Hadoop 6第一个mapreduce程序 WordCount
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop 6第一个mapreduce程序 WordCount相关的知识,希望对你有一定的参考价值。
1、程序代码
Map:
import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.util.StringUtils; public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException { String[] words = StringUtils.split(value.toString(), ‘ ‘); for(String word : words){ context.write(new Text(word), new IntWritable(1)); } } }
Reduce:
import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.Reducer.Context; public class wordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { protected void reduce(Text arg0, Iterable<IntWritable> arg1,Context arg2) throws IOException, InterruptedException { int sum = 0; for(IntWritable i : arg1){ sum += i.get(); } arg2.write(arg0, new IntWritable(sum)); } }
Main:
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class RunJob { public static void main(String[] args) { Configuration config = new Configuration(); try { FileSystem fs = FileSystem.get(config); Job job = Job.getInstance(config); job.setJobName("wordCount"); job.setJarByClass(RunJob.class); job.setMapperClass(WordCountMapper.class); job.setReducerClass(wordCountReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path("/usr/input/")); Path outPath = new Path("/usr/output/wc/"); if(fs.exists(outPath)){ fs.delete(outPath, true); } FileOutputFormat.setOutputPath(job, outPath); Boolean result = job.waitForCompletion(true); if(result){ System.out.println("Job is complete!"); }else{ System.out.println("Job is fail!"); } } catch (Exception e) { e.printStackTrace(); } } }
2、打包程序
将Java程序打成Jar包,并上传到Hadoop服务器上(任何一台在启动的NameNode节点即可)
3、数据源
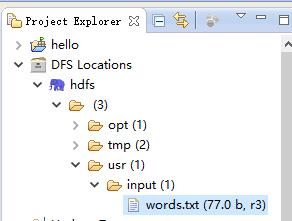
数据源是如下:
hadoop java text hdfs tom jack java text job hadoop abc lusi hdfs tom text
将该内容放到txt文件中,并放到HDFS的/usr/input(是HDFS下不是Linux下),可以使用Eclipse插件上传:
4、执行Jar包
# hadoop jar jar路径 类的全限定名(Hadoop需要配置环境变量) $ hadoop jar wc.jar com.raphael.wc.RunJob
执行完成以后会在HDFS的/usr下新创建一个output目录:
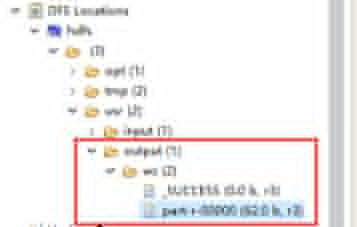
查看执行结果:
abc 1 hadoop 2 hdfs 2 jack 1 java 2 job 1 lusi 1 text 3 tom 2
完成了单词个数的统计。
以上是关于Hadoop 6第一个mapreduce程序 WordCount的主要内容,如果未能解决你的问题,请参考以下文章