在最近的一次报告中,Ben Hamner向我们介绍了他和他的同事在Kaggle比赛中看到的一些机器学习项目的常见误区。
这个报告于2014年2月在Strate举办,名为《机器学习小精灵》。
在这篇文章中,我们将从Ben的报告中了解一些常见的误区,它们是什么及如何避免陷入这些误区。
机器学习的过程
在报告之前,Ben向我们展示了一个解决机器学习问题大体流程。
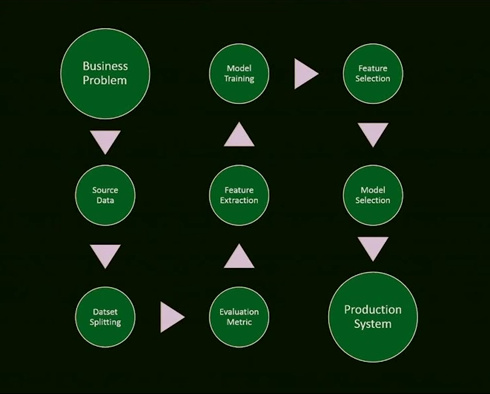
机器学习流程,摘自Ben Hamner的《机器学习小精灵》
这个流程包括如下9步:
- 以一个行业问题开始
- 源数据
- 切分数据
- 选择一个评价标准
- 进行特征提取
- 训练模型
- 特征选择
- 模型选择
- 生产系统
Ben强调这个过程是迭代的过程,而非线性的。
他也谈及在这个过程中的每一步都可能出错,每个错误都可能使整个机器学习过程难以达到预期效果。
鉴别狗和猫
Ben提出了一个研究建造一个“自动猫门”的案例,这个“门”对猫开放而对狗关闭。这是一个启发性的例子,因为它设计到了处理数据问题上的一系列关键问题。

鉴别狗和猫,摘自Ben Hamner的《机器学习小精灵》
样本大小
这个例子的第一个卖点就是,模型学习的准确度与数据样本大小有关,并展示更多的样本与更好的准确度之间的关系。
他通过不断增加训练数据,直到模型准确度趋于稳定。这个例子能够很好让你了解,你的系统对样本大小及相应调整有多敏感。
错误的问题
第二个卖点就是这个系统失败了,它对所有的猫都拒之门外。
这个例子突出了理解我们需要解决的问题的约束是非常重要的,而不是关注你想解决的问题。
机器学习工程中的误区
Ben接着讨论了解决机器学习问题中的4个常见误区。
虽然这些问题非常常见,但是他指出它们相对比较容易被识别及解决。
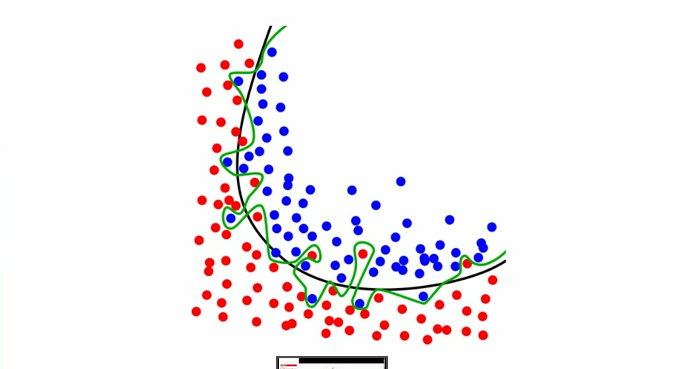
过拟合,摘自Ben Hamner的《机器学习小精灵》
- 数据泄露:利用模型中的生产系统不能访问的数据。在时序问题中这个问题特别常见。也可能发生在像系统id的数据上,id可能表示一个类标签。运行模型并且仔细查看有助于系统的特征。完整检查并考虑其是否有意义。(检查参考论文《数据挖掘中的泄露 | Leakage in Data Mining》)。
- 过拟合:在训练数据上建模太精密,同时模型中又存在一些噪声点。这时过拟合会降低模型的扩展能力, 其在更高的维度与更复杂的类界限下更甚。
- 数据采用和切分:相对于数据泄露,你需要非常小心地知道训练、测试、交叉检验数据集是否是真正的独立数据集。对于时序问题,很多想法和工作需要保证可以按时间顺序给系统回复数据和验证模型的准确性。
- 数据质量:检查你的数据的一致性。Ben给了一个航班起飞及着陆地点的数据,很多不一致,重复及错误的数据需要被识别及明确地处理。这些数据会直接损害建模及模型的扩展能力。
总结
Ben的《机器学习小精灵》是一个快速且实用的报告。
你将会得到一个关于机器学习常见误区的有用速成学习,并且这些技巧能很容易地用在处理数据的工作当中。