Lucene 6.0 提取新闻热词Top-N
Posted esc_ai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Lucene 6.0 提取新闻热词Top-N相关的知识,希望对你有一定的参考价值。
一、需求
给出一篇新闻文档,统计出现频率最高的有哪些词语。
二、思路
关于文本关键词提取的算法有很多,开源工具也不止一种。这里只介绍如何从Lucene索引中提取词项频率的TopN。索引过程的本质是一个词条化的生存倒排索引的过程,词条化会从文本中去除标点符号、停用词等,最后生成词项。在代码中实现的思路是使用IndexReader的getTermVector获取文档的某一个字段的Terms,从terms中获取tf(term frequency)。拿到词项的tf以后放到map中降序排序,取出Top-N。
三、代码实现
工程目录如下:
关于Lucene 6.0中如何使用IK分词,请参考http://blog.csdn.net/napoay/article/details/51911875。工程里重要的只有2个类,IndexDocs.java和GetTopTerms.java。
3.1索引新闻
在百度新闻上随机找了一篇新闻:李开复:无人驾驶进入黄金时代 AI有巨大投资机会,新闻内容为李开复关于人工智能的主题演讲。把新闻的文本内容放在testfile/news.txt文件中。IndexDocs中的内容:
package lucene.test;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.FieldType;
import org.apache.lucene.index.IndexOptions;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import lucene.ik.IKAnalyzer6x;
public class IndexDocs {
public static void main(String[] args) throws IOException {
File newsfile = new File("testfile/news.txt");
String text1 = textToString(newsfile);
// Analyzer smcAnalyzer = new SmartChineseAnalyzer(true);
Analyzer smcAnalyzer = new IKAnalyzer6x(true);
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(smcAnalyzer);
indexWriterConfig.setOpenMode(OpenMode.CREATE);
// 索引的存储路径
Directory directory = null;
// 索引的增删改由indexWriter创建
IndexWriter indexWriter = null;
directory = FSDirectory.open(Paths.get("indexdir"));
indexWriter = new IndexWriter(directory, indexWriterConfig);
// 新建FieldType,用于指定字段索引时的信息
FieldType type = new FieldType();
// 索引时保存文档、词项频率、位置信息、偏移信息
type.setIndexOptions(IndexOptions.DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS);
type.setStored(true);// 原始字符串全部被保存在索引中
type.setStoreTermVectors(true);// 存储词项量
type.setTokenized(true);// 词条化
Document doc1 = new Document();
Field field1 = new Field("content", text1, type);
doc1.add(field1);
indexWriter.addDocument(doc1);
indexWriter.close();
directory.close();
}
public static String textToString(File file) {
StringBuilder result = new StringBuilder();
try {
BufferedReader br = new BufferedReader(new FileReader(file));// 构造一个BufferedReader类来读取文件
String str = null;
while ((str = br.readLine()) != null) {// 使用readLine方法,一次读一行
result.append(System.lineSeparator() + str);
}
br.close();
} catch (Exception e) {
e.printStackTrace();
}
return result.toString();
}
}
3.2获取热词
package lucene.test;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Terms;
import org.apache.lucene.index.TermsEnum;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.BytesRef;
public class GetTopTerms {
public static void main(String[] args) throws IOException {
//
Directory directory = FSDirectory.open(Paths.get("indexdir"));
IndexReader reader = DirectoryReader.open(directory);
// 因为只索引了一个文档,所以DocID为0,通过getTermVector获取content字段的词项
Terms terms = reader.getTermVector(0, "content");
// 遍历词项
TermsEnum termsEnum = terms.iterator();
BytesRef thisTerm = null;
Map<String, Integer> map = new HashMap<String, Integer>();
while ((thisTerm = termsEnum.next()) != null) {
// 词项
String termText = thisTerm.utf8ToString();
// 通过totalTermFreq()方法获取词项频率
map.put(termText, (int) termsEnum.totalTermFreq());
}
// 按value排序
List<Map.Entry<String, Integer>> sortedMap = new ArrayList<Map.Entry<String, Integer>>(map.entrySet());
Collections.sort(sortedMap, new Comparator<Map.Entry<String, Integer>>() {
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
return (o2.getValue() - o1.getValue());
}
});
// System.out.println(sortedMap);
getTopN(sortedMap, 10);
}
// 获取top-n
public static void getTopN(List<Entry<String, Integer>> sortedMap, int N) {
for (int i = 0; i < N; i++) {
System.out.println(sortedMap.get(i).getKey() + ":" + sortedMap.get(i).getValue());
}
}
}四、结果分析
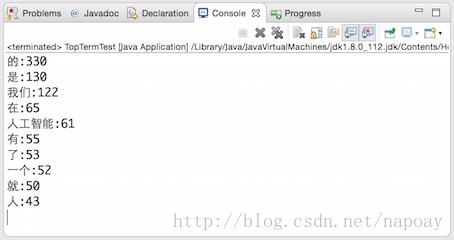
4.1SmartChineseAnalyzer提取结果
第一次的结果是使用Lucene自带的SmartChineseAnalyzer分词得出来的top-10的结果.很显然这个结果并不是我们期待的。
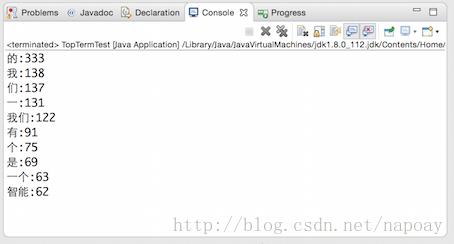
4.2IKAnalyzer提取结果
换成IK分词,结果依然糟糕。问题出在停用词太多,的、是、我、这、了这种词出现频率非常高,但是并没有意义。
4.3Ik+扩展停用词表提取结果
下载哈工大中文停用词词表,加到src/stopword.dic中,重新索引文档,再次运行GetTopTerms.java。结果如下:
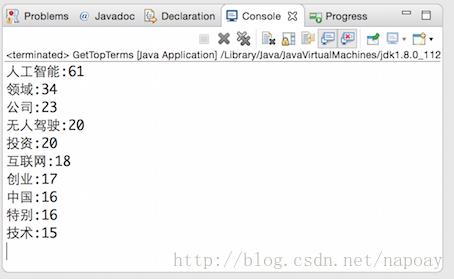
新闻的内容是李开复关于人工智能、无人驾驶、AI的演讲,这次的提取结果比较靠谱。
五、参考文献
1、In lucene 4, IndexReader.getTermVector(docID, fieldName) returns null for every doc
2、Lucene索引过程分析
六、源码
欢迎批评指正。
以上是关于Lucene 6.0 提取新闻热词Top-N的主要内容,如果未能解决你的问题,请参考以下文章