Kafka Offset Storage
Posted 哥不是小萝莉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka Offset Storage相关的知识,希望对你有一定的参考价值。
1.概述
目前,Kafka 官网最新版[0.10.1.1],已默认将消费的 offset 迁入到了 Kafka 一个名为 __consumer_offsets 的Topic中。其实,早在 0.8.2.2 版本,已支持存入消费的 offset 到Topic中,只是那时候默认是将消费的 offset 存放在 Zookeeper 集群中。那现在,官方默认将消费的offset存储在 Kafka 的Topic中,同时,也保留了存储在 Zookeeper 的接口,通过 offsets.storage 属性来进行设置。
2.内容
其实,官方这样推荐,也是有其道理的。之前版本,Kafka其实存在一个比较大的隐患,就是利用 Zookeeper 来存储记录每个消费者/组的消费进度。虽然,在使用过程当中,JVM帮助我们完成了自一些优化,但是消费者需要频繁的去与 Zookeeper 进行交互,而利用ZKClient的API操作Zookeeper频繁的Write其本身就是一个比较低效的Action,对于后期水平扩展也是一个比较头疼的问题。如果期间 Zookeeper 集群发生变化,那 Kafka 集群的吞吐量也跟着受影响。
在此之后,官方其实很早就提出了迁移到 Kafka 的概念,只是,之前是一直默认存储在 Zookeeper集群中,需要手动的设置,如果,对 Kafka 的使用不是很熟悉的话,一般我们就接受了默认的存储(即:存在 ZK 中)。在新版 Kafka 以及之后的版本,Kafka 消费的offset都会默认存放在 Kafka 集群中的一个叫 __consumer_offsets 的topic中。
当然,其实她实现的原理也让我们很熟悉,利用 Kafka 自身的 Topic,以消费的Group,Topic,以及Partition做为组合 Key。所有的消费offset都提交写入到上述的Topic中。因为这部分消息是非常重要,以至于是不能容忍丢数据的,所以消息的 acking 级别设置为了 -1,生产者等到所有的 ISR 都收到消息后才会得到 ack(数据安全性极好,当然,其速度会有所影响)。所以 Kafka 又在内存中维护了一个关于 Group,Topic 和 Partition 的三元组来维护最新的 offset 信息,消费者获取最新的offset的时候会直接从内存中获取。
3.实现
那我们如何实现获取这部分消费的 offset,我们可以在内存中定义一个Map集合,来维护消费中所捕捉到 offset,如下所示:
protected static Map<GroupTopicPartition, OffsetAndMetadata> offsetMap = new ConcurrentHashMap<>();
然后,我们通过一个监听线程来更新内存中的Map,代码如下所示:
private static synchronized void startOffsetListener(ConsumerConnector consumerConnector) { Map<String, Integer> topicCountMap = new HashMap<String, Integer>(); topicCountMap.put(consumerOffsetTopic, new Integer(1)); KafkaStream<byte[], byte[]> offsetMsgStream = consumerConnector.createMessageStreams(topicCountMap).get(consumerOffsetTopic).get(0); ConsumerIterator<byte[], byte[]> it = offsetMsgStream.iterator(); while (true) { MessageAndMetadata<byte[], byte[]> offsetMsg = it.next(); if (ByteBuffer.wrap(offsetMsg.key()).getShort() < 2) { try { GroupTopicPartition commitKey = readMessageKey(ByteBuffer.wrap(offsetMsg.key())); if (offsetMsg.message() == null) { continue; } OffsetAndMetadata commitValue = readMessageValue(ByteBuffer.wrap(offsetMsg.message())); offsetMap.put(commitKey, commitValue); } catch (Exception e) { e.printStackTrace(); } } } }
在拿到这部分更新后的offset数据,我们可以通过 RPC 将这部分数据共享出去,让客户端获取这部分数据并可视化。RPC 接口如下所示:
namespace java org.smartloli.kafka.eagle.ipc service KafkaOffsetServer{ string query(1:string group,2:string topic,3:i32 partition), string getOffset(), string sql(1:string sql), string getConsumer(), string getActiverConsumer() }
这里,如果我们不想写接口来操作 offset,可以通过 SQL 来操作消费的 offset 数组,使用方式如下所示:
- 引入依赖JAR
<dependency> <groupId>org.smartloli</groupId> <artifactId>jsql-client</artifactId> <version>1.0.0</version> </dependency>
- 使用接口
JSqlUtils.query(tabSchema, tableName, dataSets, sql);
tabSchema:表结构;tableName:表名;dataSets:数据集;sql:操作的SQL语句。
4.预览
消费者预览如下图所示:

正在消费的关系图如下所示:

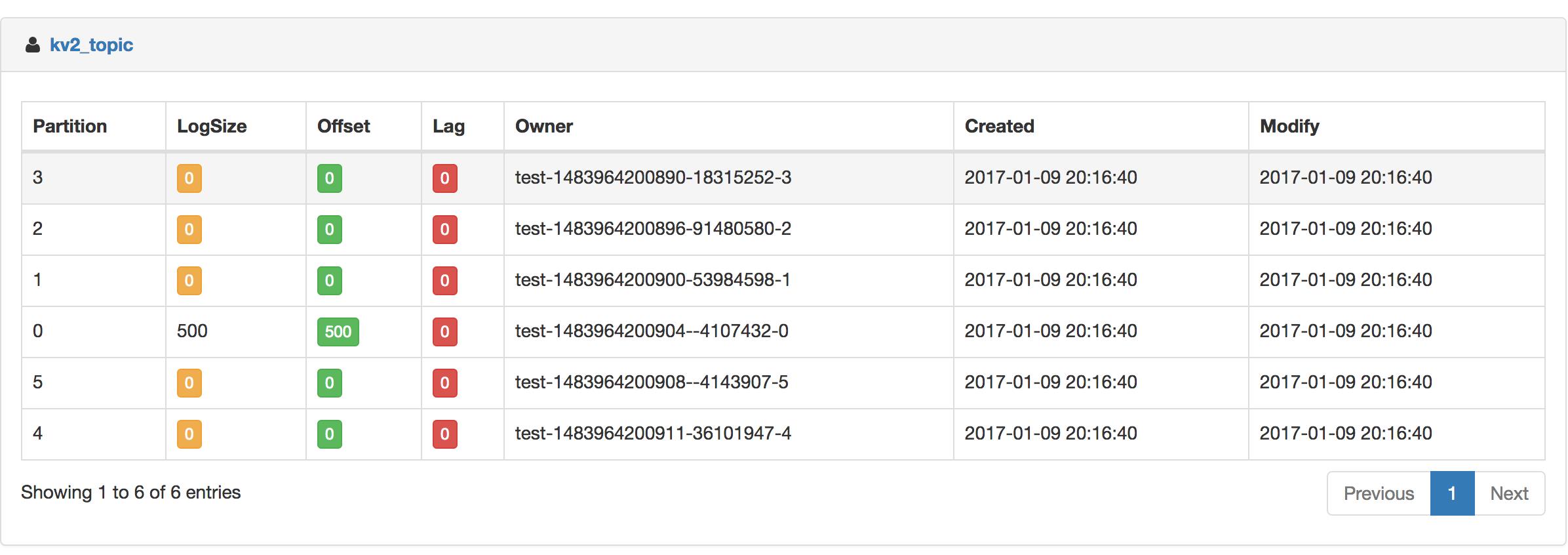
消费详细 offset 如下所示:
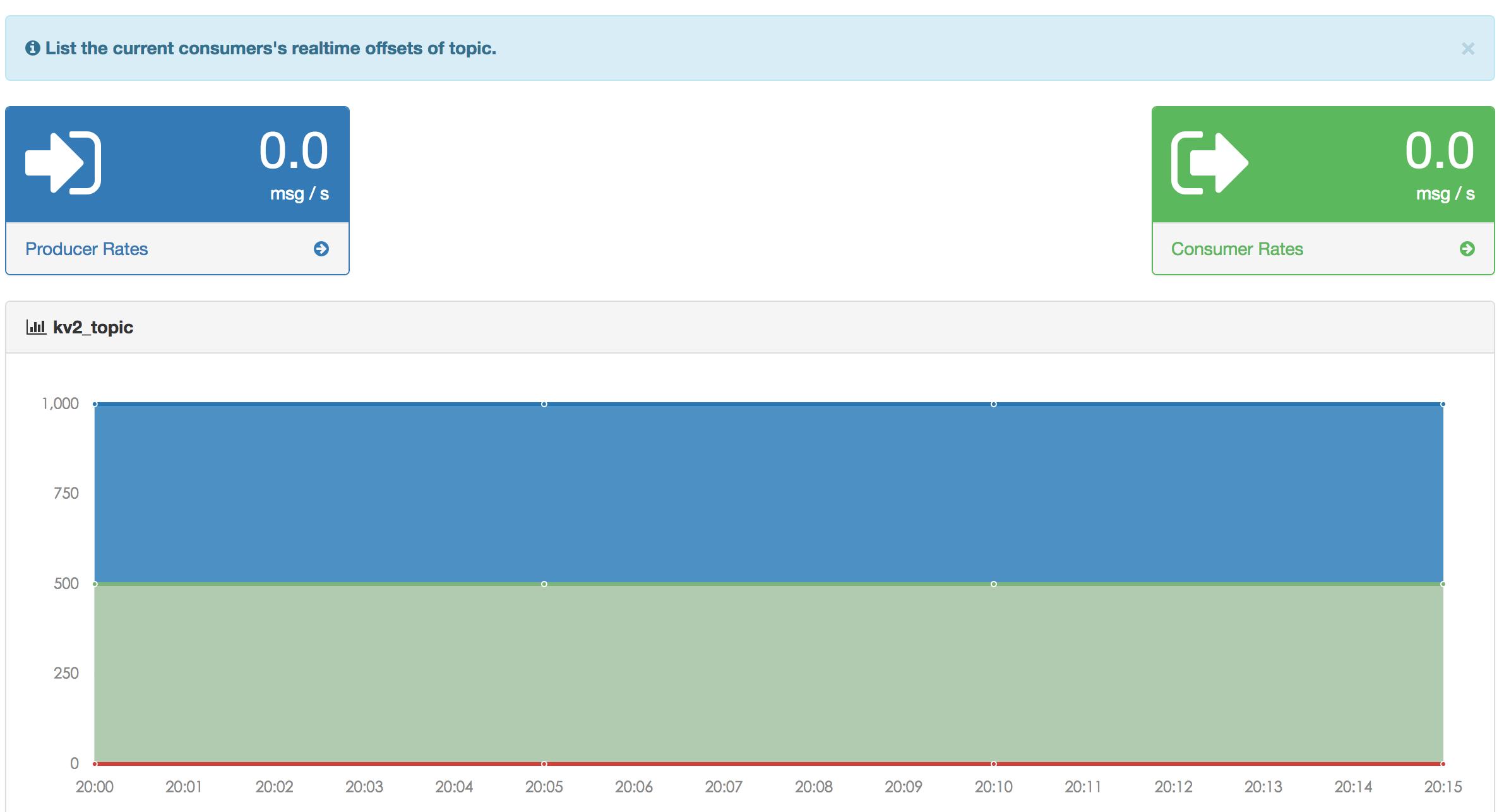
消费和生产的速率图,如下所示:
5.总结
这里,说明一下,当 offset 存入到 Kafka 的topic中后,消费线程ID信息并没有记录,不过,我们通过阅读Kafka消费线程ID的组成规则后,可以手动生成,其消费线程ID由:Group+ConsumerLocalAddress+Timespan+UUID(8bit)+PartitionId,由于消费者在其他节点,我们暂时无法确定ConsumerLocalAddress。最后,欢迎大家使用 Kafka 集群监控 ——[ Kafka Eagle ],[ 操作手册 ]。
6.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
以上是关于Kafka Offset Storage的主要内容,如果未能解决你的问题,请参考以下文章
Debezium系列之:详细整理总结Kafka Connect Configs
Kafka 学习笔记之 High Level Consumer相关参数