Spark&Hive结合起来
Posted 蜗牛不爱海绵宝宝
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark&Hive结合起来相关的知识,希望对你有一定的参考价值。
1.spark与Hive结合起来
前提:当你spark的版本是1.6.1的时候,你的Hive版本要1.2.1,用别的版本会有问题
我们在做的时候,Hive的版本很简单,我们只需要解压缩,告诉他Hive的源数据在哪里即可
1.首先我们进入/conf/hive-site.xml文件,进行修改jdbc的配置
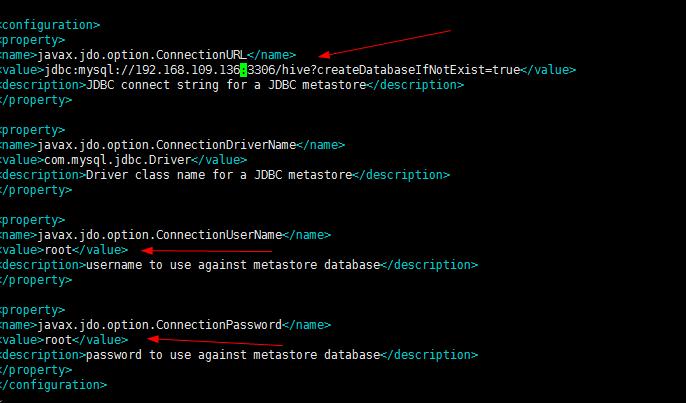
则此时这个IP要改为only的vm1下的那个IP,不能改为自己无线网络的IP
2.进入bin:./bin/hive
执行成功,会自动创建hive这个库
hive中创建person表
切记:在此之前,由于我们的mysql的字符集编码是utf-8,则我们要是用hive,则就要使用latin1
alter databases hive character set latin1
3.建表
create table person(id int,name string,age int) row format delimited fields terminated by ","
4.从hdfs导入数据
load data inpath "hdfs://192.168.109.136:9000/person/person.txt" into table person
此时上面的操作报
Please check that values for params "default.name" and "hive.metastore.warehouse.dir" do
not conf 是由于namenode的不一致
此时修改为weekday01正确
load data inpath "hdfs://weekday01:9000/person/person.txt" into table person
select * from person
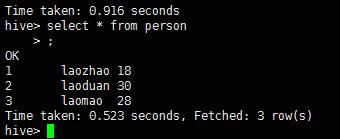
select * from person order by id desc此时这个就会调用集群上的mapReduce
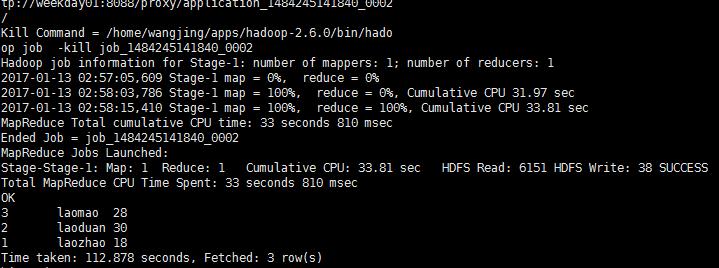
不过这个样子有点慢,我们可以使用spark来进行计算
以上是关于Spark&Hive结合起来的主要内容,如果未能解决你的问题,请参考以下文章