行存储和列存储
Posted 学而不思则罔,思而不学则殆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了行存储和列存储相关的知识,希望对你有一定的参考价值。
本文地址:http://www.cnblogs.com/qiaoyihang/p/6262806.html
传统的行式数据库将一个个完整的数据行存储在数据页中。这种方式在大数据量查询的时候会出现以下问题
一般来说,OLTP(Online Transaction Processing,联机事务处理)应用适合采用这种方式。
一个OLAP类型的查询可能需要访问几百万甚至几十亿个数据行,且该查询往往只关心少数几个数据列。例如,查询今年销量最高的前20个商品,这个查询只关心三个数据列:时间(date)、商品(item)以及销售量(sales amount)。商品的其他数据列,例如商品URL、商品描述、商品所属店铺,等等,对这个查询都是没有意义的。
如下图,列式数据库是将同一个数据列的各个值存放在一起。插入某个数据行时,该行的各个数据列的值也会存放到不同的地方。上例中列式数据库只需要读取存储着“时间、商品、销量”的数据列,而行式数据库需要读取所有的数据列。因此,列式数据库大大地提高了OLAP大数据量查询的效率。当然,列式数据库不是万能的,每次读取某个数据行时,需要分别从不同的地方读取各个数据列的值,然后合并在一起形成数据行。因此,如果每次查询涉及的数据量较小或者大部分查询都需要整行的数据,列式数据库并不适用。
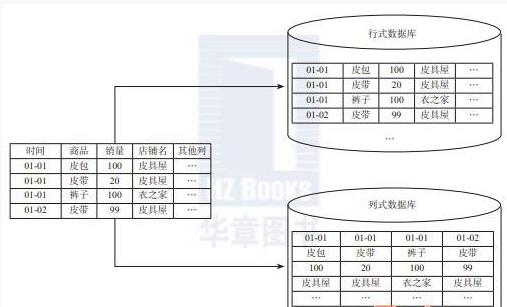
很多列式数据库还支持列组(column group,Bigtable系统中称为locality group),即将多个经常一起访问的数据列的各个值存放在一起。如果读取的数据列属于相同的列组,列式数据库可以从相同的地方一次性读取多个数据列的值,避免了多个数据列的合并。列组是一种行列混合存储模式,这种模式能够同时满足OLTP和OLAP的查询需求。
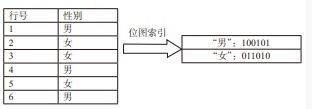
由于同一个数据列的数据重复度很高,因此,列式数据库压缩时有很大的优势。例如,Google Bigtable列式数据库对网页库压缩可以达到15倍以上的压缩率。另外,可以针对列式存储做专门的索引优化。比如,性别列只有两个值,“男”和“女”,可以对这一列建立位图索引:
如下图所示,“男”对应的位图为100101,表示第1、4、6行值为“男”;“女”对应的位图为011010,表示第2、3、5行值为“女”。如果需要查找男性或者女性的个数,只需要统计相应的位图中1出现的次数即可。另外,建立位图索引后0和1的重复度高,可以采用专门的编码方式对其进行压缩。
得出如下结论:
列式存储: 每一列单独存放,数据即是索引。
一行数据包含一个列或者多个列,每个列一单独一个cell来存储数据。而行式存储,则是把一行数据作为一个整体来存储。
在HANA的世界中,并不是只存在列式存储,行式存储也是存在的。那么读者不经要问
什么时候应该使用行式存储?什么时候应该使用列式存储呢?
如果你大部分时间都是关注整张表的内容,而不是单独某几列,并且所关注的内容是不需要通过任何聚集运算的,那么推荐使用行式存储。原因是重构每一行数据(即解压缩过程)对于HANA来说,是一个不小的负担。
列式存储的话,比如你比较关注的都是某几列的内容,或者有频繁聚集需要的,通过聚集之后进行数据分析的表。
详细归纳为如下:
选择HANA列式存储
|
基于一列或比较少的列计算的时候 |
|
经常关注一张表某几列而非整表数据的时候 |
|
数据表拥有非常多的列的时候 |
|
数据表有非常多行数据并且需要聚集运算的时候 |
|
数据表列里有非常多的重复数据,有利于高度压缩 |
选择HANA行式存储
|
关注整张表内容,或者需要经常更新数据 |
|
需要经常读取整行数据 |
|
不需要聚集运算,或者快速查询需求 |
|
数据表本身数据行并不多 |
|
数据表的列本身有太多唯一性的数据 |
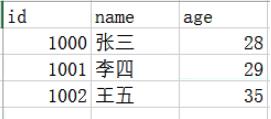
按列存储

存储方式
put 表名,rowkey,列族:列名 ,值
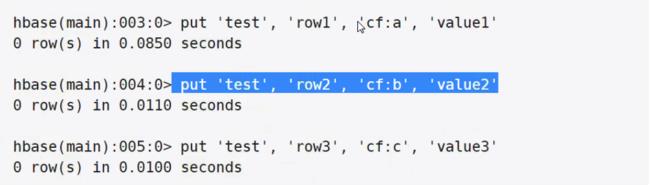
逻辑视图:
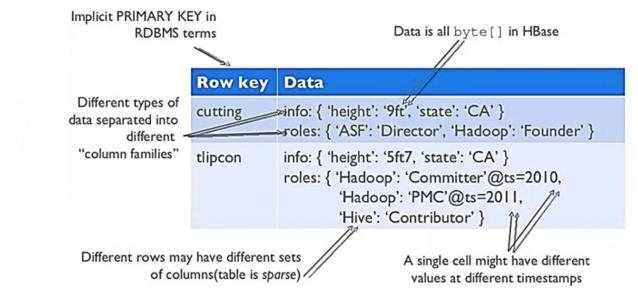
数据模型:

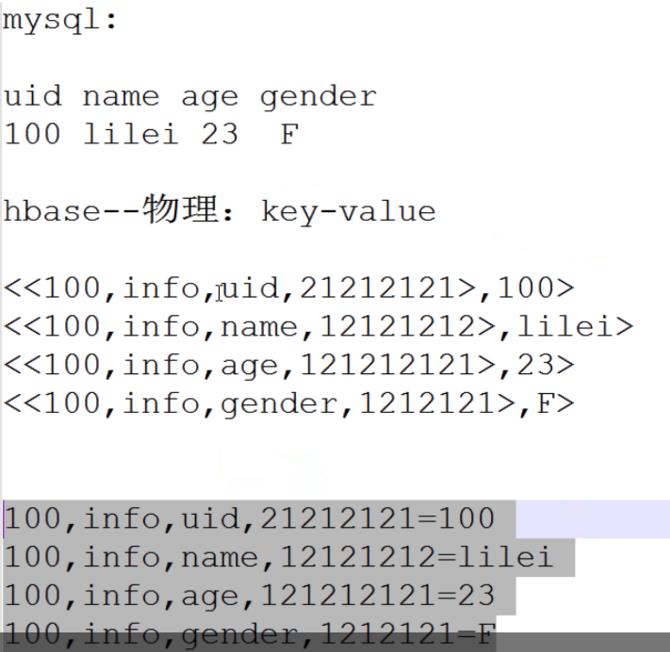
以上是关于行存储和列存储的主要内容,如果未能解决你的问题,请参考以下文章