Es+kafka搭建日志存储查询系统(设计)
Posted 刀锋诚心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Es+kafka搭建日志存储查询系统(设计)相关的知识,希望对你有一定的参考价值。
现在使用的比较常用的日志分析系统有Splunk和Elk,Splunk功能齐全,处理能力强,但是是商用项目,而且收费高。Elk则是Splunk项目的一个开源实现,Elk是ElasticSearch(Es)、Logstash、Kibana上个项目结合。Es就是基于Lucene的存储,索引的搜索引擎;logstash是提供输入输出及转化处理插件的日志标准化管道;Kibana提供可视化和查询统计的用户界面。往往这些开源项目并不是适合每一个公司的业务,业务不同,对开源项目扩展也就不同,logstash进行日志采集时,在Agent端并不适合做数据清洗,数据清洗往往是经常变化的,而且Agent一般占用的资源必须要受到一定限制否则会影响业务系统。我们可以将日志的采集采用一些开源系统重新进行组合,因为日志采集的业务特性,可以采用Es+kafka进行初步的存储查询。首先以Http协议收集日志为例,
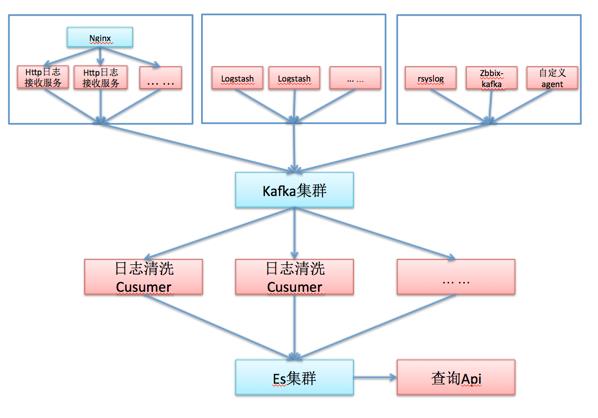
将整个日志存储查询总体分为四个层处理:
第一层:日志采集层;
主要处理日志采集的过程,针对生成的日志不同,大体上分成三大部分:
(1)、日志通过Http协议汇总到服务器端,一般是Web端,或者ios、android移动端通过HTTP 请求上报日志,这部分日志采集的agent暴露在公网上,可能会存在一些恶意上报垃圾日志,这部分日志是需要进行权限验证的,例如:在上报的日志中带上Token的验证,验证不成功直接丢弃,成功则将log存入到kafka对应的topic中。
(2)、服务器上的文本日志,这部分日志一般是业务系统存储的log文件,由于存在的是服务器端,一般不需要进行token验证,就可以直接采用logstash或者rsyslog进行汇总到kafka中去。
(3)、非文本日志,需要自己进行开发的自定义Agent 采集相关日志发送到kafka中,如监控某一个 radis、mysql等组件。此类日志和(2)相同,一般不是暴露在公网上,不需要进行token验证。
第二层:kafka
(1)、kafka的主要作用一个方面主要是为防止采集量大于日志清洗、存储的能力,这样会造成日志系统处理不及时,或者造成系统宕机,引起日志丢失。kafka是Apache开源的Hadoop生态圈中的分布式消息队列,其扩展性、和性能是非常强大的。加入消息队列在遇到日志高峰期,不能及时处理的日志存储在kafka中,不影响后面的日志清洗的系统,同时通过分析kafka 中日志队列的处理情况能够,对日志清洗层能力进行扩展和缩减。
(2)、另一方面就是方便系统解耦 ,使用kafka也方便扩展,如果要对日志进行一些实时统计处理,则采用Storm-kafka直接订阅相关的topic就能够将日志数据导入到Storm集群中进行实时统计分析。
第三层:日志清洗层;
将所有的日志清洗和统计的逻辑归于这一层进行处理。
第四层:日志存储层;
将日志存入到Es进行索引建立和查询。
环境搭建及相关例子:
官方文档:http://kafka.apache.org/090/documentation.html#quickstart
同时也可以采用CDH、Ambari等集群管理工具安装 kafka,这里不再赘述,Ambari离线安装文档:http://pan.baidu.com/s/1i5NrrSh。
storm实时处理例子:https://github.com/barrysun/storm-ml/tree/master/logmapping-storm-kafka
以上是关于Es+kafka搭建日志存储查询系统(设计)的主要内容,如果未能解决你的问题,请参考以下文章