SolrCloud今日大纲
Posted beyondcj
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SolrCloud今日大纲相关的知识,希望对你有一定的参考价值。
SolrCloud今日大纲(了解)
● 分布式集群系统基本概念
● SolrCloud入门
● SolrCloud搭建
*****************************************************************************************************
1. 分布式集群系统基本概念介绍
1.1 单台服务器存在的问题
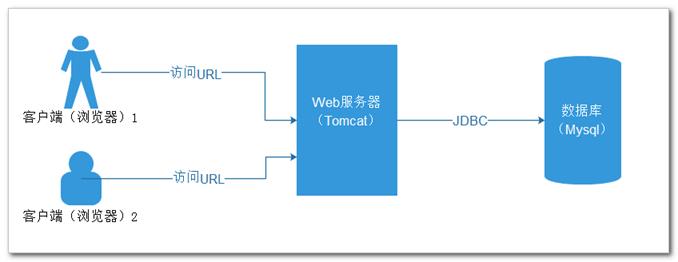
URL:
localhost其实就是127.0.0.1,作用是找到对应的服务器,对大家以前来说就是自己本机
8080:通过8080端口可以找到某台服务器上的web服务器软件(web容器),对大家以前来说就是自己本机上的Tomcat
xxx:代表项目程序的部署名称,通过该名字可以找到Tomcat中部署的具体项目
问题:
1、高并发:海量用户同时进行访问。
2、大数据:如果存在海量数据进行传输与存储。
3、单点故障:服务器或者web服务器出现故障。
*****************************************************************************************************
1.2 集群和分布式
1.2.1 集群简介
集群是是指将多台服务器集中在一起,每台服务器都实现相同的业务,做相同的事情。但是每台服务器并不是缺一不可,存在的作用主要是缓解并发压力和单点故障转移问题。
比如:我们一起去修楼房,我搬砖,你也搬砖,我们缓解了有很多砖要搬的压力,提高了效率。同时,我们并不是缺一不可,如果我出故障,不干了,你还是可以继续搬砖,工程依旧可以继续进行,只是效率会低点。
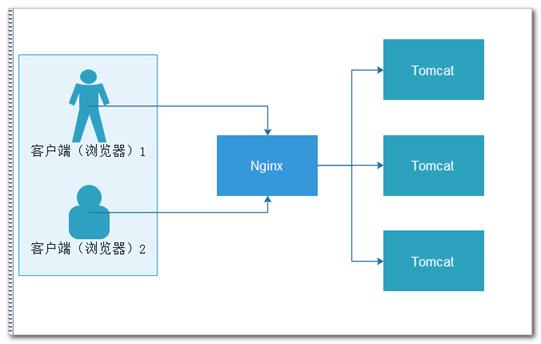
注意:该图中最大的特点就是,每个Tomcat都完成相同的业务,但是分担着不同用户的访问,它们并不是缺一不可,如果一个Tomcat出现故障,网站依旧可以运行。
集群种类:
1、高可用集群(High Availability 简称HA cluster):此类集群实现的功能是保障用户的应用程序持久、不间断地提供服务。
2、负载均衡集群:负载均衡集群可以把一个高负荷的应用分散到多个节点共同完成,适用于业务繁忙、大负荷访问的应用系统。
3、科学计算集群(HPC集群):这类集群致力于提供单个计算机所不能提供的强大计算能力,包括数值计算和数据处理,并且倾向于追求综合性能。
1.2.2 分布式简介
分布式是指将多台服务器集中在一起,每台服务器都实现总体中的不同业务,做不同的事情。并且每台服务器都缺一不可,如果某台服务器故障,则网站部分功能缺失,或导致整体无法运行。存在的主要作用是大幅度的提高效率,缓解服务器的访问和存储压力。
比如:我们一起去修楼房,我搬砖,你砌墙,我们共同完成这一伟大的工程。但是,我们缺一不可,如果我出故障,不搬砖了,你也无法砌墙了。
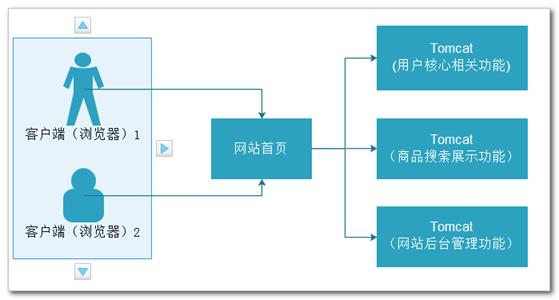
注意:该图中最大特点是:每个Web服务器(Tomcat)程序都负责一个网站中不同的功能,缺一不可。如果某台服务器故障,则对应的网站功能缺失,也可以导致其依赖功能甚至全部功能不能够使用。
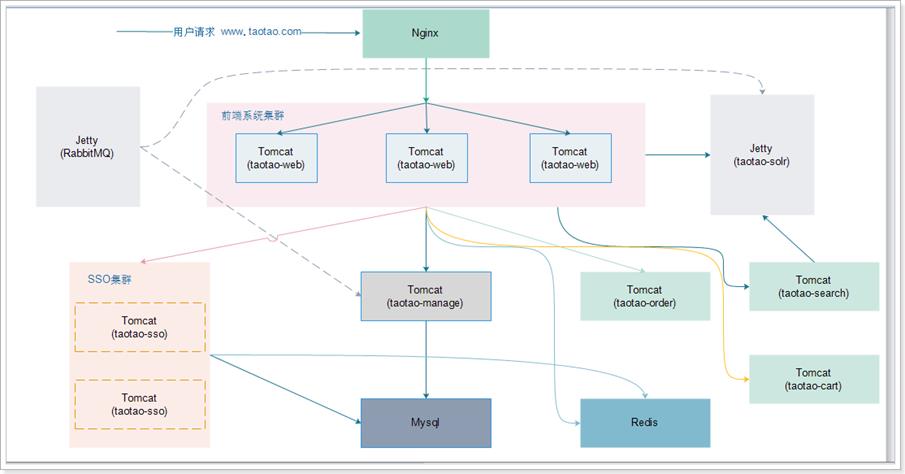
1.2.3 分布式集群综合架构
一般分布式中的每一个节点,都可以做集群。这样的系统架构,我们通常称为分布式集群架构。
*****************************************************************************************************
1.3 代理技术
1.3.1 正向代理(Forward Proxy)
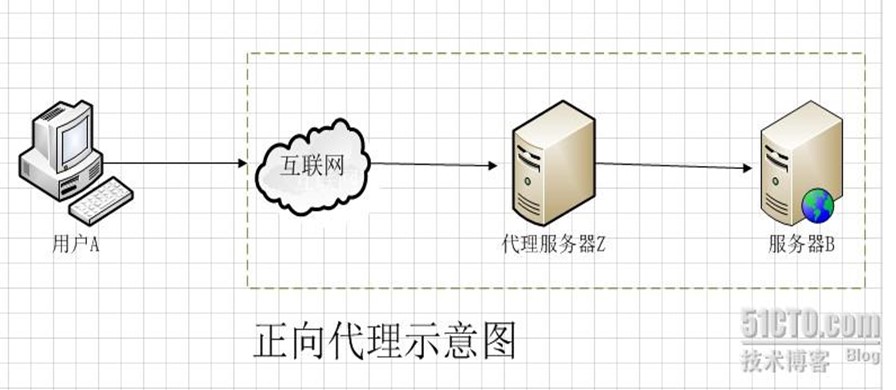
一般情况下,如果没有特别说明,代理技术默认说的是正向代理技术。关于正向代理的概念如下: 正向代理(forward)是一个位于客户端【用户A】和原始服务器(origin server)【服务器B】之间的服务器【代理服务器Z】,为了从原始服务器取得内容,用户A向代理服务器Z发送一个请求并指定目标(服务器B),然后代理服务器Z向服务器B转交请求并将获得的内容返回给客户端。客户端必须要进行一些特别的设置才能使用正向代理。
简单来说,正向代理就是代理服务器替代访问方【用户A】去访问目标服务器【服务器B】
为什么需要使用正向代理?
1、访问本无法访问的服务器B
2、加速访问服务器B
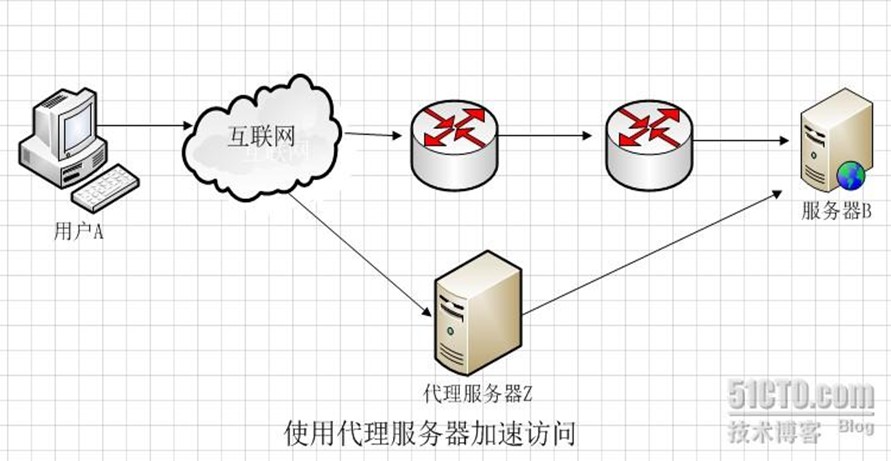
3、Cache作用
如果在用户A访问服务器B某数据J之前,已经有人通过代理服务器Z访问过服务器B上得数据J,那么代理服务器Z会把数据J保存一段时间,如果有人正好取该数据J,那么代理服务器Z不再访问服务器B,而把缓存的数据J直接发给用户A。
4、客户端访问授权
5、隐藏访问者的行踪
服务器B并不知道访问自己的实际是用户A,因为代理服务器Z代替用户A去直接与服务器B进行交互。如果代理服务器Z被用户A完全控制(或不完全控制),会惯以"肉鸡"术语称呼。
1.3.2 反向代理(reverse proxy)
反向代理正好与正向代理相反,对于客户端而言代理服务器就像是原始服务器,并且客户端不需要进行任何特别的设置。客户端向反向代理的命名空间(name-space)中的内容发送普通请求,接着反向代理将判断向何处(原始服务器)转交请求,并将获得的内容返回给客户端。 使用反向代理服务器的作用如下:
1、保护和隐藏原始资源服务器
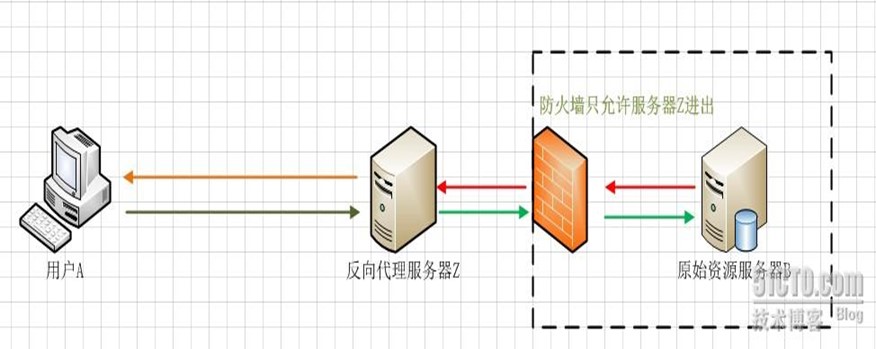
用户A始终认为它访问的是原始服务器B而不是代理服务器Z,但实用际上反向代理服务器接受用户A的应答,从原始资源服务器B中取得用户A的需求资源,然后发送给用户A。由于防火墙的作用,只允许代理服务器Z访问原始资源服务器B。在这个虚拟的环境下,防火墙和反向代理的共同作用保护了原始资源服务器B,但用户A并不知情。
2、负载均衡
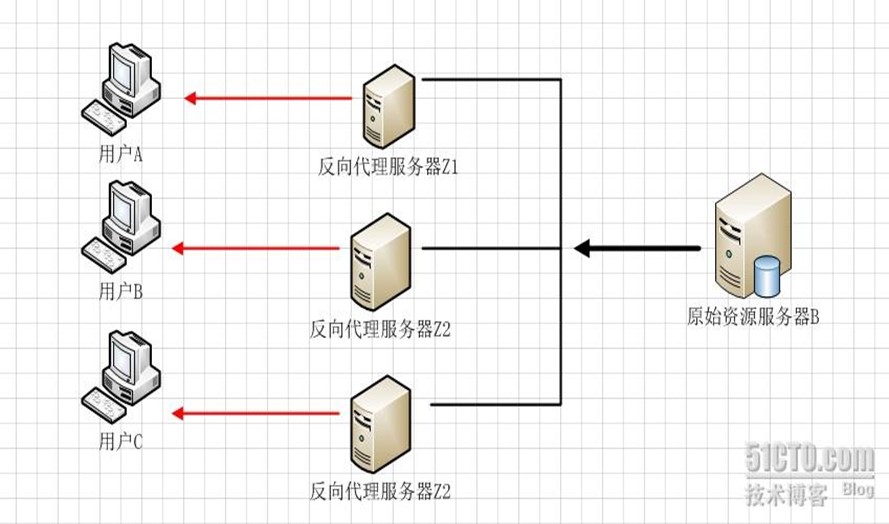
当反向代理服务器不止一个的时候,我们甚至可以把它们做成集群,当更多的用户访问资源服务器B的时候,让不同的代理服务器Z(x)去应答不同的用户,然后发送不同用户需要的资源。
而且反向代理服务器像正向代理服务器一样拥有CACHE的作用,它可以缓存原始资源服务器B的资源,而不是每次都要向原始资源服务器B请求数据,特别是一些静态的数据,比如图片和文件。
简单来说,反向代理就是反向代理服务器替代原始服务器【服务器B】让【用户A】去访问
*****************************************************************************************************
1.4 分布式协调服务
分布式协调服务是集群分布式中大管家
Zookeeper 是google的chubby一个开源实现,是Hadoop的分布式协调服务。分布式应用程序可以基于它实现同步服务,配置维护和命名服务等。并且可以用来保证数据在zk(Zookeeper)集群之间的数据的事物性一致。
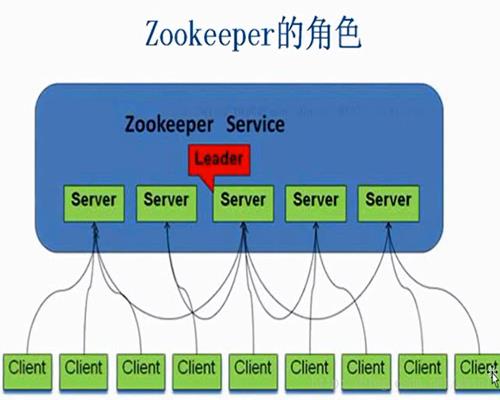
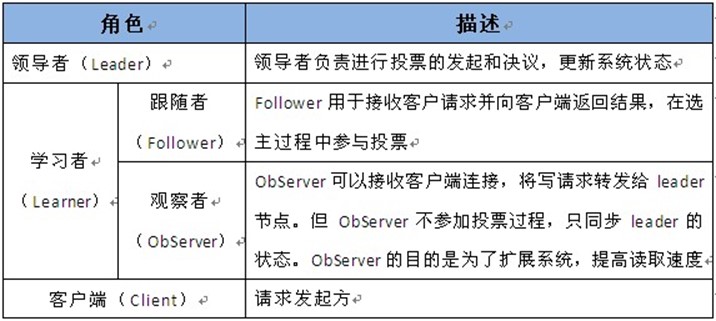
特点:统一管理、合理分工、数据共享、实时同步、心跳检测、主从备份、故障恢复
*****************************************************************************************************
2. SolrCloud入门
2.1 SolrCloud简介
SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud。当一个系统的索引数据量少的时候是不需要使用SolrCloud,当索引量很大,搜索请求并发很高,这时需要使用SolrCloud来满足这些需求。
负载均衡、数据分片,数据备份
*****************************************************************************************************
2.2 SolrCloud结构简介
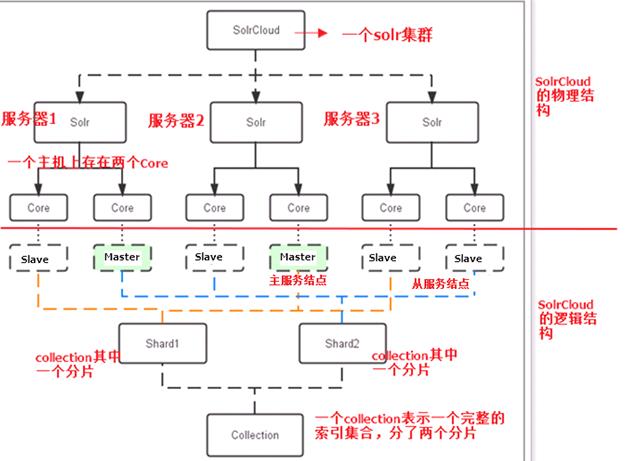
SolrCloud为了降低单机的处理压力,需要由多台服务器共同来完成索引和搜索任务。实现的思路是将索引数据进行Shard(分片)拆分,每个分片由多台的服务器共同完成,当一个索引或搜索请求过来时会分别从不同的Shard的服务器中操作索引。
SolrCloud需要Solr基于Zookeeper部署,Zookeeper是一个集群管理软件,由于SolrCloud需要由多台服务器组成,由zookeeper来进行协调管理。
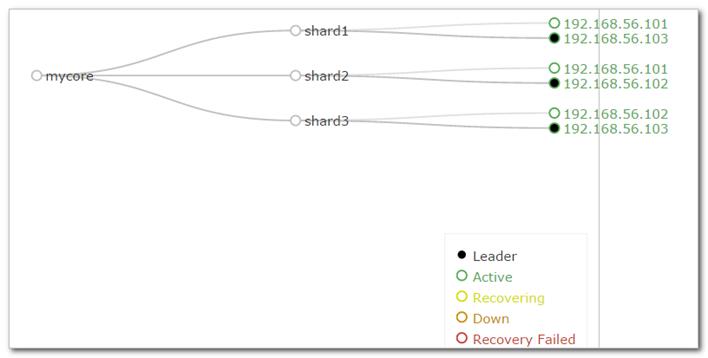
下图是一个SolrCloud应用的例子:
*****************************************************************************************************
2.3 物理结构
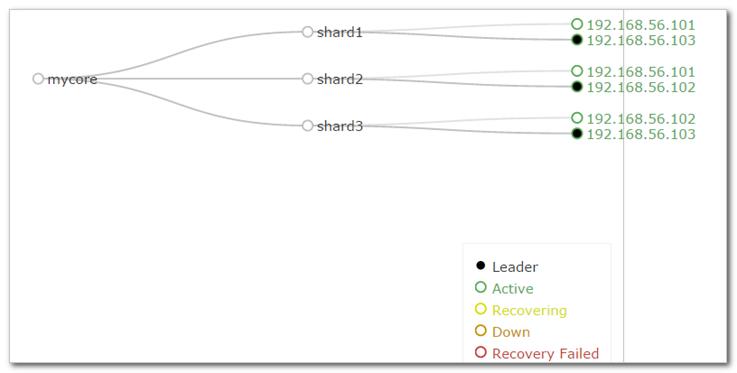
将总的数据分成3份(这3份中的数据都不一样),并备份一份。
主数据: shard1、 shard2、 shard3
备份数据: shard1、 shard2、 shard3
理论上产生的后果:
原数据总量为X
现数据总量为2X
数据总容量浪费一倍
单台机原数据量为:X
现数据量为:(X/3)*2
单台机容量节省1/3
原负载带宽为:Y
现在负责带宽为:Y/3
负载带宽节省2/3
一台机器故障不会影响使用
*****************************************************************************************************
2.4 逻辑结构
索引集合(core)包括两个Shard(shard1和shard2),shard1和shard2分别由三个Core组成,其中一个Leader两个Replication,Leader是由zookeeper选举产生,zookeeper控制每个shard上三个Core的索引数据一致,解决高可用问题。
用户发起索引请求分别从shard1和shard2上获取,解决高并发问题。
collection
Collection在SolrCloud集群中是一个逻辑意义上的完整的索引结构。它常常被划分为一个或多个Shard(分片),它们使用相同的配置信息。
比如:针对商品信息搜索可以创建一个collection。
collection=shard1+shard2+....+shardX
2.4.1 Core
每个Core是Solr中一个独立运行单位,提供索引和搜索服务。一个shard需要由一个Core或多个Core组成。由于collection由多个shard组成所以collection一般由多个core组成。
2.4.2 Master或Slave
Master是master-slave结构中的主结点,Slave是master-slave结构中的从结点。同一个Shard下master和slave存储的数据是一致的,这是为了达到高可用目的。
主从备份
主从读写分离
2.4.3 Shard
Collection的逻辑分片。每个Shard被化成一个或者多个replication,通过选举确定哪个是Leader。
分片有两种:
一个是Leader (主数据)
一个是replication (备份数据)
作用其实不光是用作备份,还可以用作读写分离.......。
*****************************************************************************************************
3. SolrCloud搭建
3.1 环境准备
软件部分:
jdk-7u71-linux-x64.tar.gz
apache-tomcat-7.0.57.tar.gz
zookeeper-3.4.5.tar.gz
solr-4.10.2.tgz
服务器部分:
zookeeper三台: 192.168.56.101, 192.168.56.102, 192.168.56.103
Solr三台: 192.168.56.101, 192.168.56.102, 192.168.56.103
每台机器上都部署一个solr和zookeeper
*****************************************************************************************************
3.2 基本软件安装:
3.2.1 CentOs 6.5安装
3.2.2 jdk7安装
3.2.3 tomcat安装
*****************************************************************************************************
3.3 solr单机部署
3.3.1 上传solr安装包
3.3.2 解压
tar -zxvf solr-4.10.2.tgz
3.3.3 部署solr.war
1、将solr.war拷贝到tomcat的webapp目录:
cp /usr/local/mao/solr-4.10.2/example/webapps/solr.war /usr/local/mao/apache-tomcat-7.0.57/webapps/
2、解压war包也可以启动tomcat直接解压缩
unzip -oq solr.war -d solr
3、上传依赖包到solr项目的lib下:
《solr在tomcat运行需要导入的jar包》文件夹
4、修改tomcat的bin中的配置文件catalina.sh,加入
export JAVA_OPTS=-Dsolr.solr.home=/usr/local/mao/solr-4.10.2/example/solr
/usr/local/mao/solr-4.10.2/example/solr 是solr默认自带的索引库例子
*****************************************************************************************************
3.4 zookeeper集群安装
1、解压zookeeper:
tar -zxvf zookeeper-3.4.5.tar.gz
2、修改zookeeper配置文件:
(1)、进入zookeeper的conf目录
(2)、根据模版复制配置文件: cp zoo_sample.cfg zoo.cfg
(3)、zoo.cfg添加如下内容:
dataDir=/usr/local/mao/zookeeper-3.4.5/data
dataLogDir=/usr/local/mao/zookeeper-3.4.5/log
server.1=192.168.56.101:2888:3888
server.2=192.168.56.102:2888:3888
server.3=192.168.56.103:2888:3888
注意要删除模版中的dataDir(切记)

3、在zookeeper根目录下创建data目录和log目录
mkdir data
mkdir log
chmod 755 data
chmod 755 log
4、在data目录中添加myid文件:
vi myid
并填写如下内容
1
5、zookeeper常用命令:
启动zookeeper: ./zkServer.sh start
停止zookeeper: ./zkServer.sh stop
查看状态: ./zkServer.sh status
6、如果出现错误:
先stop 掉原zk
zkServer.sh stop
然后以./zkServer.sh start-foreground方式启动,会看到启动日志
zkServer.sh start-foreground
3.4 复制N台虚拟机(也可以单独安装)
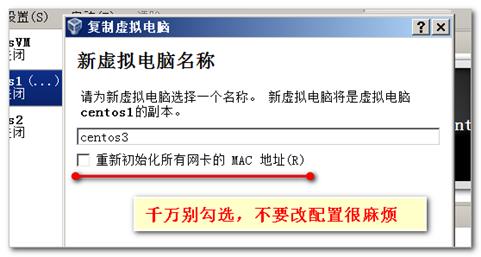
同时将每台虚拟机的静态ip设置为:
101、102、103
建议最好hostname也改成centos1 centos2 centos3
对另外两台虚拟机中的zookeeper的myid文件进行更改:
分别改为:
2
3
*****************************************************************************************************
3.4 solr集群部署
启动zookeeper
zookeeper服务器端常用命令:
启动zookeeper: ./zkServer.sh start
停止zookeeper: ./zkServer.sh stop
查看状态: ./zkServer.sh status
zookeeper客户端命令
ZooKeeper命令行工具类似于Linux的shell环境,不过功能肯定不及shell啦,但是使用它我们可以简单的对ZooKeeper进行访问,数据创建,数据修改等操作. 使用 zkCli.sh -server 127.0.0.1:2181 连接到 ZooKeeper 服务,连接成功后,系统会输出 ZooKeeper 的相关环境以及配置信息。
命令行工具的一些简单操作如下:
1. 显示根目录下、文件: ls / 使用 ls 命令来查看当前 ZooKeeper 中所包含的内容
2. 显示根目录下、文件: ls2 / 查看当前节点数据并能看到更新次数等数据
3. 创建文件,并设置初始内容: create /zk "test" 创建一个新的 znode节点" zk "以及与它关联的字符串
4. 获取文件内容: get /zk 确认 znode 是否包含我们所创建的字符串
5. 修改文件内容: set /zk "zkbak" 对 zk 所关联的字符串进行设置
6. 删除文件: delete /zk 将刚才创建的 znode 删除
7. 退出客户端: quit
8. 帮助命令: help
3.4.3 zookeeper管理配置文件
由于zookeeper统一管理solr的配置文件(主要是schema.xml、solrconfig.xml), solrCloud各各节点使用zookeeper管理的配置文件。以后无论创建任何的core,本地的配置文件都没用了,使用的都是zookeeper的配置文件
执行下边的命令将/usr/local/mao/solr-4.10.2/example/solr/collection1/conf/下的配置文件上传到zookeeper:
sh /usr/local/mao/solr-4.10.2/example/scripts/cloud-scripts/zkcli.sh -zkhost 192.168.56.101:2181,192.168.56.102:2181,192.168.56.103:2181 -cmd upconfig -confdir /usr/local/mao/solr-4.10.2/example/solr/collection1/conf/ -confname solrconf
sh /home/solr/solr-4.10.2/example/scripts/cloud-scripts/zkcli.sh -zkhost
192.168.111.130:2181,192.168.111.131:2181,192.168.111.132:2181 -cmd upconfig -confdir
/home/solr/solr-4.10.2/example/solr/collection1/conf -confname solrconf
3.4.4 修改SolrCloud监控端口为8080
/usr/local/mao/solr-4.10.2/example/solr

<solrcloud>
<str name="host">${host:}</str>
<int name="hostPort">${jetty.port:8983}</int>
<str name="hostContext">${hostContext:solr}</str>
<int name="zkClientTimeout">${zkClientTimeout:30000}</int>
<bool name="genericCoreNodeNames">${genericCoreNodeNames:true}</bool>
</solrcloud>
三台机器都要改
3.4.5 每一台solr和zookeeper关联
修改每一台solr的tomcat 的 bin目录下catalina.sh文件中加入DzkHost指定zookeeper服务器地址:
export JAVA_OPTS="-Dsolr.solr.home=/usr/local/mao/solr-4.10.2/example/solr -DzkHost=192.168.56.101:2181,192.168.56.102:2181,192.168.56.103:2181"
3.4.6 启动所有的solr服务
3.4.7 访问solrcloud
3.4.8 SolrCloud集群配置
可以通过下边的方法配置新的集群。
1、创建core命令:
参数说明:
name指明collection名称
numShards指明分片数
replicationFactor指明副本数
maxShardsPerNode 每个节点最大分片数(默认为1)
property.schema:指定使用的schema.xml,这个文件必须在zookeeper上。
property.config:指定使用的solrconfig.xml,这个文件必须在zookeeper上。
2、删除core命令;
http://192.168.56.101:8080/solr/admin/collections?action=DELETE&name=mycore2
3、查询所有的core
http://192.168.56.101:8080/solr/admin/collections?action=LIST
4、显示集群的状态
http://192.168.56.101:8080/solr/admin/collections?action=CLUSTERSTATUS
5、分裂shard
http://192.168.56.101:8080/solr/admin/collections?action=SPLITSHARD&collection=mycore2&shard=shard1
6、删除shard
http://192.168.56.101:8080/solr/admin/collections?action=DELETESHARD&collection=mycore2&shard=shard1
-
更多的命令请参数官方文档:
apache-solr-ref-guide-4.10.pdf
3.4.9 启动solrCloud注意
启动solrCloud需要先启动solrCloud依赖的所有zookeeper服务器,再启动每台solr服务器。
如果服务器跟服务器之间无法通讯,查看每台服务器的/etc/hosts 里面是否配置了其他服务器的IP地址和hostname
***************************************************************************************************** 以上是关于SolrCloud今日大纲的主要内容,如果未能解决你的问题,请参考以下文章