Spark分布式计算框架
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark分布式计算框架相关的知识,希望对你有一定的参考价值。
写在前面
Spark是分布式计算领域中继Hadoop之后,又一个比较流行的框架,最近研究了Spark的基本内容,这里稍微总结下,并与Hadoop进行对比。
什么是Spark?
Spark是伯克利大学AMP实验室在09年提出的开源的通用分布式计算框架,使用的也是类似Hadoop的计算模型,但是在设计理念上有较多地改进。概括来说,Spark是一种快速的集群计算技术:
- 基于Hadoop Map Reduce,扩展了Map Reduce的模型
- 提供了更多的分布式计算场景,包括交互式查询和流处理
- 基于内存的集群计算,大大提高了计算速度
- 更为高效的容错机制
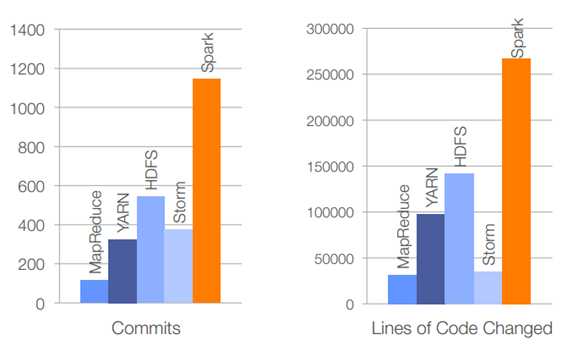
就目前Spark发展趋势来讲,使用Spark的企业将会越来越多,在开源社区Spark代码的活跃度也已经赶超了Hadoop,以下为目前Spark的企业用户,以及2015年报告中Spark的代码活跃度。

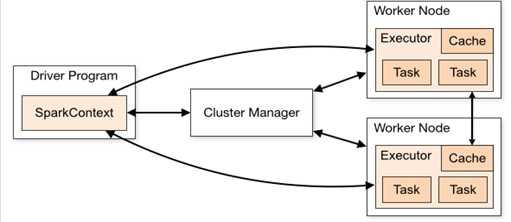
Spark里的关键结构:RDD
RDD(Resilient Distributed Datasets),中文称为弹性分布式数据集,是在分布式文件系统之上的一种只读的、分区的记录集合。RDD存储在内存中,Spark的计算任务中的操作也是基于RDD的。RDD的只读性指其状态不可变,一般不可修改,一个新的RDD只能由原始的硬盘数据或者其它的RDD经过一系列变换生成。“分区”的含义是RDD中的元素是根据key来进行分区的,保存到多个节点上,还原时只会重新计算丢失分区的数据,不会影响整个系统。Spark基于RDD进行计算的设计,一些中间数据存储在内存里,相比于Hadoop,节省了从本地硬盘里存取数据的时间,有效提高了计算速度,因此Spark特别适用于迭代式计算的场景。
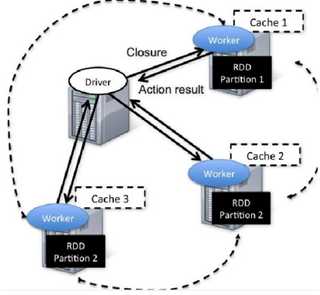
Spark的容错机制
容错是分布式计算里一个不容忽视的问题。Spark在容错机制上也有所突破,主要是基于RDD的特性。RDD容错称为loneage机制,指的是RDD里存储足够的lineage信息能还原出它在stable storage里数据分区。这里的lineage指的是粗粒度地作用于特定数据的一系列的变换操作序列,比如filter,map,join等,记录了一个RDD是如何通过其他dataset变换而生成的。
Spark VS Hadoop

以上是关于Spark分布式计算框架的主要内容,如果未能解决你的问题,请参考以下文章
使用spark分布式计算框架进行数据计算时 出现报错 Caused by: java.io.IOException: Input path does not exist