学霸数据处理项目之数据处理框架开发者手册
Posted nrm1
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学霸数据处理项目之数据处理框架开发者手册相关的知识,希望对你有一定的参考价值。
写在前面,本文将详细介绍学霸数据处理项目中的数据处理框架中每一个方法的意义及其一些在运行方面需要注意的细节,供开发人员使用,开发人员在阅读相关方法说明时请参照相关代码,对于本文中的错误和疏漏对您造成的不便深表歉意。
一、DataProcess.java
该类是后台处理程序的入口
1)main
该方法是整个处理程序的入口,方法中首先定义了两个文件state.json以及control.json,正如其名字一样,这两个方法的作用是控制该程序的启动和关闭,以及供前端网页界面获取后台处理程序的状态。之后实例化了GetFileInfo类 ,用于获取control.json中的信息,Data为java自带类,用于获取时间,接下来程序将判断前端是否允许启动数据处理程序,如果允许,则实例化core类(后台处理核心类),并开始运行。接下来将判断前端是否已发出结束指令,如果已发出,则等待所有线程均已执行完毕后,安全退出并关闭程序。
2)setString
该方法生成的字符串即为state.json中的信息,传入的参数s为open或close代表程序现在的状态,其中使用到了数据库的相关操作接口databaseOperation,需要注意的是,其中方法传入的参数数据库的服务器ip,登陆的账号和密码,如若不同应做适当修改。
3)getSeconds
该方法输入的时间为程序启动的时间,该方法返回程序启动的时间的格式化字符串。
二、core.java
该类主要负责后台程序运行时的开关工作。
1)start函数为核心函数,他首先打开名为control.json的文件,查找其中的信息,如果control.json的allowClear为true,则将数据库中所有数据的isDeal项清空,重新处理这些文件,否则不进行清空处理,接下来启动console线程,进行后台数据处理。
2)get***函数,这些函数主要负责返回程序进行中的一些状态。其状态返回值多调用console中的函数,在此不再缀续。
三、Console.java
该类是后台进程的运行起点。
1)run函数为后台进程总循环。mark为循环开关,control.json中allowOpen为true时其也为true,反之亦然,single为线程状态,当其为true时代表在循环内,否则代表在循环外,此变量主要是为了反映后台程序运行状态,反映在state.json中,openState值即为single。在循环主体内,首先需要使用getnotdealed查找数据库找到一个尚未处理的文件,然后获取这个文件的存储路径URL(此时的路径为在10.2.28.78上的路径,不能用于数据处理直接访问到),此时使用getFromNetWorkConnection函数将这个文件下载下来,下载到本地localpath所指向的文件夹下,此时做好了数据处理之前的一切准备操作,之后调用findEmptyThread寻找一个空闲的线程,将此文件交给此线程处理,若没有空余线程则在此循环处等待直到可以分配线程,使用startThread开始处理此文件。
2)get***函数和core中的类似,这些函数返回值多调用DistributionThread类中的函数,在此不再缀续。
四、DistributionThread.java
这个类主要是负责分配线程操作。
threadNumber这个属性控制着整个程序将会开启的最大线程数。
Thread是线程数组
ProcessThread是处理的类数组,与Thread数组一样多。一一对应
名为hs的String数组为线程状态数组,与ProcessThread一一对应,存储着各个线程的状态。
1)init函数负责初始化ProcessThread数组和Thread数组。
2)getActiveURL函数通过isAlive函数获取各个线程当前是否正在运行,
3)其他get***函数不再缀续。
4)findEmptyThread寻找一个当前在线程数组内的空闲线程,将其作为可利用线程分配出去。
5)isHaveRunThread判断当前是否还有处理线程没有终止,这个函数主要用在关闭线程处理时,如果还有 线程在跑,那么就要等到线程全部结束后,才能终止程序。
6)startThread用来开启一个线程,传入的参数是处理文件在数据库中的id,线程号i,和处理的文件路径(本地路径,文件下载到本地的路径)。函数中除了把传入的id,url,i作为参数传递给文件处理函数之外,还把本类作为参数传了下去,主要是为了修改hs(线程状态),便于显示。之后便会开启文件处理函数。
五、ProcessThread.java
此类为文件处理类。
URL为下载到本地的路径。
WEB为文件获取的网站网址
id为文件在数据库中的编号
threadNo为当前文件处理的线程号
1)run为文件处理核心函数,suffix为获取文件后缀名,并根据不同的类型交给不同的函数进行处理,处理完后使用update函数将文件信息回写到数据库中,inset函数将文件上传到solr上完成整个处理流程,最后删除本地临时文件。
2)set***函数均为类初始化函数,在此不再缀续。
六、databaseOperation.java
此类为接口类,其中所有的函数定义均可在databaseOperationClass.java中找到实现。
七、databaseOperationClass.java
此类为接口实现类,其中实现了databaseOperation.java中定义的所有方法。
其中方法输入参数ip为数据库服务器username为数据库用户名,password为数据库密码,没有 特殊说明参数均为此含义。
1)queryHandleFail此方法尚未实现,因为按照目前的处理流程,不存在处理失败的情况
2)querybyid,queryURlbyid此方法通过输入的文件在数据库中的id,查找文件在数据库中登记的文件在远程服务器上的储存路径(URL),其中实例化的DBHelper类和调用的query函数稍后会有介绍,在此不再缀续。
3)getFromNetWorkConnection此方法负责从远程服务器上下载文件到本地,url为远程服务器上的文件路径,localpath为下载下来后存储在本地的路径。此函数首先会对字符串url处理,产生remotepath远程路径和remotefilename文件名,使用down.getFromNetWorkConnection下载文件,从而在本地产生一个与远程服务器上同名的文件,并返回文件名。
4)DeleteFileFromLocal删除本地临时文件,localpath为本地临时文件夹,localfilename为文件名,其中调用down.DeleteFileFromLocal删除本地文件并返回true代表 删除成功。
5)DeleteFileFromLocal删除本地临时文件,localfullpath为文件全路径 ,需拆分成文件夹和文件名,再使用DeleteFileFromLocal删除本地文件。
6)handleWord此方法用来处理word语句,其中调用了TestJNI类,处理完获取的文件内容存储到content+线程号+.txt中,处理完获取的关键字在temp+线程号+.txt中,之后调用proc.getKey和proc.getContent获取文件中相关信息后,存储到map对应的结构中,返回。
7)handlePdfOrhtml此方法用来处理html和pdf,其中调用了Process_html_pdf类,处理方法为proc.run,返回map结构。
8)queryTitle函数用来返回当前数据库中登记的文件个数。并返回。其中的type类型可以是html,pdf,image,doc,分别代表单个类型的返回数。
9)queryHaveDone函数用来返回当前已经处理过的文件个数。其实就是查找数据库中isDeal为1的项的个数,并返回。其中的type类型可以是html,pdf,image,doc,分别代表单个类型的返回数。
10)cleardealedtag用来清除文件处理过的信息,其实就是将数据库中所有文件的isDeal置为0.
11)getnotdealed获取一个尚未处理过的文件在数据库中得id,其实就是查找第一个数据库中isDeal为0的文件id。
12)insert函数用来将文件信息上传到solr。
13)update函数用来将数据处理获取到的文件新信息放回到数据库中。
八、DBHelper.java
数据库操作类,可以对数据库进行查询,更新,插入,删除操作。
1)DBHelper构造方法,用于实现与远程服务器的连接。
2)query用于实现对数据库的查询,传入的map结构中包含需要查询的相关限制信息。
3)update更新数据库中相关信息,id为更新的文件信息在数据库中的编号,map为需要更新的信息。
4)updateAll更新数据库中所有表项相关信息,map为更新的信息。
5)delete删除与map中信息匹配的数据库表项。
6)delete删除数据库中id那一行
7)release释放资源,若此DBHelper不再使用,记得一定要调用一次,不然用久了资源耗尽就会挂
九、GetFileInfo.java
获取文件信息类,主要负责读取control.json中的内容和写state.json文件
1)getBuffer获取control.json文件的读取指针。若没有此文件,则在当前文件夹下生成此文件。
2)getInfo获取control.json中allowOpen选项是否为true,若为则返回true,否则返回false。
3)getInfo2获取control.json中allowClear选项是否为true。若为则返回true,否则返回false。
4)setInfo将string中的内容写入state.json。
十、DownloadFile.java
下载文件类,方法的实现在Download_dll.dll中。
1)getFromNetWorkConnection方法将远程服务器上的文件下载到本地,参数含义分别是 remotepath远程文件夹,localpath本地文件夹,username远程服务器登陆用户名,password远程服务器登陆密码,remotefilename远程服务器文件名,localfilename下载到本地后的文件名。
2)DeleteFileFromLocal方法将下载 到 本地的临时文件删除,参数含义分别是localpath本地路径,localfilename本地临时文件名。
十一、process_html_and_pdf.java
处理 pdf和html类
1)process方法实现在ConsoleApplication5.dll中,用于处理html和pdf。
十二、Process_html_pdf.java
此类 是处理html和pdf的java程序部分。
1)Process_html_pdf构造函数,会初始化一些必要的信息以及调用ManagementFactory.getRuntimeMXBean().getName()获取线程池 中的线程名,并通过name.split("@")[0]获取id(线程编号 )。
2)run是html和pdf的处理核心程序,其中会调用process_html_and_pdf中的process并生成多个临时文件用于接下来处理,接下来会调用get***程序获取程序处理的各个文件内容,并放到map结构中,返回结果。
3)getAuthor,getTitle,getDate均直接从文件中读取内容并返回,不再缀续。
4)getisqa,getQuestion,getAnswer分别是用来判断是否是问答对,以及是问答对时获取问题列表以及答案列表。
5)getContent除了在Process_html_pdf中run函数用到 以外 ,还在 处理word时用到,参数mode即代表调用的是哪个函数,参数为0时调用的是run函数,参数为1时是处理word的 获取内容时调的 ,参数大于1代表 处理word分词时调的。
6)getKey除了在Process_html_pdf中run函数用到 以外 ,还在 处理word时用到,参数mode即代表调用的是哪个函数,参数为1代表处理word分词用到 ,参数为其他代表处理html或pdf时用到。
十三、SolrHelper.java
solr操作类,可以对solr进行查找,插入,删除操作
在本程序中,仅有insert,commitchange被其他类使用
1)本程序中使用的insert方法,通过传入map结构将数据上传,这就要保证数据结构的完整性和正确性,此时在传入参数map时需要特别小心,要知道solr上有哪些key,否则就是引发solr异常。
此处引用solr上定义好的field
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="sku" type="text_en_splitting_tight" indexed="true" stored="true" omitNorms="true"/> <field name="name" type="text_general" indexed="true" stored="true"/> <field name="manu" type="text_general" indexed="true" stored="true" omitNorms="true"/> <field name="cat" type="string" indexed="true" stored="true" multiValued="true"/> <field name="features" type="text_general" indexed="true" stored="true" multiValued="true"/> <field name="includes" type="text_general" indexed="true" stored="true" termVectors="true" termPositions="true" termOffsets="true" /> <field name="weight" type="float" indexed="true" stored="true"/> <field name="price" type="float" indexed="true" stored="true"/> <field name="popularity" type="int" indexed="true" stored="true" /> <field name="inStock" type="boolean" indexed="true" stored="true" /> <field name="store" type="location" indexed="true" stored="true"/> <!-- Common metadata fields, named specifically to match up with SolrCell metadata when parsing rich documents such as Word, PDF. Some fields are multiValued only because Tika currently may return multiple values for them. Some metadata is parsed from the documents, but there are some which come from the client context: "content_type": From the HTTP headers of incoming stream "resourcename": From SolrCell request param resource.name --> <field name="title" type="text_general" indexed="true" stored="true" multiValued="true"/> <field name="subject" type="text_general" indexed="true" stored="true"/> <field name="description" type="text_general" indexed="true" stored="true"/> <field name="comments" type="text_general" indexed="true" stored="true"/> <field name="author" type="text_general" indexed="true" stored="true"/> <field name="keywords" type="string" indexed="true" stored="true" multiValued="true"/> <field name="category" type="text_general" indexed="true" stored="true"/> <field name="resourcename" type="text_general" indexed="true" stored="true"/> <field name="url" type="text_general" indexed="true" stored="true"/> <field name="content_type" type="string" indexed="true" stored="true" multiValued="true"/> <field name="last_modified" type="date" indexed="true" stored="true"/> <field name="links" type="string" indexed="true" stored="true" multiValued="true"/> <field name="creation_date" type="string" indexed="true" stored="true"/> <field name="web_title" type="string" indexed="true" stored="true" multiValued="false" /> <field name="web_link" type="string" indexed="true" stored="true" multiValued="false" /> <field name="doc_type" type="string" indexed="true" stored="true" multiValued="false" /> <field name="answer_content" type="string" indexed="true" stored="true" multiValued="true" /> <field name="question_content" type="string" indexed="true" stored="true" multiValued="false" /> <!-- Main body of document extracted by SolrCell. NOTE: This field is not indexed by default, since it is also copied to "text" using copyField below. This is to save space. Use this field for returning and highlighting document content. Use the "text" field to search the content. --> <field name="content" type="text_general" indexed="false" stored="true" multiValued="true"/> <!-- catchall field, containing all other searchable text fields (implemented via copyField further on in this schema --> <field name="text" type="text_general" indexed="true" stored="false" multiValued="true"/> <!-- catchall text field that indexes tokens both normally and in reverse for efficient leading wildcard queries. --> <field name="text_rev" type="text_general_rev" indexed="true" stored="false" multiValued="true"/> <!-- non-tokenized version of manufacturer to make it easier to sort or group results by manufacturer. copied from "manu" via copyField --> <field name="manu_exact" type="string" indexed="true" stored="false"/> <field name="payloads" type="payloads" indexed="true" stored="true"/>
2)commitchange方法意味提交改动,insert,delete操作结束后要commit才会生效
十四、TestJNI.java
此类为word处理类,之所以名字没有改的原因后续再说。
此类中的方法均在c++dll.dll文件中实现。
1)denoiseWord去燥处理,传入的参数为文件路径以及处理的线程号。
2)cutwords分词,传入的参数为线程号,以及去燥后的结果、
3)key获取关键词,传入的参数为文件路径以及处理的线程号。
4)translate翻译关键词 ,传入的参数为处理的线程号。
十五、其他文件
1)log4j.properties这个是上传solr时必须要有的配置,这个文件必须存在。
2)jar文件夹下的jar包,这些jar包是程序运行过程中所依赖的,必须包含,且应加到eclipse的extent jars中引入方法见http://jingyan.baidu.com/article/ca41422fc76c4a1eae99ed9f.html
3)CorpusWordlist.xls是分词所需要的文件,缺少他会影响分词。
4)data文件夹下的sNoise.txt和sDict.txt是去燥使用的,缺少它去燥会报错。
5)dll文件夹下的dll文件是整个程序运行的关键,但是仅仅将这些文件放到这里是不够的,需要将这些文件复制到java_path下,具体找到路径的方法为在编写的java程序中使用如下语句System.out.println(System.getProperty("java.library.path"));输出的路径中第一个即是目标文件夹,将dll文件放到此文件夹下即完成准备工作。
十六、运行
此时整个程序应该就可以在eclipse中运行了,但是这样还不够,我们需要将其导成jar包,变成一个后台程序,导出jar包方法 见http://jingyan.baidu.com/article/5bbb5a1b280d0113eba179ce.html 导出后的jar包右键使用winrar打开,
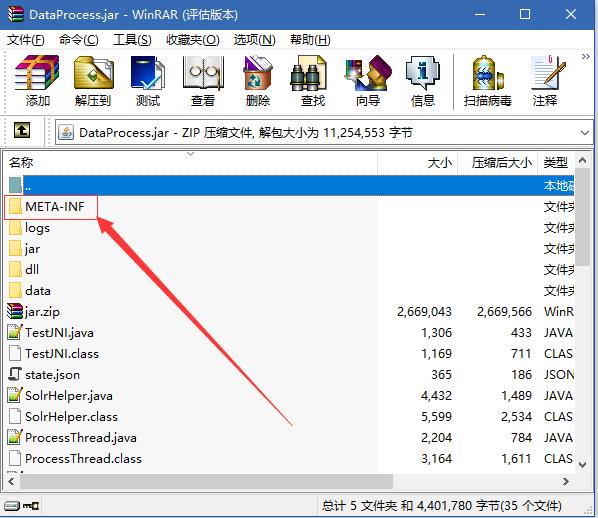
打开META-INF文件夹,看到MANIFEST.MF文件,使用文本编辑器打开文件,将如下内容复制并替换原有内容
Manifest-Version: 1.0
Main-Class: DataProcess
Class-Path: jar/commons-codec-1.9.jar
jar/commons-io-2.3.jar
jar/httpclient-4.3.1.jar
jar/httpcore-4.3.jar
jar/httpmime-4.3.1.jar
jar/jcl-over-slf4j-1.7.6.jar
jar/log4j-1.2.17.jar
jar/noggit-0.5.jar
jar/slf4j-api-1.7.6.jar
jar/slf4j-log4j12-1.7.6.jar
jar/solr-solrj-4.10.4.jar
jar/sqljdbc4.jar
jar/org.json.jar
注意:最后有一行空行。保存后退出,
此时整个程序依旧不能运行,需要在导出的jar文件相同 目录下创建一个control.json文件,文件内容为{"allowOpen":"true","allowClear":"false"}保存后退出,之后就可以在命令行中运行当前程序了,打开 cmd,调整到当前目录,使用命令java -jar ***.jar(***为文件名)看到提示DataProcessing Begining!代表程序已经开始运行,之后如果数据库中有标记为未处理的文件,那么就会进行处理,处理过程中会显示处理的文件的爬取网址,此时若想要关闭数据处理,可以将control.json文件中的内容改为{"allowOpen":"false","allowClear":"false"},之后等待提示DataProcessing finished!数据处理安全结束,此时即可完成整个操作,但这只是在阶段测试中使用的方法,在整个程序实际运行过程中,control.json并不是手动修改的,而是由网页上的按钮,经过js调用方法由php进行修改的,从而可以达到远程对数据处理程序的操作。
以上是关于学霸数据处理项目之数据处理框架开发者手册的主要内容,如果未能解决你的问题,请参考以下文章