Sigmod Loss 相关总结
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Sigmod Loss 相关总结相关的知识,希望对你有一定的参考价值。
参考技术A 一、sigmoid 函数的应用背景:是起初用于分类的线性模型 (是个通过属性的线性组合来预测的函数[ 每个样本都包含多个属性 ],w权重表达了样本中各个属性在预测中的重要性,b偏置表达了从物理世界到数据表达中存在的不确定性,比如某些噪声无法通过数据表征出来) ,模型的最终目的是为了找到这样的一条直线(平面)将空间中的样本点进行分类。但是获得的直线(平面)上的取值是连续的,并不能对离散的值进行拟合。为解决这个问题就引入了条件概率的使用: :当x取某值时,y=1的概率,概率取值范围是[0,1],概率值是个连续值。 所以可以用线性模型来拟合概率值,但是,概率值的范围是[0,1],而线性模型的结果值是负无穷到正无穷。 所以,就需要有函数将模型的输出值映射在[0,1]范围内。首先,想到的是利用阶跃函数(分段函数),
所以,就有了sigmoid函数的使用。 其数学表达式是: ,【这里就表明了sigmoid函数是直接以模型的输出作为输入变量的】。该函数的曲线图为:
所以,模型的表达式为: 。
存在关系式: ,该比值称为对数几率(log odds,logit)该几率反映了样本为正例的相对可能性。从该关系式可以看出,逻辑回归的本质是用线性回归的预测结果去逼近真实标记的对数几率。
好处:不仅预测出了类别 ,也表示出来属于该类别的概率,有利于利用概率来辅助决策。
二、sigmoid 损失函数的使用:
sigmoid 属于逻辑损失函数的一种,适用于 二分类 任务中,需要满足假设之一:数据满足伯努利分布。
logical 函数 也叫作 sigmoid 函数
表示将样本预测为正类的概率,1- 将样本预测为负类的概率,整个模型可以表示为: ,其中, ,(θ是权重,x是输入变量,该指数代表模型的输出),最后得到逻辑回归的最终表达式。
逻辑回归的损失函数,是其极大似然函数:
由一可知: ,则 ,所以似然函数为: ,使用负对数似然函数作为模型的损失函数(为了好计算但式子性质不变):
在模型训练时,需要对该loss函数求梯度(就是对权重W求导),就是按照函数求偏导的方法对该loss进行求导,最终结果为:
接着就使用梯度下降法,对网路参数进行更新,求得最优参数解。
区块链论文整理SIGMOD篇
SIGMOD(Special Interest Group On Management Of Data)是数据库三大顶会之一,近几年也发表了不少水平很高的文章。本文主要针对SIGMOD会议中区块链相关的论文进行简单整理。
ACM SIGMOD Conference 2021: Virtual Event, China
- SharPer: Sharding Permissioned Blockchains Over Network Clusters.
- Permissioned Blockchains: Properties, Techniques and Applications
- Why Do My Blockchain Transactions Fail?: A Study of Hyperledger Fabric.
- Do the Rich Get Richer? Fairness Analysis for Blockchain Incentives
- Blockchains vs. Distributed Databases: Dichotomy and Fusion.
- DIV: Resolving the Dynamic Issues of Zero-knowledge Set Membership Proof in the Blockchain.
- P2B-Trace: Privacy-Preserving Blockchain-based Contact Tracing to Combat Pandemics
- A Byzantine Fault Tolerant Storage for Permissioned Blockchain
SIGMOD Conference 2020: Virtual Event / Portland, OR, USA
- A Transactional Perspective on Execute-order-validate Blockchains.
- FalconDB: Blockchain-based Collaborative Database.
- Confidentiality Support over Financial Grade Consortium Blockchain.
- vChain: A Blockchain System Ensuring Query Integrity.
SIGMOD Conference 2019: Amsterdam, The Netherlands
- Blurring the Lines between Blockchains and Database Systems: the Case of Hyperledger Fabric.
- Towards Scaling Blockchain Systems via Sharding.
- vChain: Enabling Verifiable Boolean Range Queries over Blockchain Databases.
- State of Public and Private Blockchains: Myths and Reality.
- Database and Distributed Computing Foundations of Blockchains.
- BlockchainDB - Towards a Shared Database on Blockchains
- Fluid: A Blockchain based Framework for Crowdsourcing
计划分三篇文章进行整理,本篇为2021年的8篇论文
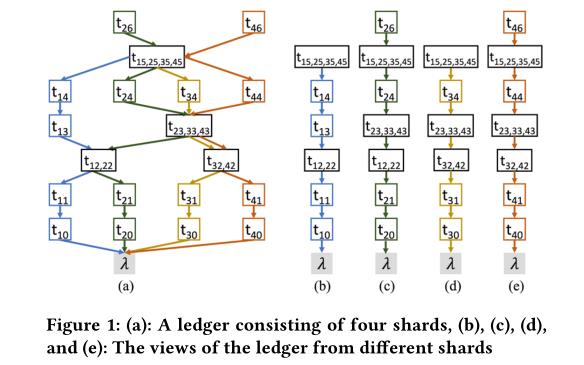
1 SharPer: Sharding Permissioned Blockchains Over Network Clusters

第一作者是Mohammad Javad Amiri来自宾夕法尼亚大学,第二作者和第三作者都来自加州大学圣塔芭芭拉分校(Divyakant Agrawal和Amr El Abbadi)。 他们也是《On Sharding Permissioned Blockchains》的作者。
类别:使用分片技术解决可扩展性问题。
摘要:可扩展性是商业采用区块链系统的主要障碍之一。尽管最近对使用分片技术来增强区块链系统的可伸缩性进行了深入研究,但现有的解决方案并不能有效地解决跨分片交易。在本文中,我们将介绍SharPer,一个可扩展的许可区块链系统。在SharPer中,节点被集群化,每个数据碎片被复制到集群的节点上。SharPer支持由仅崩溃节点或拜占庭节点组成的网络。在SharPer中,区块链分类账形成为一个有向无环图,每个集群只维护分类账的一个视图。SharPer采用分散的扁平协议来建立跨碎片共识。在SharPer中,交叉碎片共识的分散性使得能够使用非重叠集群并行处理事务。此外,SharPer提供确定性安全保证。实验结果揭示了SharPer在性能和可伸缩性方面的效率,尤其是在跨切分事务百分比较低的工作负载中。
主要贡献点:
-
SharPer是一个经过许可的区块链系统,通过将节点聚集到集群中,并对数据和账本进行分片,支持交易的并发处理。SharPer支持片内和片间事务。
-
在由纯崩溃节点或拜占庭节点组成的网络中,两个分散的扁平共识协议用于在所有且仅涉及的集群之间排序跨碎片事务。这些协议在没有重叠集群的情况下并行排列跨碎片事务。
Sharper架构:
2 Permissioned Blockchains: Properties, Techniques and Applications

作者和上一篇文章一样。
类别:关于许可区块链的教程(Tutorial)。
摘要:区块链的独特功能(如不变性、透明度、来源和真实性)已被许多大型数据管理系统用于部署广泛的分布式应用程序,包括供应链管理、医疗保健和许可环境下的众包。与无许可设置(如比特币)不同,比特币网络是公共的,任何人都可以在没有特定身份的情况下参与,许可区块链系统由一组已知的、已识别的节点组成,这些节点可能彼此不完全信任。虽然许可区块链的特征吸引了大量大规模数据管理系统,但这些系统必须满足四个主要要求:机密性、可验证性、性能和可伸缩性。为了满足这些要求,工业界和学术界已经开发了各种方法,但假设和成本各不相同。本教程的重点是介绍其中的许多技术,同时强调它们之间的权衡。我们通过展示三种不同的应用,即供应链管理、大型数据库和多平台众工环境,展示了这些技术在现实生活中的实用性,并展示了如何利用这些技术来满足这些应用的需求。
主要内容:2.3小节讲述了解决机密性、可验证性、性能和可伸缩性四个主要需求的相关技术。
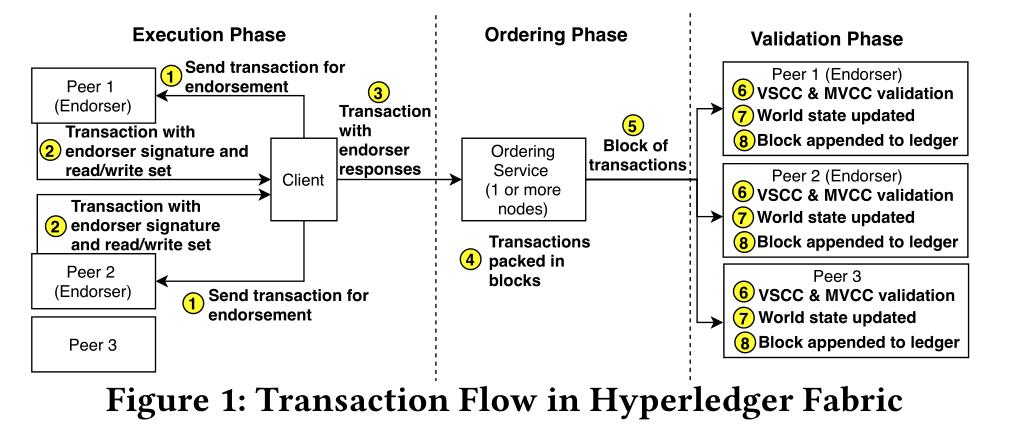
3 Why Do My Blockchain Transactions Fail?: A Study of Hyperledger Fabric.

类别: 对Hyperledger Fbric 的性能优研究。
摘要:许可区块链系统承诺提供分散的信任和隐私。Hyperledger Fabric是目前应用最广泛的许可区块链系统之一,在工业界和学术界都得到了大力推广。由于其乐观并发模型,Fabric中的事务失败率可能成为瓶颈。虽然有减少故障的积极研究,但对其根本原因缺乏了解,因此,对于如何为不同场景优化配置结构缺乏指导。为了弥补这一差距,在本文中,我们首先介绍了Fabric中不同类型事务失败的正式定义。然后,我们开发了一个全面的测试平台和基准测试系统HyperLedgerLab,以及四个不同的链码,它们代表了真实的用例和一个链码/工作负载生成器。使用HyperLedgerLab,我们进行了详尽的实验,以分析结构的不同参数(如块大小、背书策略等)对事务失败的影响。我们进一步分析了文献中最近提出的三种优化,Fabric++、Streamchain和FabricSharp,并评估了它们在哪些条件下降低了故障率。最后,基于我们的研究结果,我们为 Fbric 从业者提供了如何配置系统的建议,并提出了新的研究方向。
主要贡献点:
- 我们正式定义了不同类型的并发相关事务失败,以便为我们的研究和进一步的研究奠定坚实的基础。
-
我们广泛研究了影响Fabric中不同事务失败的各种参数,以及三种最新的优化技术,Fabric++[44]、Streamchain[24]和FabricSharp[43]。我们的研究揭示了关于Fabric结构的惊人见解和权衡。例如,在不同的事务到达率下,数据块大小对事务失败的数量有很大的影响——如果数据块大小合适,事务失败最多可以减少60%。
-
为了进行真实的评估和控制实验,我们开发了一个新的试验台,该试验台集成了卡尺基准测试系统的扩展HyperLedgerLab[23],其中包括四个代表真实用例的新智能合约,以及一个链码和工作负载生成器。我们将HyperLedgerLab以及所有链码和生成器作为一个开源项目发布,以便其他研究人员可以从中受益,并以公平的方式比较他们的工作。
-
我们为Fabric开发人员确定最佳实践和原则,并得出科学界未来可以追求的有希望的研究方向。
Hyperledger Fabric 交易流程:
4 Do the Rich Get Richer? Fairness Analysis for Blockchain Incentives

类别:激励模型的公平性(PoW,PoS)
摘要:工作证明(PoW)是当前区块链系统中最广泛采用的激励模式,但不幸的是,这种模式的能源效率低下。然后提出了权益证明(PoS)来解决能源问题。区块链社区对PoS的“富人越来越富”问题进行了激烈讨论。争论的焦点是,持有更多股份的富裕矿工是否会获得更高的赌注回报,并进一步增加他们未来的潜在收入。在本文中,我们定义了两种类型的公平性,即期望公平性和鲁棒公平性,它们有助于回答这个问题。特别是,预期公平性表明,矿工的预期收入与其初始投资成正比,表明预期投资回报率是一个常数。为了更好地捕捉采矿结果的不确定性,提出了稳健公平性来表征投资回报率是否随着时间的推移以高概率集中到一个常数。我们的分析表明,只要挖掘游戏运行足够长的时间,经典的PoW机制总能保持这两种类型的公平性。此外,我们观察到当前的PoS区块链实施了各种激励模型,并讨论了三种代表,即ML-PoS、SL-PoS和C-PoS。我们发现(i)ML-PoS(如Qtum和Blackcoin)保留了预期公平性,但可能无法实现稳健公平性,(ii)SL-PoS(如NXT)不保护任何类型的公平性,(iii)C-PoS(如以太坊2.0)在保持预期公平性的同时,在稳健公平性方面优于ML-PoS。最后,我们在真实区块链系统上进行了大量实验,并进行了大量数值模拟,以验证我们的分析。
主要贡献点:
-
我们为区块链激励提出了两种类型的公平性,即预期公平性和稳健公平性,以描述矿工控制的资源与她从采矿游戏中获得的奖励之间的关系。
-
我们对最广泛采用的PoW激励协议和三种流行的PoS激励协议的公平性进行了深入的理论分析。在公平性方面,这些协议通常按以下降序排列:PoW、C-PoS、ML-PoS和SL-PoS。
-
我们在真实区块链系统上进行了大量实验,并进行了数值模拟,以评估不同激励协议的公平性。实验结果证实了我们的理论发现,并为公平激励协议的未来发展提供了启示。
5 Blockchains vs. Distributed Databases: Dichotomy and Fusion

类别:
摘要:区块链已经走了很长一段路——一个最初专门为加密货币提出的系统现在正在被改造和采用,作为一个通用交易系统。随着区块链演变成另一个数据管理系统,自然的问题是它与分布式数据库系统相比如何。关于这种比较的现有工作主要关注高级属性,例如安全性和吞吐量。它们没有显示出基本的设计选择是如何导致整体差异的。我们的工作填补了这一重要空白,并为分析区块链数据库融合的新兴趋势提供了一个原则框架。
我们对区块链和分布式数据库系统作为两种类型的事务系统进行了双重研究。我们提出了一种分类法,该分类法展示了复制、并发、存储和分片这四个维度上的二分法。在每个维度中,我们讨论了设计选择是如何由两个目标驱动的:区块链的安全性和分布式数据库的性能。为了揭示不同设计选择对整体性能的影响,我们对两个区块链(即Quorum和Hyperledger Fabric)以及两个分布式数据库(即TiDB和etcd)进行了深入的性能分析。最后,我们提出了一个区块链数据库混合系统封底性能预测框架。
主要贡献:
-
我们将区块链和分布式数据库作为两种不同类型的分布式事务系统进行比较。我们提出了一种新的分类法,它沿着四个设计维度来描述这两种类型的系统及其混合体:复制、并发、存储和分片。
-
我们对四个流行系统进行了全面的性能研究,包括两个许可区块链,即Fabric和Quorum,以及两个数据库系统,即TiDB和etcd。结果显示了不同设计选择对性能的影响。
-
我们使用我们的分类法来分析新兴混合区块链数据库系统的安全性和性能。我们提出了一个框架来解释它们的性能差异,并估计未来混合系统的性能。
研究内容:


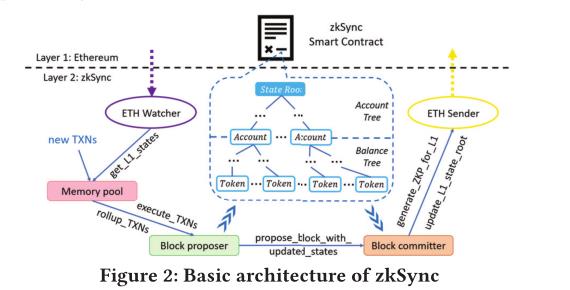
6 DIV: Resolving the Dynamic Issues of Zero-knowledge Set Membership Proof in the Blockchain.

类别:成员身份动态控制。
摘要:零知识集成员身份(ZKSM)证明在区块链中被广泛用于实现私有成员身份认证。然而,现有机制没有充分考虑区块链场景中的动态问题。特别是,频繁添加/删除集合元素,不仅会给验证者和验证者带来保持公共参数最新的巨大成本,还会影响机制效率(例如,验证和验证的生成时间等)。
在本文中,我们建议将区块链上的元素分割成具有相同基数的独立子集,以减少动态问题的影响。然而,由于验证频率不同,不正确的元素集分配可能会导致频繁使用的元素容易被推断和损坏。因此,我们将元素添加和移除情况下的分配问题形式化为两个优化问题,并证明了它们的NP困难性。对于每个问题,我们考虑两种情况,即集合维护者是否提前知道每个元素的证明频率,并提出具有理论保证的解决方案。我们在Merkle树和基于RSA的ZKSM机制上实现了DIV,以评估其效率和有效性,并将DIV应用于基于ZKSM的应用程序zkSync,以证明其适用性。结果表明,在动态情况下,DIV可以在ZKSM上实现O(1)时间/空间开销,同时保护常用元素的信息。它还显著减少了zkSync的系统延迟。
主要贡献:
- 我们建议DIV在区块链场景中扩展零知识集成员证明。
-
我们定义了两个优化问题,以获得一个平衡元素集分配,在两个动态情况下暴露元素证明频率的最小信息,并证明了它们的NP难度。
-
对于每一个问题,我们设计的算法都有一个常数近似界,适用于集合维护者已知或不知道元素验证频率的两种情况。
-
我们在Merkle树和基于RSA的ZKSM机制以及基于ZKSM的应用程序zkSync上实现了DIV,并进行了大量实验。结果表明,DIV能够解决动态问题,并适用于实际应用,以减少ZKSM带来的延迟。同时,每一组使用频率的最大完工时间是有界的。
DIV 架构:

7 P2B-Trace: Privacy-Preserving Blockchain-based Contact Tracing to Combat Pandemics

类别:联系人追踪,保护隐私。
摘要:2019冠状病毒疾病等大流行的爆发可能会引发前所未有的全球危机。几十年来,接触者追踪作为公共卫生中传染病控制的一个支柱,已显示出其在大流行控制方面的有效性。尽管对联系人追踪进行了深入研究,但现有的方案很容易受到攻击,很难同时满足数据完整性和用户隐私的要求。为确保追踪程序的完整性而设计的隐私保护联系人追踪框架尚未得到充分研究,仍然是一个挑战。在本文中,我们提出了基于区块链的隐私保护联系人追踪计划P2B Trace。首先,我们设计了一个带有区块链的分散式体系结构,以记录用户联系人记录的经过身份验证的数据结构,从而防止用户在事后有意修改其本地记录。其次,我们开发了一个零知识邻近性验证方案,在保护用户隐私的同时进一步验证用户的邻近性声明。我们实现了P2B跟踪,并进行了实验来评估隐私保护跟踪完整性验证的成本。评估结果证明了我们提出的系统的有效性。
主要贡献点:
- 我们设计了一个带有区块链的分散式体系结构,以记录用户联系人记录的经过身份验证的数据结构(ADS),从而防止用户在事后有意修改其记录。此外,我们开发了一个零知识邻近性验证方案,在保护用户隐私的同时验证用户的邻近性声明。
-
我们使用现成的基础设施原语实现P2B跟踪,以证明其实用性。实验结果表明,P2B跟踪以分散的方式实现了一个可验证和私有化的接触跟踪系统。此外,证据生成时间和验证时间被确定为隐私保护的成本关键部分。
-
我们将讨论基于区块链的联系人追踪应用程序在数据管理方面的未来研究方向和挑战。本文还提出了一些可能的解决方案。
P2B 架构:


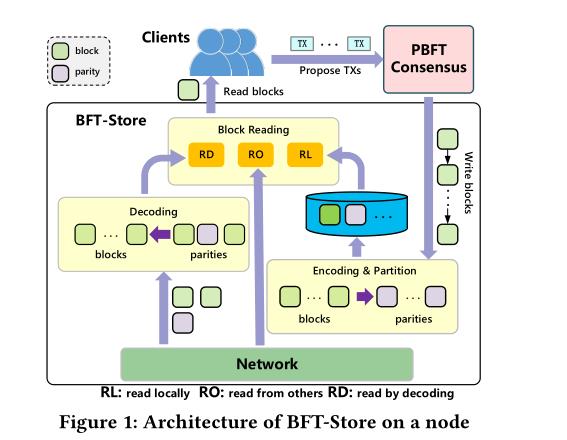
8 A Byzantine Fault Tolerant Storage for Permissioned Blockchain

类别: 使用拜占庭容错共识解决存储问题。(demo演示)
摘要:现有区块链中常用的完全复制数据存储机制的可伸缩性较差,因为它要求每个节点在本地保留整个区块数据的完整副本,以容忍潜在的拜占庭式故障。在恶意环境中,恶意节点可能会故意丢弃或篡改数据。因此,现有的分布式存储方法将数据划分为多个部分,并将其分布在所有节点上,无法适用于区块链。本演示展示了BFTStore,一种新型的分布式存储引擎,用于区块链,通过将擦除编码与拜占庭容错(BFT)共识协议相结合来打破完全复制。本演示将(i)让观众成员了解BFT如何在所有节点上存储分区块数据,以减少系统的存储占用;(ii)让观众成员了解BFT Store如何在分布式场景下恢复块,即使在拜占庭故障的情况下。
主要贡献:
框架:
以上是关于Sigmod Loss 相关总结的主要内容,如果未能解决你的问题,请参考以下文章
vChain: Enabling Verifiable Boolean Range Queries over Blockchain Databases(sigmod‘2019)
区块链相关论文研读3- 关于超级账本Hyperledger Fabric的性能优化