OpenCV — 人脸识别
Posted 南丶烟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OpenCV — 人脸识别相关的知识,希望对你有一定的参考价值。
前段时间弄过一下人脸识别相关的东西,记录一下
撰写不易,转载需注明出处:http://blog.csdn.net/jscese/article/details/54409627本文来自 【jscese】的博客!
概念
FaceDetect
人脸检测 在一张图像中判断是否存在人脸并找出人脸所在的位置
FaceRecognize
人脸识别 在人脸检测的基础上收集人脸数据集合进行处理保存信息,将输入人脸与保存的信息进行比对校验,得到是否为其中某个人脸
特征值
以某种特定规则对输入源进行处理得到具有唯一性质量化的值,在人脸识别中特征值的提取有
HOG-方向梯度直方图 , HAAR-like特征 , LBP-局部二进制模式 三种方法
前面转载的博客有介绍:图像特征提取三大法宝:HOG特征,LBP特征,Haar特征
分类器
根据特征值界定输入事物是否属于已知某种类别的过滤条件组合,未知类别的算聚类器,弱分类器:分类器的正确率高于随机分类(50%),强分类器:能满足预期分类并且正确率很高的分类器
Adaboost
迭代算法,同一个训练集合下训练多个弱分类器,把弱分类器迭代组合成一个强分类器
算法具体原理实现:
这里写链接内容
这里写链接内容
级联分类器
将多个同类型的分类器联合起来进行推算整合以得到符合目标的最终分类器的方法
最终的分类处理流程如下图:
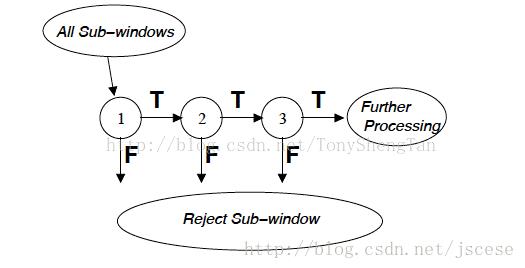
adaboost训练出来的强分类器一般具有较小的误识率,但检测率并不很高,一般情况下,高检测率会导致高误识率,这是强分类阈值的划分导致的,要提高强分类器的检测率既要降低阈值,要降低强分类器的误识率就要提高阈值
级联强分类器的策略是,将若干个强分类器由简单到复杂排列,希望经过训练使每个强分类器都有较高检测率,而误识率可以放低,比如几乎99%的人脸可以通过,但50%的非人脸也可以通过,这样如果有20个强分类器级联,那么他们的总识别率为0.99*20 98%,错误接受率也仅为0.5*20 0.0001%。这样的效果就可以满足现实的需要了
设K是一个级联检测器的层数,D是该级联分类器的检测率,F是该级联分类器的误识率,di是第i层强分类器的检测率,fi是第i层强分类器的误识率。如果要训练一个级联分类器达到给定的F值和D值,只需要训练出每层的d值和f值,这样:
D*K = D,f*K = F
级联分类器的要点就是如何训练每层强分类器的d值和f值达到指定要求
算法伪代码如下:
1)设定每层最小要达到的检测率d,最大误识率f,最终级联分类器的误识率Ft;
2)P=人脸训练样本,N=非人脸训练样本,D0=1.0,F0=1.0;
3)i=0;
4)for : Fi>Ft
++i;
ni=0;Fi=Fi-1;
for : Fi>f*Fi-1
++ni;
利用AdaBoost算法在P和N上训练具有ni个弱分类器的强分类器;
衡量当前级联分类器的检测率Di和误识率Fi;
for : di<d*Di-1;
降低第i层的强分类器阈值;
衡量当前级联分类器的检测率Di和误识率Fi;
N = Φ;
利用当前的级联分类器检测非人脸图像,将误识的图像放入N;
分类器生成及使用
一个高准确率的级联分类器的主要生成步骤如下:
1.大量样本集合,特征值的提取
2.通过adaboost 训练多个弱分类器并迭代为强分类器
3.多层级联强分类器,得到最终的级联分类器
这些训练流程完成之后结果以xml的方式保存起来,就是分类器文件,opencv中包含了以上的实现,并且已经存放了许多已经训练好的不同类型的不同特征值提取生成的的级联分类器
Opencv中可以直接加载这些分类器文件,并且给出了便捷的API
OpenCV 中的人脸识别
人脸检测:
Opencv源码中的分类器存放路径:opencv-2.4.13\\data\\
其中有hog haar lbp 分类目录,还有针对gpu使用的分类器文件,当使用gpu 或者 ocl时候需要加载此类分类器文件
Cpu进行的人脸检测实现类为 CascadeClassifier ,在 objdetect 模块中,主要api实现文件:
opencv-2.4.13\\modules\\objdetect\\src\\cascadedetect.cpp
调用opencl处理的类 OclCascadeClassifier, 在ocl模块中实现:
opencv-2.4.13\\modules\\ocl\\src\\haar.cpp
还包含了gpu-cuda处理的检测,属于windows的范畴 opencv-2.4.13\\modules\\gpu\\src\\cascadeclassifier.cpp
检测包含的主要api:
CV_WRAP bool load( const string& filename );用于加载分类器文件
CV_WRAP virtual void detectMultiScale( const Mat& image,
CV_OUT vector<Rect>& objects,
double scaleFactor=1.1,
int minNeighbors=3, int flags=0,
Size minSize=Size(),
Size maxSize=Size() );
用于检测图像中的人脸
参数1:image–待检测图片,一般为灰度图像加快检测速度;
参数2:objects–被检测物体的矩形框向量组;
参数3:scaleFactor–表示在前后两次相继的扫描中,图像被缩放的比例,1.1即每次缩放10% 用于检测
参数4:minNeighbors–表示构成检测目标的相邻矩形的最小个数(默认为3个)。
如果组成检测目标的小矩形的个数和小于 min_neighbors - 1 都会被排除。
如果min_neighbors 为 0, 则函数不做任何操作就返回所有的被检候选矩形框,
这种设定值一般用在用户自定义对检测结果的组合程序上;(没搞懂.使用默认值)
参数5:flags–要么使用默认值,要么使用CV_HAAR_DO_CANNY_PRUNING,如果设置为
CV_HAAR_DO_CANNY_PRUNING,那么函数将会使用Canny边缘检测来排除边缘过多或过少的区域,
因此这些区域通常不会是人脸所在区域;
参数6、7:minSize和maxSize用来限制得到的目标区域的范围。
测试用例代码和效果可参考后面的 Facedetect测试用例。
人脸识别
Opencv为人脸识别封装FaceRecognizer类,往下三种类型的识别器,分别为:
EigenFaceRecognizer
FisherFaceRecognizer
LBPHFaceRecognizer
是以根据不同的特征值来进行识别,主要的实现在contrib模块中:
\\opencv-2.4.13\\modules\\contrib\\src\\facerec.cpp
通过
createEigenFaceRecognizer(…)
createFisherFaceRecognizer(…)
createLBPHFaceRecognizer(…)
不同的识别器 构造时需要传入相关的参数,比如Eigen 和 Fisher的需要可以选择性传入num_components 和threshold 分别代表识别器通过PCA降维处理时保留的图像维度,默认为全保留,以及在识别时,传入图像与最相近距离阀值的设置,关乎识别的精度,默认为很大的一个值,可以通过接口读取以及设置该值,如下:
getDouble(“threshold”));
set(“threshold”, 1600.0f);
如果传入识别的图像与训练好的信息集合中最相近的一帧图像距离为1500,此值小于1600的阀值,那我们就认定识别到了这个人,反之找不到此人
主要的api:
CV_WRAP virtual void train(InputArrayOfArrays src, InputArray labels) = 0;将样本进行PCA降维提取保存到一个投影空间中,src与label一一对应
// Gets a prediction from a FaceRecognizer.
virtual int predict(InputArray src) const = 0;
// Predicts the label and confidence for a given sample.
CV_WRAP virtual void predict(InputArray src, CV_OUT int &label, CV_OUT double &confidence) const = 0;
进行识别,传入需要识别的对象 src,label即为结果,confidence就是置信度,就是上面说到的 距离可能为1500. 为0 就是100%完全一样的两帧画面。
// Serializes this object to a given filename.
CV_WRAP virtual void save(const string& filename) const;
// Deserializes this object from a given filename.
CV_WRAP virtual void load(const string& filename);
经过初始化好的识别器经过train之后,可以惊醒predict 也可以将此时train好的数据信息 save起来
下次初始化一个识别器直接load 就可以免去每次的train。
测试用例代码可参考最后的 Facerecognize测试用例。
Opencv 编译移植问题
编译配置ocl-neon-stltype
Opencv的编译配置问题,选的linux版本opencv源码,android的是现成的库,直接到opencv-2.4.13\\platforms\\scripts目录下新建一个配置脚本cmake_android_arm.sh,内容如下:
#!/bin/sh
cd `dirname $0`/..
mkdir -p build_android_arm
cd build_android_arm
export ANDROID_NDK=/home/local/ACTIONS/jiangbin/tool/android-ndk-r10
export ANDROID_NATIVE_API_LEVEL=19
export ANDROID_TOOLCHAIN_NAME=arm-linux-androideabi-4.8
export ANDROID_SDK=/home/local/ACTIONS/jiangbin/tool/android-sdk-linux
export PATH=$ANDROID_SDK/tools:$ANDROID_SDK/platform-tools:$PATH
cmake \\
-DBUILD_SHARED_LIBS=ON \\
-DBUILD_opencv_apps=ON \\
-DBUILD_ANDROID_EXAMPLES=ON \\
-DBUILD_DOCS=ON \\
-DBUILD_EXAMPLES=ON \\
-DBUILD_PERF_TESTS=ON \\
-DBUILD_TESTS=ON \\
-DENABLE_VFPV3=ON \\
-DENABLE_NEON=ON \\
-DWITH_OPENCL=ON \\
-DINSTALL_C_EXAMPLES=ON \\
-DINSTALL_PYTHON_EXAMPLES=ON \\
-DINSTALL_ANDROID_EXAMPLES=ON \\
-DINSTALL_TESTS=ON \\
-DDOXYGEN_EXECUTABLE=/usr/bin/doxygen \\
-DANDROID_STL=stlport_static \\
-DANDROID_ABI=armeabi-v7a with NEON \\
-DCMAKE_TOOLCHAIN_FILE=../android/android.toolchain.cmake $@ ../..
make clean
make -j8
make install
配置好NDK路径以及编译工具链,往下就是各个功能项的开关
DBUILD_SHARED_LIBS 最终链接生成动态库
DENABLE_NEON 打开cpu的neon
DWITH_OPENCL 编译ocl模块
DANDROID_STL=stlport_static 这个是配置C++运行需要的模板库的类型,默认为gnustl_static
这些配置宏的定义以及默认初始值可以在\\opencv-2.4.13\\platforms\\android\\android.toolchain.cmake中查看
存在的问题
Stl
并且还发现一个问题:就是按照上面的编译脚本DANDROID_STL=stlport_static 的方式来编译整个opencv,在我们的android平板上跑opencv自带的ocl用例,会出现stl库兼容性的问题,一些filestream类读取等会存在异常问题,换成默认的gnustl_static 就不会存在问题,但是stlport_static 这种模式是配置文件中列出来支持的,暂没搞清楚是不是NDK环境或者其它配置项存在问题导致
当DANDROID_STL= gnustl_static 默认配置编译的时候,如果想直接使用opencv编译出来的动态库,在Android.mk中就不能引入stlport支持以及头文件,否则string会传递异常,但是发现android本身的裁剪的stdc++ 满足不了opencv的编译需求,存在stl兼容性的问题
Neon
开关编译配置生效,代码中的配置宏也没有问题,搜查到只有video以及3rdparty部分才用到,objdetect以及contrib等模块中并没有使用,应该是不支持
OpencvManager
Opencv为android准备了一套SDK,类似:OpenCV-2.4.13.1-android-sdk
然后提供了一套java的api,提供了一套从java到底层opencv实现库的中间件,以apk service形式存在:opencvmanager, sdk种的原理图如下:
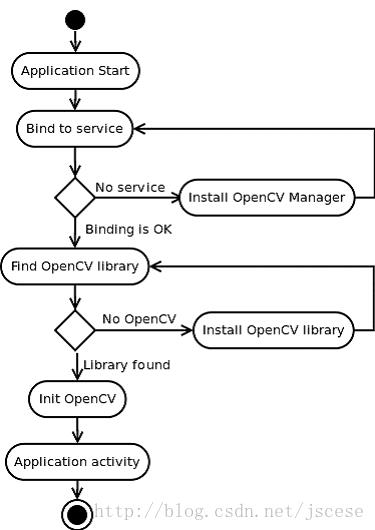
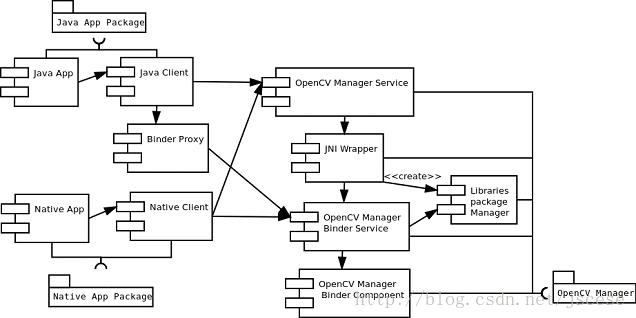
具体的实现细节可参考OpenCV-2.4.13.1-android-sdk doc目录中的opencv2manager.pdf
这样只要安装了这个opencvmanager apk,apk中的libopencv_java.so 就是封好的底层libraries,就可以使用opencv封好的java api开发apk了
也可以不用sdk java api往下调,自己封一层jni ,然后以gunstl_static形式链接opencv生成的静态库集合,需要用NDK来编译,详细可参考
OpenCV-2.4.13.1-android-sdk\\OpenCV-android-sdk\\samples\\face-detection\\jni
需要定义Application.mk内容
还可以过掉opencvmanager这个中间环节,不使用sdk java提供的api往下,全部都走jni,编译我们自己的jni的时候把需要的opencv库以静态或者动态的方式打包到我们的apk中。调试发现sdk java部分的api功能也不全,有的功能接口不支持,比如FaceRecognizer的使用还是得走jni往下
去掉opencvmanager的依赖可参考:
这里写链接内容
有使用apk的方式验证了人脸识别的收集和检测,java sdk中提供了对camera 每一帧数据的处理回调
单独的人脸检测可以直接使用java sdk + opencvmanager-apk 就可以实现,可以参考opencv自带的facedetect apk这个例子。
如果还要在检测的时候加上识别功能就需要自己定义jni往下初始化FaceRecognizer,调用关系跟下面的C++实现基本雷同,代码就不贴了,使用方法可参考往下的测试用例
Facedetect测试用例
简述:
需要opencv的头文件以及库文件,在android源码中编译为二进制测试,写好android.mk即可,这里直接使用cpu检测
CascadeClassifier类,调用了load以及detectMultiScale接口,检测完成得到的检测到的人脸矢量坐标在原图上标记成方框,保存
#include "include/opencv2/objdetect/objdetect.hpp"
#include "include/opencv2/highgui/highgui.hpp"
#include "include/opencv2/imgproc/imgproc.hpp"
#include <utils/Log.h>
#define LOG_TAG "opencv"
using namespace std;
using namespace cv;
int main()
{
ALOGE("begain = \\n");
CascadeClassifier cpufaceCascade;
const string path="haarcascade_frontalface_alt.xml";
const string gpu_path="haarcascade_frontalface_alt-GPU.xml";
if(!cpufaceCascade.load(path))
{
ALOGE("cpufaceCascade.load error \\n");
return -1;
}
Mat img = imread("face_detect.jpg", CV_LOAD_IMAGE_GRAYSCALE);
if(img.empty())
{
ALOGE("img.empty\\n");
return 1;
}
Mat imgGray;
vector<Rect> faces;
if(img.channels() ==3)
{
cvtColor(img, imgGray, CV_RGB2GRAY);
ALOGE("img cvtColor\\n");
}
else
{
imgGray = img;
}
ALOGE("cpu begain detectMultiScale\\n");
cpufaceCascade.detectMultiScale(imgGray, faces, 1.1, 3, 0);
ALOGE("cpu detect = faces.size= %d\\n",faces.size());
if(faces.size()>0)
{
for(int i =0; i<faces.size(); i++)
{
rectangle(img, Point(faces[i].x, faces[i].y), Point(faces[i].x + faces[i].width, faces[i].y + faces[i].height),
Scalar(0, 255, 0), 1, 8);
}
}
IplImage src = IplImage(img);
IplImage *input = cvCloneImage(&src);
cvSaveImage("/data/face_detect_save1.jpg", (CvArr*) input);
ALOGE("cvSaveImage from cpudetect compelete \\n");
return 0;
}
检测到人脸并用方框画出保存,图像如下:

Facerecognize测试用例:
简述:
与检测的环境相同,这里采用了1-10张标号的人脸图像,其中1-5 号是第一个人的不同表情头像,6-10号为第二个人不同表情头像,
最后的03标号为第三个人头像。
训练数据取1-4 ,6-9 总共8张头像,刻意不把第5张和第10张包加载到识别器中,以用来识别
同时设置了enginefacerecognize的阀值参数,也就是前面说到过的1500,1600 的关系,在这里运行之后就能看出来
通过两种不同的predict的调用,可以得出识别的置信度,低于识别器设置的阀值就认定识别成功,否则返回-1,代表没有识别到
最后save了这次的训练结果,再次创建识别器直接load 测试
#include "include/opencv2/objdetect/objdetect.hpp"
#include "include/opencv2/highgui/highgui.hpp"
#include "include/opencv2/imgproc/imgproc.hpp"
#include "include/opencv2/contrib/contrib.hpp"
#include <utils/Log.h>
#define LOG_TAG "opencv"
using namespace std;
using namespace cv;
int main()
{
ALOGE("face recongnition begin\\n");
vector <Mat> faces;
vector <int> labels;
char ss[128];
int predicted_label = -1;
double predicted_confidence = 0.0;
for (size_t i = 1; i <= 5; i++) {
sprintf(ss,"face/%d.bmp",i);
ALOGE("face imread name =%s\\n",ss);
faces.push_back(imread(ss,CV_LOAD_IMAGE_GRAYSCALE));
labels.push_back(1);
}
Mat testpeople1=faces[faces.size()-1];
int testlabel1=labels[labels.size()-1];
faces.pop_back();
labels.pop_back();
ALOGE("face recongnition 1 faces-vec size =%d to train except for 5.bmp \\n",faces.size());
//==========================================================
for (size_t i = 6; i <= 10; i++) {
sprintf(ss,"face/%d.bmp",i);
faces.push_back(imread(ss, CV_LOAD_IMAGE_GRAYSCALE));
labels.push_back(2);
}
Mat testpeople2=faces[faces.size()-1];
int testlabel2=labels[labels.size()-1];
faces.pop_back();
labels.pop_back();
ALOGE("face recongnition 1+2 faces-vec size =%d to train except for 5.bmp and 10.bmp \\n",faces.size());
//==========================================================
// --------------------------------------------------------------------------
// createEigenFaceRecognizer,createFisherFaceRecognizer,createLBPHFaceRecognizer
Ptr<FaceRecognizer> face_recog = createEigenFaceRecognizer();
ALOGE("face recongnition train -the threshold=%8f\\n",face_recog->getDouble("threshold"));
//
face_recog->set("threshold", 1600.0f);//threshold
ALOGE("face recongnition the threshold=%8f\\n",face_recog->getDouble("threshold"));
face_recog->train(faces, labels);
ALOGE("face recongnition train over\\n");
/*opencv-2.4.13\\modules\\contrib\\src\\facerec.cpp line:478
*
* minDist = DBL_MAX;
* minClass = -1;
*
* if((dist < minDist) && (dist < _threshold)) {
minDist = dist;
minClass = _labels.at<int>((int)sampleIdx);
}
*
*
*
*
* */
// predict method 1 test
// int face_id0 = face_recog->predict(imread("face/1.bmp", CV_LOAD_IMAGE_GRAYSCALE)/*testSample*/);
// int face_id1 = face_recog->predict(imread("face/8.bmp", CV_LOAD_IMAGE_GRAYSCALE));
// int face_id2 = face_recog->predict(imread("face/3.bmp", CV_LOAD_IMAGE_GRAYSCALE));
// ALOGE("face recongnition face_id0 =%d face_id1 =%d face_id2 =%d\\n",face_id0,face_id1,face_id2);
// int face_testid1 = face_recog->predict(testpeople1);
// int face_testid2 = face_recog->predict(testpeople2);
// ALOGE("face recongnition 5 .face_testid1 =%d 10. face_testid2 =%d\\n",face_testid1,face_testid2);
// end
// predict method 2
face_recog->predict(imread("face/1.bmp", CV_LOAD_IMAGE_GRAYSCALE),predicted_label,predicted_confidence);
ALOGE("face recongnition face/1.bmp predicted_label =%d predicted_confidence =%8f\\n",predicted_label,predicted_confidence);
face_recog->predict(imread("face/8.bmp", CV_LOAD_IMAGE_GRAYSCALE),predicted_label,predicted_confidence);
ALOGE("face recongnition face/8.bmp predicted_label =%d predicted_confidence =%8f\\n",predicted_label,predicted_confidence);
face_recog->predict(imread("face/3.bmp", CV_LOAD_IMAGE_GRAYSCALE),predicted_label,predicted_confidence);
ALOGE("face recongnition face/3.bmp predicted_label =%d predicted_confidence =%8f\\n",predicted_label,predicted_confidence);
face_recog->predict(testpeople1,predicted_label,predicted_confidence);
ALOGE("face recongnition face/5.bmp predicted_label =%d predicted_confidence =%8f\\n",predicted_label,predicted_confidence);
face_recog->predict(testpeople2,predicted_label,predicted_confidence);
ALOGE("face recongnition face/10.bmp predicted_label =%d predicted_confidence =%8f\\n",predicted_label,predicted_confidence);
// end
string savepath = "face_rec_model.xml";
face_recog->save(savepath);
//=============================reload xml test=====================================
Ptr<FaceRecognizer> face_load = createEigenFaceRecognizer();
ALOGE("face_load recongnition train -the threshold 0 =%8f\\n",face_load->getDouble("threshold"));
face_load->set("threshold", 1500.0f);
ALOGE("face_load recongnition train -the threshold 1 =%8f\\n",face_load->getDouble("threshold"));
face_load->load(savepath);
ALOGE("face_load recongnition train -the threshold 2 =%8f\\n",face_load->getDouble("threshold"));
ALOGE("face recongnition face_reload test 4.bmp id =%d 7.bmp id =%d\\n",face_load->predict(imread("face/4.bmp", CV_LOAD_IMAGE_GRAYSCALE)),face_load->predict(imread("face/7.bmp", CV_LOAD_IMAGE_GRAYSCALE)));
ALOGE("face recongnition face_reload test 10.bmp id =%d 5.bmp id =%d\\n",face_load->predict(imread("face/10.bmp", CV_LOAD_IMAGE_GRAYSCALE)),face_load->predict(imread("face/5.bmp", CV_LOAD_IMAGE_GRAYSCALE)));
// ALOGE("face recongnition face_reload test otherpeople id=%d\\n",face_load->predict(imread("face/03.bmp", CV_LOAD_IMAGE_GRAYSCALE)));
face_load->predict(imread("face/03.bmp", CV_LOAD_IMAGE_GRAYSCALE),predicted_label,predicted_confidence);
ALOGE("face recongnition face/03.bmp - predicted_label =%d predicted_confidence =%8f\\n",predicted_label,predicted_confidence);
return 0;
}
以上是关于OpenCV — 人脸识别的主要内容,如果未能解决你的问题,请参考以下文章