sorl入门
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sorl入门相关的知识,希望对你有一定的参考价值。
本教程是从别人的基础上借鉴整理的
Solr是一个独立的企业级搜索应用服务器,它对外提供API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引(solr生成倒排索引,数据库生成的索引是二叉树索引,效率差距很大);也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。Solr是一个类似于Google或者Bing的全文检索引擎, Solr是与搜索引擎优化(SEO)相关联的。很多公司也使用elasticsearch作为搜索引擎。
一、solr安装
准备:tomcat7.0版本,solr5.3.0版本
目前网络上对solr3.x和4.x的安装介绍比较多,这里使用新的5.3.1版本进行安装介绍。
1、下载tomcat和solr压缩包并解压;
2、将 solr 压缩包中 solr-5.3.0\\server\\solr-webapp\\文件夹下有个webapp文件夹,将之复制到Tomcat\\webapps\\目录下,文件夹名改成solr ;
3、将 solr 压缩包中 solr-5.3.0\\server\\lib\\ext 中的 jar 全部复制到 Tomcat\\ webapps\\solr\\WEB-INF\\lib 目录中;
4、将 solr 压缩包中 solr-5.3.0/ server/resources /log4j.properties 复制到Tomcat\\ webapps\\solr\\WEB-INF\\lib 目录中;
5、将 solr 压缩包中 solr-5.3.0/server/solr 目录复制到计算机某个目录下,如D:\\testsolr\\solr_home(solr创建的core到时会存放在该目录下);
6、打开Tomcat/webapps/solr/WEB-INF下的web.xml,找到如下配置内容(初始状态下该内容是被注释掉的):
<env-entry><env-entry-name>solr/home</env-entry-name><env-entry-value>D:/testsolr/solr_home/solr</env-entry-value><env-entry-type>java.lang.String</env-entry-type></env-entry>
将 env-entry-value 中的内容改成你的solr_home路径(第5步的文件),这里是D:/testsolr/solr_home/solr;
7、保存关闭,而后启动tomcat,在浏览器输入http://localhost:8080/solr即可出现Solr的管理界面,如下: 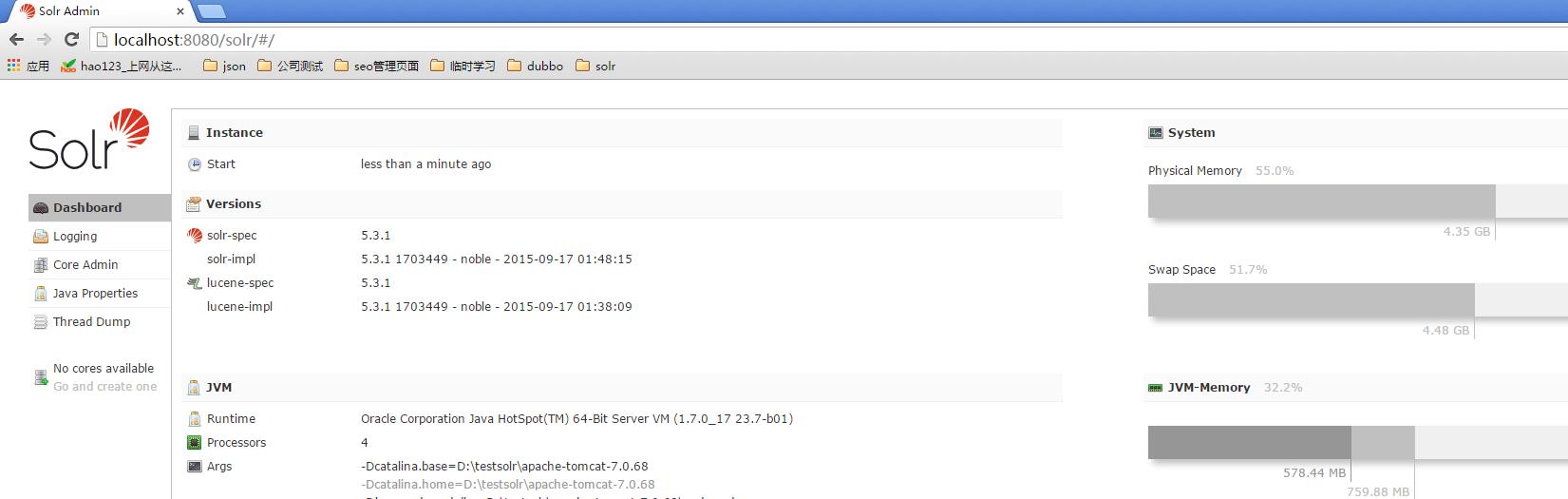
二、创建第一个core
1、将solr-5.3.0/dist中的solr-dataimporthandler、solr-dataimporthandler-extras的jar包copy到tomcat\\webapps\\solr\\WEB-INF\\lib下;
2、在D:\\testsolr\\solr_home\\solr下创建my_core文件夹(名称与下图的instanceDir一致,建议下图中的name也和该文件夹名一致);
3、在my_core文件夹下创建data和conf文件夹;
4、将solr-5.3.0\\example\\example-DIH\\solr\\solr\\conf所有文件和文件夹都copy到D:\\testsolr\\solr_home\\solr\\my_core\\conf下;
5、启动tomcat,访问solr,创建core,如下 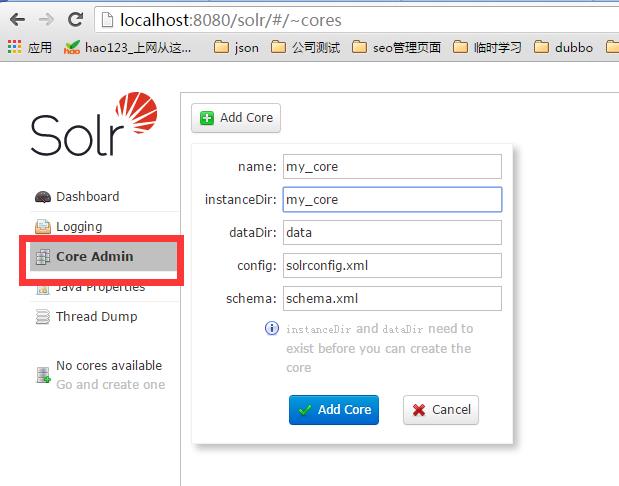
如此,新增core即可完成;
6、可以在“core selector”这里查询和编辑你的solr相关信息;
三、solr分词
这里使用的是mmseg4j 分词,该jar包网上下载的普遍有问题,不能正常使用。经测试,该版本可以,下载地址:http://download.csdn.net/detail/u012385190/9550326;
1、将文件里的jar包拷贝到Tomcat\\webapps\\solr\\WEB-INF\\lib下;
2、在 D:\\testsolr\\solr_home\\solr\\ 目录下新建一个 dic 文件夹 , 把 新下载的词库(data文件夹下)拷贝到 dic 目录下;
3、在 D:\\testsolr\\solr_home\\solr\\my_core\\conf\\schema.xml 文件的里添加如下:
<fieldtype name="textComplex" class="solr.TextField" positionIncrementGap="100"><analyzer><tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="D:/testsolr/solr_home/solr/dic"></tokenizer></analyzer></fieldtype><fieldtype name="textMaxWord" class="solr.TextField" positionIncrementGap="100"><analyzer><tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="maxword" dicPath="D:/testsolr/solr_home/solr/dic"></tokenizer></analyzer></fieldtype><fieldtype name="textSimple" class="solr.TextField" positionIncrementGap="100"><analyzer><tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" dicPath="D:/testsolr/solr_home/solr/dic"></tokenizer></analyzer></fieldtype>
这里不同的name选用不同的分词方式;
其中dicPath属性的值为第二步的地址,不要写错哦;
4、在 D:\\testsolr\\solr_home\\solr\\my_core\\conf\\schema.xml 文件里添加如下 :
<field name="name" type="textMaxWord" indexed="true" stored="true" multiValued="true" />
<field name="description" type="textMaxWord" indexed="true" stored="true" multiValued="true" />- 1
- 2
- 1
- 2
5、开启服务如下进行分词测试,如下图分词: 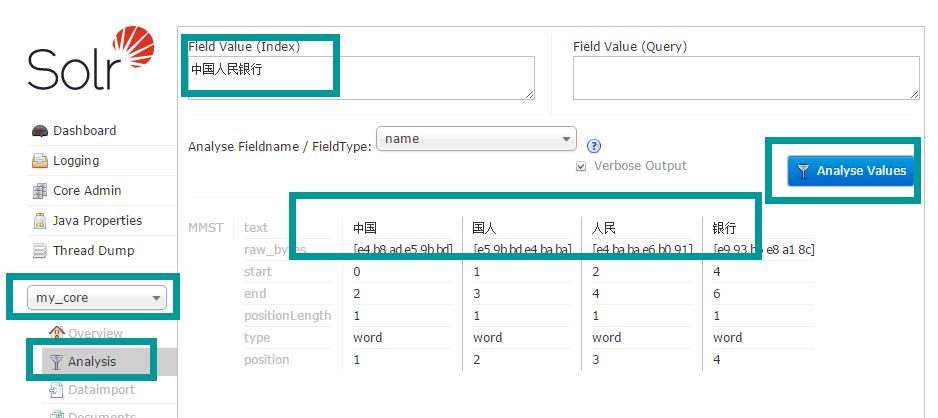
如下图所示root字段是没有分词的结果: 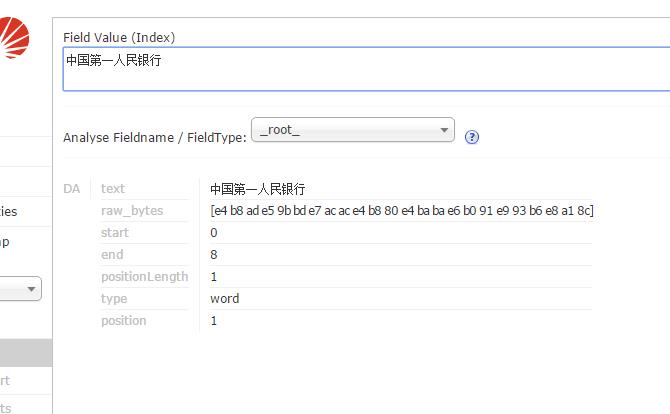
在过程中出现如下错误,是因为字段重复,在schema.xml中将另一个content字段的配置注释掉即可(name同理)。 
6、如此,分词ok
四、solr连接数据库
接下来进行solr连接数据库,生成索引,以及查询方法。
数据库建表语句:
CREATE TABLE `test_person` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL COMMENT ‘姓名‘,
`description` varchar(500) DEFAULT NULL COMMENT ‘简介‘,
PRIMARY KEY (`id`)
);
insert into test_person(name,description) values(‘周星驰‘,‘香港著名喜剧演员‘);
insert into test_person(name,description) values(‘周润发‘,‘香港著名演员‘);
insert into test_person(name,description) values(‘周节能‘,‘台湾著名歌手,号称音乐天王‘);
insert into test_person(name,description) values(‘成龙‘,‘香港著名动作演员‘);
insert into test_person(name,description) values(‘山本一木‘,‘日本鬼子‘);
insert into test_person(name,description) values(‘仓木麻衣‘,‘日本歌手‘);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
1、将数据库驱动包放入solr项目工程中(我用的MySQL,使用jar包mysql-connector-java-5.1.18-bin.jar);
2、在自己创建的core实例的conf文件中进行数据配置(我的是D:\\testsolr\\solr_home\\solr\\my_core\\conf\\solr-data-config.xml),覆盖内容如下(数据库表自己根据配置自己建):
<?xml version="1.0" encoding="UTF-8"?>
<dataConfig>
<dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/test" user="root" password="jhp123" />
<document name="messages">
<entity name="message" transformer="ClobTransformer" query="select * from test_peoson where name like ‘%${dataimporter.request.name}%‘">
<field column="id" name="id" />
<field column="name" name="name" />
<field column="description" name="description" />
</entity>
</document>
</dataConfig>
url=”jdbc:mysql://localhost:3306/test” user=”root” password=”123” 这里配置了 mysql 的连接路径 , 用户名 , 密码
<field column="name" name="name" /> 这里配置的是数据库里要索引的字段, 注意name是在分词的第4 步配置的,同时只有这样匹配的字段最终solr才会查询显示出来,所以需要用到的字段必须在该文件中<field column="***" name="***" />配置才可以;- 1
- 1
3、在D:\\testsolr\\solr_home\\solr\\my_core\\conf\\schema.xml文件中添加如下字段信息:
<field name="name" type="textMaxWord" indexed="true" stored="true" multiValued="true" />
<field name="description" type="textMaxWord" indexed="true" stored="true" multiValued="true" />- 1
- 2
- 1
- 2
注意这里的配置是数据库里需要用到的字段,在分词时这两个字段已配置,故此步可省略。其中id字段已存。
4、在 D:\\testsolr\\solr_home\\solr\\my_core\\conf 目录下的 solrconfig.xml 文件里 , 添加如下代码 :
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">D:/testsolr/solr_home/solr/my_core/conf/solr-data-config.xml</str>
</lst>
</requestHandler>- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
D:/testsolr/solr_home/solr/my_core/conf/solr-data-config.xml为上一步的配置文件地址;
5、把本地下载解压的 solr文件里dist 目录下的 solr-dataimporthandler.jar 和 solr-dataimporthandler-extras.jar 复制到Tomcat \\webapps\\solr\\WEB-INF\\lib 目录下;
6、如图打开solr,把数据库(其实也可以用 http/file 资源)中的记录放到索引中。现大概看下步骤: 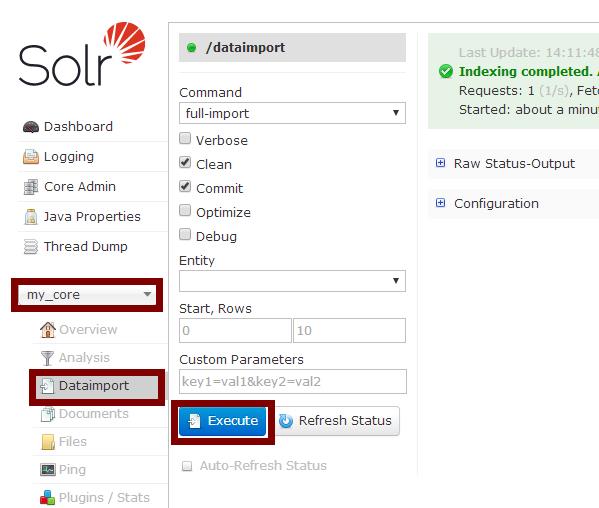
7、测试查询: 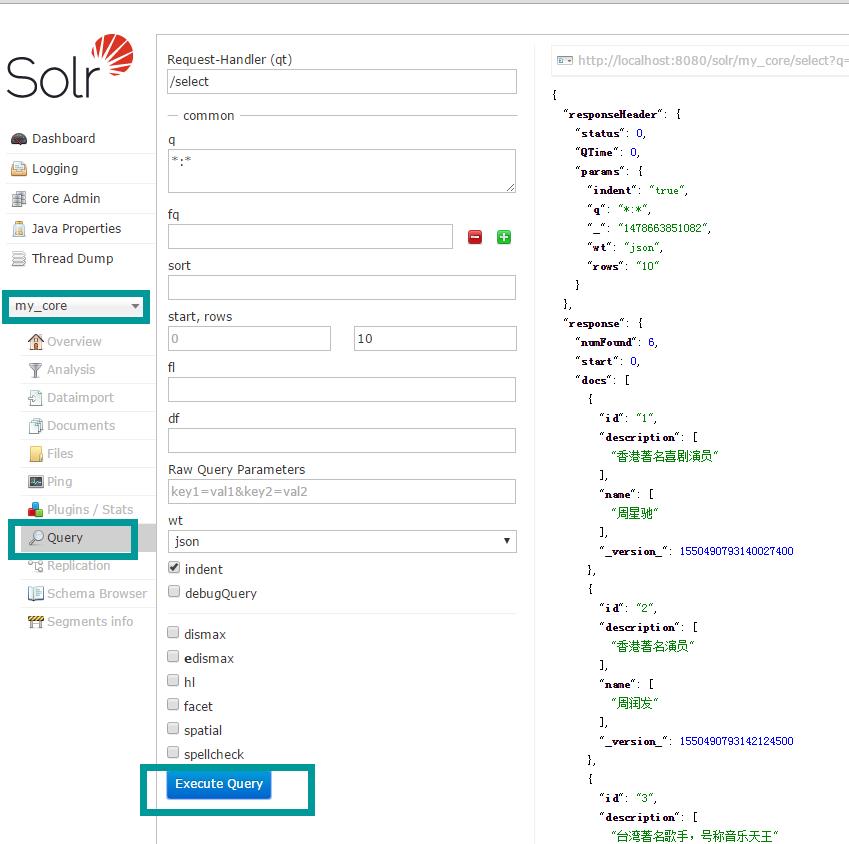
8、solr查询参数详解,如下图所示 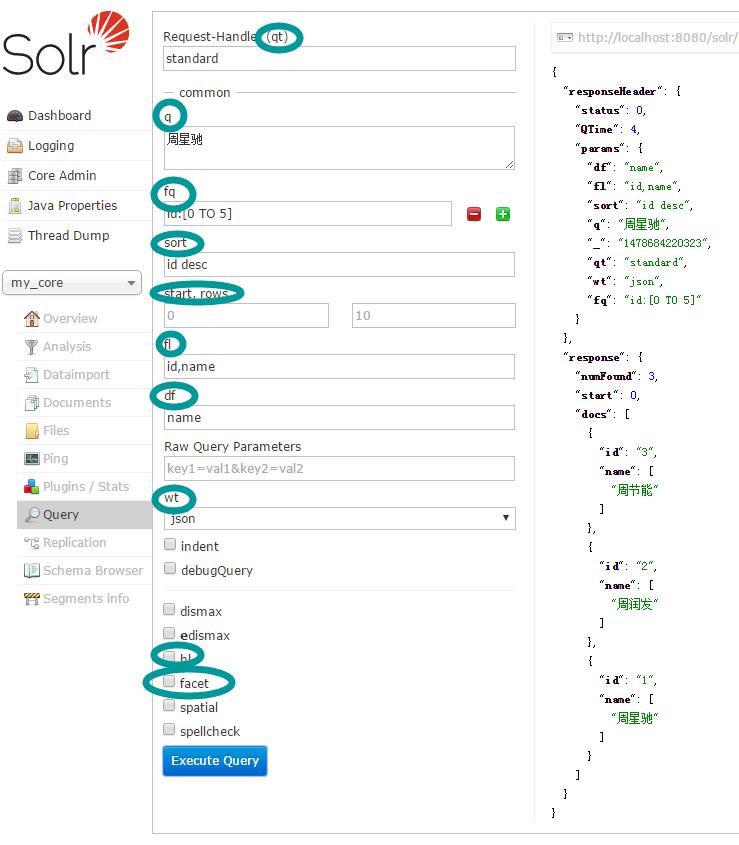
如图所示对图中的参数进行解释:
qt :(query type)指定那个类型来处理查询请求,一般不用指定,默认是standard;
q : 查询的关键字,此参数最为重要,例如图中表示查询所有字段中含有“周星驰”三个字中的至少某一个字的数据;
fq :(filter query)过虑查询,提供一个可选的筛选器查询。返回在q查询符合结果中同时符合的fq条件的查询结果,例如:q=id:1&fq=sort:[1 TO 5],找关键字id为1 的,并且sort是1到5之间的;
sort : 排序方式,例如id desc 表示按照 “id” 降序;
rows :指定返回结果最多有多少条记录,默认值为 10,配合start实现分页;
fl : 指定返回哪些字段,用逗号或空格分隔,注意:字段区分大小写,例如,fl= id,title,sort,默认返回数据配置文件中file的字段;
df 默认的查询字段,一般默认指定。比如df为name,q为周星驰,则搜索name中含有周星驰”三个字中的至少某一个字的数据;
wt:返回类型,有json、XML等;
hl:高亮显示;
facet:分组,其中facet.query表示所有的索引中含有该内容的数据有多少条,facet.field和facet.prefix需要结合,表示字段facet.field含有facet.prefix的内容共有多少条;
solr查询参数具体参考:http://www.cnblogs.com/zhangweizhong/p/5056884.html
solr在Java中的使用:http://blog.csdn.net/u012385190/article/details/53115546
Solr是一个独立的企业级搜索应用服务器,它对外提供API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引(solr生成倒排索引,数据库生成的索引是二叉树索引,效率差距很大);也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。Solr是一个类似于Google或者Bing的全文检索引擎, Solr是与搜索引擎优化(SEO)相关联的。很多公司也使用elasticsearch作为搜索引擎。
一、solr安装
准备:tomcat7.0版本,solr5.3.0版本
目前网络上对solr3.x和4.x的安装介绍比较多,这里使用新的5.3.1版本进行安装介绍。
1、下载tomcat和solr压缩包并解压;
2、将 solr 压缩包中 solr-5.3.0\\server\\solr-webapp\\文件夹下有个webapp文件夹,将之复制到Tomcat\\webapps\\目录下,文件夹名改成solr ;
3、将 solr 压缩包中 solr-5.3.0\\server\\lib\\ext 中的 jar 全部复制到 Tomcat\\ webapps\\solr\\WEB-INF\\lib 目录中;
4、将 solr 压缩包中 solr-5.3.0/ server/resources /log4j.properties 复制到Tomcat\\ webapps\\solr\\WEB-INF\\lib 目录中;
5、将 solr 压缩包中 solr-5.3.0/server/solr 目录复制到计算机某个目录下,如D:\\testsolr\\solr_home(solr创建的core到时会存放在该目录下);
6、打开Tomcat/webapps/solr/WEB-INF下的web.xml,找到如下配置内容(初始状态下该内容是被注释掉的):
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>D:/testsolr/solr_home/solr</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
将 env-entry-value 中的内容改成你的solr_home路径(第5步的文件),这里是D:/testsolr/solr_home/solr;
7、保存关闭,而后启动tomcat,在浏览器输入http://localhost:8080/solr即可出现Solr的管理界面,如下:
二、创建第一个core
1、将solr-5.3.0/dist中的solr-dataimporthandler、solr-dataimporthandler-extras的jar包copy到tomcat\\webapps\\solr\\WEB-INF\\lib下;
2、在D:\\testsolr\\solr_home\\solr下创建my_core文件夹(名称与下图的instanceDir一致,建议下图中的name也和该文件夹名一致);
3、在my_core文件夹下创建data和conf文件夹;
4、将solr-5.3.0\\example\\example-DIH\\solr\\solr\\conf所有文件和文件夹都copy到D:\\testsolr\\solr_home\\solr\\my_core\\conf下;
5、启动tomcat,访问solr,创建core,如下
如此,新增core即可完成;
6、可以在“core selector”这里查询和编辑你的solr相关信息;
三、solr分词
这里使用的是mmseg4j 分词,该jar包网上下载的普遍有问题,不能正常使用。经测试,该版本可以,下载地址:http://download.csdn.net/detail/u012385190/9550326;
1、将文件里的jar包拷贝到Tomcat\\webapps\\solr\\WEB-INF\\lib下;
2、在 D:\\testsolr\\solr_home\\solr\\ 目录下新建一个 dic 文件夹 , 把 新下载的词库(data文件夹下)拷贝到 dic 目录下;
3、在 D:\\testsolr\\solr_home\\solr\\my_core\\conf\\schema.xml 文件的里添加如下:
<fieldtype name="textComplex" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="D:/testsolr/solr_home/solr/dic">
</tokenizer>
</analyzer>
</fieldtype>
<fieldtype name="textMaxWord" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="maxword" dicPath="D:/testsolr/solr_home/solr/dic">
</tokenizer>
</analyzer>
</fieldtype>
<fieldtype name="textSimple" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" dicPath="D:/testsolr/solr_home/solr/dic">
</tokenizer>
</analyzer>
</fieldtype>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
这里不同的name选用不同的分词方式;
其中dicPath属性的值为第二步的地址,不要写错哦;
4、在 D:\\testsolr\\solr_home\\solr\\my_core\\conf\\schema.xml 文件里添加如下 :
<field name="name" type="textMaxWord" indexed="true" stored="true" multiValued="true" />
<field name="description" type="textMaxWord" indexed="true" stored="true" multiValued="true" />- 1
- 2
- 1
- 2
5、开启服务如下进行分词测试,如下图分词:
如下图所示root字段是没有分词的结果:
在过程中出现如下错误,是因为字段重复,在schema.xml中将另一个content字段的配置注释掉即可(name同理)。
6、如此,分词ok
四、solr连接数据库
接下来进行solr连接数据库,生成索引,以及查询方法。
数据库建表语句:
CREATE TABLE `test_person` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL COMMENT ‘姓名‘,
`description` varchar(500) DEFAULT NULL COMMENT ‘简介‘,
PRIMARY KEY (`id`)
);
insert into test_person(name,description) values(‘周星驰‘,‘香港著名喜剧演员‘);
insert into test_person(name,description) values(‘周润发‘,‘香港著名演员‘);
insert into test_person(name,description) values(‘周节能‘,‘台湾著名歌手,号称音乐天王‘);
insert into test_person(name,description) values(‘成龙‘,‘香港著名动作演员‘);
insert into test_person(name,description) values(‘山本一木‘,‘日本鬼子‘);
insert into test_person(name,description) values(‘仓木麻衣‘,‘日本歌手‘);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
1、将数据库驱动包放入solr项目工程中(我用的MySQL,使用jar包mysql-connector-java-5.1.18-bin.jar);
2、在自己创建的core实例的conf文件中进行数据配置(我的是D:\\testsolr\\solr_home\\solr\\my_core\\conf\\solr-data-config.xml),覆盖内容如下(数据库表自己根据配置自己建):
<?xml version="1.0" encoding="UTF-8"?>
<dataConfig>
<dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/test" user="root" password="jhp123" />
<document name="messages">
<entity name="message" transformer="ClobTransformer" query="select * from test_peoson where name like ‘%${dataimporter.request.name}%‘">
<field column="id" name="id" />
<field column="name" name="name" />
<field column="description" name="description" />
</entity>
</document>
</dataConfig>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
url=”jdbc:mysql://localhost:3306/test” user=”root” password=”123” 这里配置了 mysql 的连接路径 , 用户名 , 密码
<field column="name" name="name" /> 这里配置的是数据库里要索引的字段, 注意name是在分词的第4 步配置的,同时只有这样匹配的字段最终solr才会查询显示出来,所以需要用到的字段必须在该文件中<field column="***" name="***" />配置才可以;- 1
- 1
3、在D:\\testsolr\\solr_home\\solr\\my_core\\conf\\schema.xml文件中添加如下字段信息:
<field name="name" type="textMaxWord" indexed="true" stored="true" multiValued="true" />
<field name="description" type="textMaxWord" indexed="true" stored="true" multiValued="true" />- 1
- 2
- 1
- 2
注意这里的配置是数据库里需要用到的字段,在分词时这两个字段已配置,故此步可省略。其中id字段已存。
4、在 D:\\testsolr\\solr_home\\solr\\my_core\\conf 目录下的 solrconfig.xml 文件里 , 添加如下代码 :
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">D:/testsolr/solr_home/solr/my_core/conf/solr-data-config.xml</str>
</lst>
</requestHandler>- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
D:/testsolr/solr_home/solr/my_core/conf/solr-data-config.xml为上一步的配置文件地址;
5、把本地下载解压的 solr文件里dist 目录下的 solr-dataimporthandler.jar 和 solr-dataimporthandler-extras.jar 复制到Tomcat \\webapps\\solr\\WEB-INF\\lib 目录下;
6、如图打开solr,把数据库(其实也可以用 http/file 资源)中的记录放到索引中。现大概看下步骤:
7、测试查询:
8、solr查询参数详解,如下图所示
如图所示对图中的参数进行解释:
qt :(query type)指定那个类型来处理查询请求,一般不用指定,默认是standard;
q : 查询的关键字,此参数最为重要,例如图中表示查询所有字段中含有“周星驰”三个字中的至少某一个字的数据;
fq :(filter query)过虑查询,提供一个可选的筛选器查询。返回在q查询符合结果中同时符合的fq条件的查询结果,例如:q=id:1&fq=sort:[1 TO 5],找关键字id为1 的,并且sort是1到5之间的;
sort : 排序方式,例如id desc 表示按照 “id” 降序;
rows :指定返回结果最多有多少条记录,默认值为 10,配合start实现分页;
fl : 指定返回哪些字段,用逗号或空格分隔,注意:字段区分大小写,例如,fl= id,title,sort,默认返回数据配置文件中file的字段;
df 默认的查询字段,一般默认指定。比如df为name,q为周星驰,则搜索name中含有周星驰”三个字中的至少某一个字的数据;
wt:返回类型,有json、XML等;
hl:高亮显示;
facet:分组,其中facet.query表示所有的索引中含有该内容的数据有多少条,facet.field和facet.prefix需要结合,表示字段facet.field含有facet.prefix的内容共有多少条;
solr查询参数具体参考:http://www.cnblogs.com/zhangweizhong/p/5056884.html
solr在Java中的使用:http://blog.csdn.net/u012385190/article/details/53115546
以上是关于sorl入门的主要内容,如果未能解决你的问题,请参考以下文章