
在前面我们准备车牌照片时,并没有把车牌缩放成58×18这个尺寸,这是因为opencv_createsamples.exe会根据-w和-h这两个参数对图像进行统一缩放处理的,所以前面就没有处理。
最终的opencv_createsamples.exe命令为:
opencv_createsamples.exe -info pos.txt -bg neg.txt -vec pos.vec -num 1390 -w 58 -h 18
为方便起见,我们把这个命令保存到createsamples.bat批处理文件中,这样只要执行该文件即可。执行的结果如图12所示,并且在plate文件夹内会生成pos.vec文件。
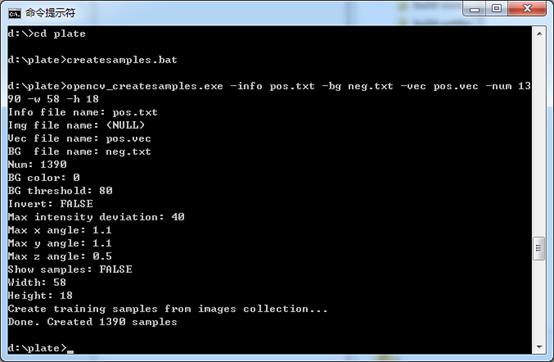
图12 opencv_createsamples.exe执行结果
下面就要执行opencv_traincascade.exe来训练级联分类器,该命令所需要的参数也较多,但都很重要,它们的含义如下:
-data:文件夹名,用于保存训练生成的各种xml文件,该文件夹一定要事先创建好,否则系统会报错,在这里,我们定义该文件夹名为data,它已在前面创建好
-vec:由opencv_createsamples.exe程序生成的正样本vec文件,即pos.vec
-bg:用于表示不含车牌照片的文本文件,即neg.txt
-numPos:训练级联分类器的每一级分类器(即强分类器)时所用的正样本数目
-numNeg:训练级联分类器的每一级分类器(即强分类器)时所用的负样本数目
-numStages:最终得到的级联分类器的级数,我们设置为12
-precalcValBufSize:用于存储预先计算特征值的内存空间大小,单位为MB
-precalcIdxBufSize:用于存储预先计算特征索引的内存空间大小,单位为MB
-stageType:强分类器的类型,目前只实现了AdaBoost,因此唯一的值(缺省值)为BOOST
-featureType:特征类型,HAAR(缺省值),LBP或HOG
-w:正样本图像的宽,必须与opencv_createsamples.exe命令的参数一致,即58
-h:正样本图像的高,必须与opencv_createsamples.exe命令的参数一致,即18
-bt:AdaBoost的类型,DAB,RAB,LB或GAB(缺省值)
-minHitRate:原理部分提到的每级分类器的最小识别率
-maxFalseAlarmRate:原理部分提到的每级分类器的最大错误率
-weightTrimRate:用于决策树的剪枝,缺省值为0.95
-maxDepth:决策树的最大深度,缺省值为1,即该决策树为二叉树(树墩形)
-maxWeakCount:强分类器所包含的最大决策树的数量,该值也与最大错误率有关,我们定义该值为150
-mode:如果特征为HAAR,则该参数决定了使用哪种HAAR状特征(见图1),BASIC(缺省值)、CORE或ALL
下面我们就重点介绍几个重要参数的选取。由于本人的计算机的内存为16G,为了最大化的利用该内存,我们把-precalcValBufSize和-precalcIdxBufSize这两个参数值都定义为5000,即5G。最小识别率和最大错误率决定了训练时间的长短和识别的质量,我们定义这两个值分别为0.999和0.25。-numPos指的是训练强分类器时所用的正样本数量,它并不是全体正样本的数量,原则上该值越大,分类器的质量越好,但还要考虑识别率,如果识别率设置得不高,会有一些正样本被识别为负样本,因此要有一定的冗余,当然系统也考虑到了这点,即如果正样本都用完了,并且还没有达到numPos所指定的数量,则系统会调整该值为实际的数量(详细内容见前面的源码分析部分)。我们设置该值为1300。-numNeg设置为多大似乎还没有定论,但通过阅读Viola & Jones算法的原文发现,他们使用9832个正样本(4916个人脸图像,再加上它们的垂直镜像图像)和10000个负样本,正、负样本的数量接近于1:1,因此我们设置numNeg为1350。
最终的opencv_traincascade.exe命令为:
opencv_traincascade.exe -data data -vec pos.vec -bg neg.txt -numPos 1300 -numNeg 1350 -numStages 12 -precalcValBufSize 5000 -precalcIdxBufSize 5000 -w 58 -h 18 -maxWeakCount 150 -mode ALL -minHitRate 0.999 -maxFalseAlarmRate 0.25
同理,我们也把这个命令保存到批处理文件train.bat中。这里还需要注意一点的是:参数的大小写一定要分区,否则系统出错。
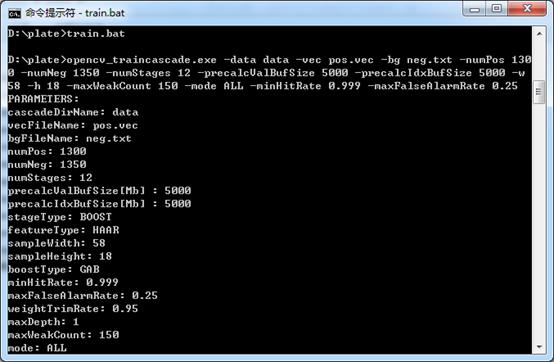
图13 opencv_traincascade.exe执行过程中输出的参数信息
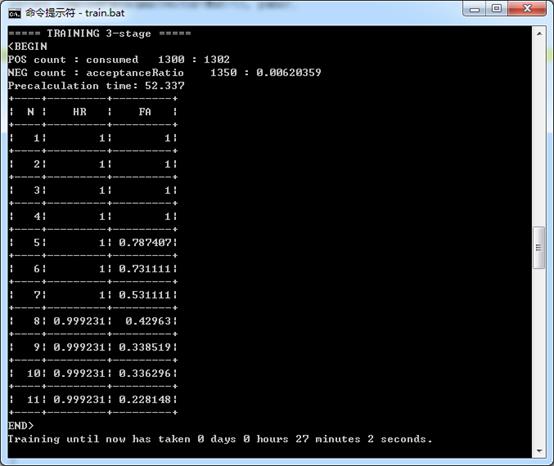
图14 opencv_traincascade.exe执行过程中输出的第3级强分类器的信息
在执行该命令时,终端首先输出一些参数信息,如图13所示。然后是输出级联分类器的每级强分类器的训练信息,因为我们设置了numStages为12,所以一共有12个强分类器:0-stage至11-stage。图14所示为第3级强分类器的信息。下面我们逐条分析这些信息的含义:
===== TRAINING 3-stage =====
<BEGIN
表示开始训练第3级强分类器。
POS count : consumed 1300 : 1302
在训练本级强分类器时,能够使用1300个正样本图像,而这1300个正样本图像是从1302个正样本图像集中选取出来的,也就是说此时有两个正样本没有被识别出来。前面的1300正是opencv_traincascade.exe命令中参数numPos所指定的数量,有时这个值会小于numPos,说明numPos设置过大,并且最小识别率设置的较小,从而导致正样本图像数量不足。后面的1302可以用来表示当前级联分类器的识别率,即由0-stage、1-stage、2-stage组成的级联分类器的识别率。此时的识别率为99.846%,因为1300÷1302=0.99846。
NEG count : acceptanceRatio 1350 : 0.00620359
在训练本级强分类器时,能够使用1350个负样本图像,这个数正是opencv_traincascade.exe命令中参数numNeg所指定的数量,当然这个数也有可能小于numNeg,这是因为前面信息中POS count的数值不等于numPos所致,具体数值的大小见源码分析。后面的0.00620359表示负样本的接受率,也就是当前强分类器之前的所有强分类器(0-stage、1-stage、2-stage)构成的级联分类器的错误率,即经过当前级联分类器预测后,这些被预测为正样本而实际为负样本的1350幅图像是从多少个负样本图像中得到的。级联分类器的特点是后一级的强分类器只接收那些前面分类器认为是正样本的数据,把负样本预测为正样本,这种情况会随着训练级数的增加,困难程度也在增加,当然这种困难程度还与opencv_traincascade.exe命令中所设置的最大错误率maxFalseAlarmRate有关,错误率设置的越低,困难程度会越大。以本级为例,这1350个负样本是从二十多万个负样本中选择出来的,计算公式为:1350÷0.00620359≈217615。在本例的最后一级强分类器的训练中,这个数值甚至会高达十亿。所以训练过程中的时间消耗主要就在这里。在没有显示该行信息之前,终端输出的是下列信息:NEG current samples: XXXX。XXXX代表着当前时刻得到的负样本数量,这个数值会逐渐增加,当增加到1350时,则会正常显示上面的信息。当此时得到的级联分类器的错误率小于我们所设置的错误率时(以此时为例,当前已得到了3个强分类器:0-stage、1-stage、2-stage,现在要训练第4个强分类器3-stage,当这个强分类器训练好后,这4个强分类器构成的级联分类器应该满足的最大错误率为:0.25×0.25×0.25×0.25=0.00390625),则系统会停止训练,因为当前得到的级联分类器已经满足了要求,无需再训练下去了。
Precalculation time: 52.337
表示预先计算特征值所消耗的时间,即在没有构建强分类器之前,我们就把一部分特征值计算好了,该值与opencv_traincascade.exe命令中的参数precalcValBufSize和precalcIdxBufSize有关,也就是我们事先为此开辟的内存越大,所保存的特征值就越多,因此计算这些特征值所花费的时间就越长。由于在构建强分类器之前,要用到的特征值都已计算好,所以构建强分类器的时间就大大缩短了。
+------+-------------+-------------+
| N| HR | FA |
+------+-------------+-------------+
| 1| 1| 1|
+------+-------------+-------------+
| 2| 1| 1|
+------+-------------+-------------+
…… ……
+------+-------------+-------------+
| 10|0.999231|0.336296|
+------+-------------+-------------+
| 11|0.999231|0.228148|
+------+-------------+-------------+
N表示当前强分类器的弱分类器(即决策树)的训练得到的数量,HR表示当前强分类器的识别率,FA表示当前强分类器的错误率。我们从倒数第2行开始,此时训练得到了10棵决策树,识别率为99.9231%,错误率为33.6296%,识别率满足了要求,即大于最小识别率99.9%,但错误率不满足要求,即它大于最大错误率25%,所以还需要继续训练,当又得到了一棵决策树时(即此时有11棵决策树),识别率和错误率都满足了要求(99.9231%>99.9%,22.8148%<25%)。
END>
表示此时该级的强分类器已经得到,因为识别率和错误率都满足了要求,所以此级强分类器的训练结束。
Training until now has taken 0 days 0 hours27 minutes 2 seconds.
表示到目前为止,训练级联分类器共用时27分2秒。
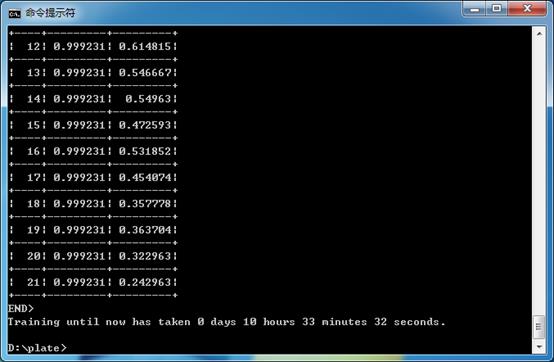
图15 opencv_traincascade.exe命令执行结束
图15显示了整个级联分类器训练完成后的界面,可以看出一共训练了10多个小时。我的计算机的CPU是Intel Core i5-4690K。如果我们把识别率和错误率分别改为0.9995和0.2,则需要一天多的时间,如果再把级数调整为13级,则需要6天。
当训练结束后,在data文件夹内会得到cascade.xml文件,这正是我们需要的级联分类器数据,我们利用它就可以识别出车牌。
下面的程序是一个简单的应用:
#include "opencv2/core/core.hpp"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/objdetect/objdetect.hpp"
#include <iostream>
#include <fstream>
#include <string>
using namespace cv;
using namespace std;
int main( int argc, char** argv )
{
CascadeClassifier classifier("cascade.xml"); //实例化级联分类器
Mat img = imread("car.jpg"); //读取照片
vector<Rect> plates; //代表车牌区域
//车牌识别,默认识别的最小车牌为正样本的面积(这里就是58×18),最大为整幅照片的面积,即只能识别面积为58×18以上的车牌
classifier.detectMultiScale(img, plates);
for(int I = 0; i < plates.size(); i++) //画出车牌区域
rectangle(img, plates[i], Scalar(255, 0, 255), 2);
imshow("plates", img);
waitKey(0);
return 0;
}

图16 识别结果
图16为运行的效果。由于手上的车牌照片不多,无法对识别效果做全面的衡量,但从不多的实验结果来看,虽然有错检的情况,检测到的车牌也有不完整的现象,但基本上能够满足要求。我通过一些实验发现,单纯的提高识别率或降低错误率、以及增加级数似乎都不能改善上述问题,我认为只有增大正样本的数量才是提高识别质量的有效方法。
下面是对视频文件进行车牌识别:
#include "opencv2/core/core.hpp"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/objdetect/objdetect.hpp"
#include <iostream>
#include <fstream>
#include <string>
using namespace cv;
using namespace std;
int main( int argc, char** argv )
{
VideoCapture vedio("cars.avi"); //读取视频
if(!vedio.isOpened())
{
cout<<"视频打开失败!"<<endl;
return 1;
}
double rate= vedio.get(CV_CAP_PROP_FPS); //得到帧频
int delay= int(1000/rate); //定义一个延时时间
Mat frame;
Size size = Size(int(vedio.get( CV_CAP_PROP_FRAME_WIDTH )), int(vedio.get( CV_CAP_PROP_FRAME_HEIGHT ))); //视频图像的尺寸
//定义一个写入视频文件
VideoWriter writer("plates.avi", CV_FOURCC('M','J','P','G'), rate, size, true);
if (!writer.isOpened())
{
cout << "初始化VideoWriter失败!" << endl;
return 1;
}
CascadeClassifier classifier("cascade.xml");
while(true)
{
if (!vedio.read(frame))
break;
vector<Rect> plates;
//车牌检测,这里设定车牌的最大尺寸为190×60
classifier.detectMultiScale(frame, plates, 1.1, 3, 0, Size(), Size(190, 60));
for(int i = 0; i < plates.size(); i++)
rectangle(frame, plates[i], Scalar(255, 0, 255), 2);
//加上文字
putText(frame,"http://blog.csdn.net/zhaocj",Point(50,60),CV_FONT_HERSHEY_COMPLEX,0.7,Scalar(255,0,0), 2);
writer.write(frame); //写视频
if (cv::waitKey(delay)>=0)
break;
}
vedio.release();
return 0;
}
我把视频的结果上传到了下列网址。该视频为3分钟,可以看出,在车牌的可识别尺寸范围内,能够准确识别车牌,当然,也有错检和车牌识别不完整的现象:
http://v.youku.com/v_show/id_XMjI4ODM3Mjk1Ng==.html
另外,我把cascade.xml文件也上传到了下列网址,大家可以下载检验:
http://download.csdn.net/detail/zhaocj/9737259
以上是关于Opencv2.4.9源码分析——Cascade Classification的主要内容,如果未能解决你的问题,请参考以下文章