[Keras] mnist with cnn
Posted 机器学习水很深
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Keras] mnist with cnn相关的知识,希望对你有一定的参考价值。
典型的卷积神经网络。
一、数据的预处理
- Keras傻瓜式读取数据:自动下载,自动解压,自动加载。
- # X_train:
array([[[[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.],
...,
[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.]]],
...,
[[[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.],
...,
[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.]]]], dtype=float32)
- # y_train:
array([5, 0, 4, ..., 5, 6, 8], dtype=uint8)
但需要二值化作为output:np_utils.to_categorical(y_train, nb_classes)
- # Y_train:
Y_train[0]
Out[56]: array([ 0., 0., 0., 0., 0., 1., 0., 0., 0., 0.])
Y_train[1]
Out[57]: array([ 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
Y_train[2]
Out[58]: array([ 0., 0., 0., 0., 1., 0., 0., 0., 0., 0.])
Code: 图片--> Matrix


#coding:utf-8 import os from PIL import Image import numpy as np #读取文件夹mnist下的42000张图片,图片为灰度图,所以为1通道, #如果是将彩色图作为输入,则将1替换为3,并且data[i,:,:,:] = arr改为data[i,:,:,:] = [arr[:,:,0],arr[:,:,1],arr[:,:,2]] def load_data(): data = np.empty((42000,1,28,28),dtype="float32") label = np.empty((42000,),dtype="uint8") imgs = os.listdir("./mnist") num = len(imgs) for i in range(num): img = Image.open("./mnist/"+imgs[i]) arr = np.asarray(img,dtype="float32") data[i,:,:,:] = arr label[i] = int(imgs[i].split(\'.\')[0]) return data,label
二、如何建模
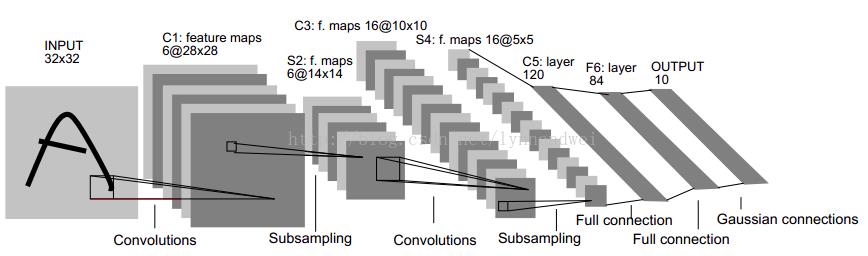

Figure, LeNet-5的网络结构
看图,详见链接!
Model结构说明:http://blog.csdn.net/strint/article/details/44163869
LeNet-5中主要的有:卷积层、下抽样层、全连接层3中连接方式。
- 卷积层
采用的都是5x5大小的卷积核,且卷积核每次滑动一个像素,一个特征图谱使用同一个卷积核(即特征图谱内卷积核共享参数)。
每个上层节点的值乘以连接上的参数,把这些乘积及一个偏置参数相加得到一个和,把该和输入激活函数,激活函数的输出即是下一层节点的值。
卷积核有5x5个连接参数加上1个偏置共26个训练参数。
【32*32 卷积(5*5)后得到28*28,如下Figure 6】
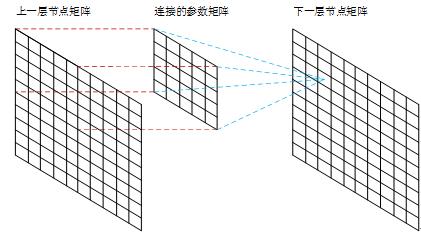
Figure 6 卷积神经网络连接与矩阵卷积的对应关系
- 下抽样层
采用的是2x2的输入域,即上一层的4个节点作为下一层1个节点的输入,且输入域不重叠,即每次滑动2个像素,下抽样节点的结构见Figure 7。
每个下抽样节点的4个输入节点求和后取平均,均值乘以一个参数加上一个偏置参数作为激活函数的输入,激活函数的输出即是下一层节点的值。
一个下抽样节点只有2个训练参数。
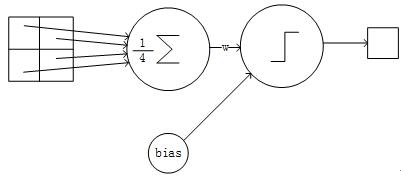
Figure 7 一个下抽样节点的连接方式
- 全连接层
(略)
纪要:
输入层是32x32像素的图片,比数据集中最大的的字符(最大体积是20x20像素的字符位于28x28像素区域的中心)大很多。这样做的原因是能使潜在的特征比如边缘的端点、拐角能够出现在最高层次的特征解码器的接收域的中心。
LeNet-5的最后一个卷积层(C3,见后面)的接收域的中心与输入的32x32的图像的中心的20x20的区域相连。
输入的像素值被标准化为背景色(白色)值为 -0.1、前景色(黑色)值为1.175:这样使得输入的均值大致为0、方差大致为1,从而有利于加快训练的速度,类似矩阵的归一化。
在后面的描述中,卷积层用Cx标记,子抽样层用Sx标记,全连接层用Fx标记,其中x表示该层的是LeNet的第x层。
C1层是卷积层,形成6个特征图谱。
特征图谱中的每个单元与输入层的一个5x5的相邻区域相连,即卷积的输入区域大小是5x5,每个特征图谱内参数共享,即每个特征图谱内只使用一个共同卷积核,卷积核有5x5个连接参数加上1个偏置共26个参数。
卷积区域每次滑动一个像素,这样卷积层形成的特征图谱每个的大小是28x28。
C1层共有(5x5+1)x6=156个训练参数,有156x28x28=122304个连接。
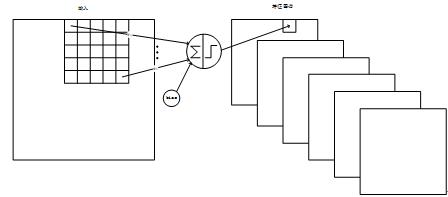
Figure 8 C1层的结构
S2层是一个下抽样层。
C1层的6个28x28的特征图谱分别进行以2x2为单位的下抽样得到6个14x14的图。
每个特征图谱使用一个下抽样核,每个下抽象核有两个训练参数,所以:
共有2x6=12个训练参数,但是有(2x2+1)x14x14x6=5880个连接。
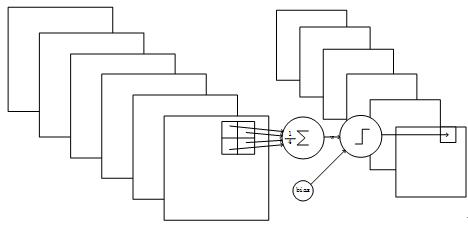
Figure 9 S2层的网络结构
C3层是一个卷积层,卷积和和C1相同,不同的是C3的每个节点与S2中的多个图相连。
C3层有16个10x10的图,每个图与S2层的连接的方式如Table 1 所示。
C3与S2中前3个图相连的卷积结构见Figure 10。这种不对称的组合连接的方式有利于提取多种组合特征。
改成有:
(5x5x3+1)x6 C3的0与S2的0,1,2连接; C3的1与S2的1,2,3连接; ...
+ (5x5x4+1)x6
+ (5x5x4+1)x3
+ (5x5x6+1)x1
= 1516个训练参数,
共有1516x10x10=151600个连接。

Table 1 C3与S2的连接关系
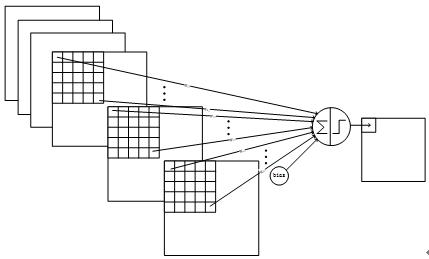
Figure 10 C3与S2中前3个图相连的卷积结构
S4是一个下采样层。
C3层的16个10x10的图分别进行以2x2为单位的下抽样得到16个5x5的图。连接的方式与S2层类似。
共有2x16=32个训练参数,5x5x5x16=2000个连接。
C5层是一个卷积层。
由于S4层的16个图的大小为5x5,与卷积核的大小相同,所以卷积后形成的图的大小为1x1。
这里形成120个卷积结果。每个都与上一层的16个图相连。
共有(5x5x16+1)x120 = 48120个参数,同样有48120个连接。
卷积核种类:120?
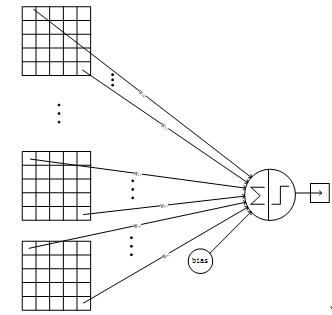
Figure 11 C5层的连接方式
F6层是全连接层。
F6层有84个节点,对应于一个7x12的比特图:-1表示白色,1表示黑色,这样每个符号的比特图的黑白色就对应于一个编码。
该层的训练参数和连接数是(120+1)x84=10164。

Figure 12 编码的比特图
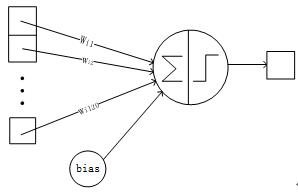
Figure 13 F6层的连接方式
Output层也是全连接层
共有10个节点,分别代表数字0到9,且如果节点i的值为0,则网络识别的结果是数字i。
采用的是径向基函数(RBF)的网络连接方式。假设x是上一层的输入,y是RBF的输出,则RBF输出的计算方式是:
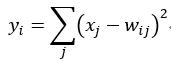
的值由i的比特图编码确定。越接近于0,则越接近于,即越接近于i的比特图编码,表示当前网络输入的识别结果是字符i。
该层有84x10=840个设定的参数和连接。
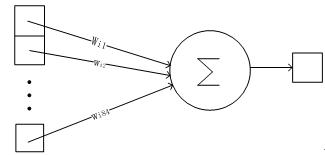
Figure 14 Output层的网络连接方式
理解难点:http://blog.csdn.net/u010555688/article/details/24848367
Output层由欧式径向基函数(Euclidean Radial Basis Function)单元组成,每类一个单元,每个有84个输入。换句话说,每个输出RBF单元计算输入向量和参数向量之间的欧式距离。输入离参数向量越远,RBF输出的越大。一个RBF输出可以被理解为衡量输入模式和与RBF相关联类的一个模型的匹配程度的惩罚项。用概率术语来说,RBF输出可以被理解为F6层配置空间的高斯分布的负log-likelihood。给定一个输入模式,损失函数应能使得F6的配置与RBF参数向量(即模式的期望分类)足够接近。这些单元的参数是人工选取并保持固定的(至少初始时候如此)。这些参数向量的成分被设为-1或1。虽然这些参数可以以-1和1等概率的方式任选,或者构成一个纠错码,但是被设计成一个相应字符类的7*12大小(即84)的格式化图片。这种表示对识别单独的数字不是很有用,但是对识别可打印ASCII集中的字符串很有用。
用这种分布编码而非更常用的“1 of N”编码用于产生输出的另一个原因是,当类别比较大的时候,非分布编码的效果比较差。原因是大多数时间非分布编码的输出必须为0。这使得用sigmoid单元很难实现。另一个原因是分类器不仅用于识别字母,也用于拒绝非字母。使用分布编码的RBF更适合该目标。因为与sigmoid不同,他们在输入空间的较好限制的区域内兴奋,而非典型模式更容易落到外边。
RBF参数向量起着F6层目标向量的角色。需要指出这些向量的成分是+1或-1,这正好在F6 sigmoid的范围内,因此可以防止sigmoid函数饱和。实际上,+1和-1是sigmoid函数的最大弯曲的点处。这使得F6单元运行在最大非线性范围内。必须避免sigmoid函数的饱和,因为这将会导致损失函数较慢的收敛和病态问题。
以上是LeNet-5的卷积神经网络的完整结构,共约有60,840个训练参数,340,908个连接。一个数字识别的效果如Figure 15所示。
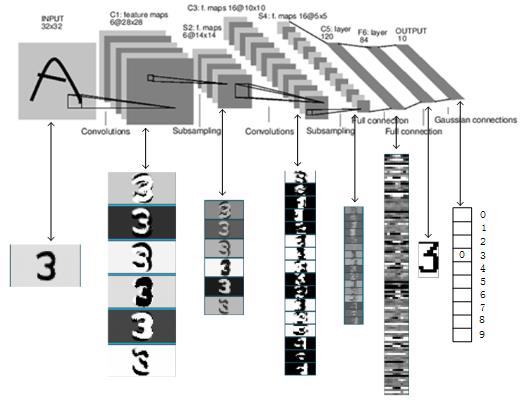
Figure 15 LeNet-5识别数字3的过程
通过对LeNet-5的网络结构的分析,可以直观地了解一个卷积神经网络的构建方法,为分析、构建更复杂、更多层的卷积神经网络做准备。
三、a Convolutional Neural Network - 精简版的LeNet-5
一个示例:Code
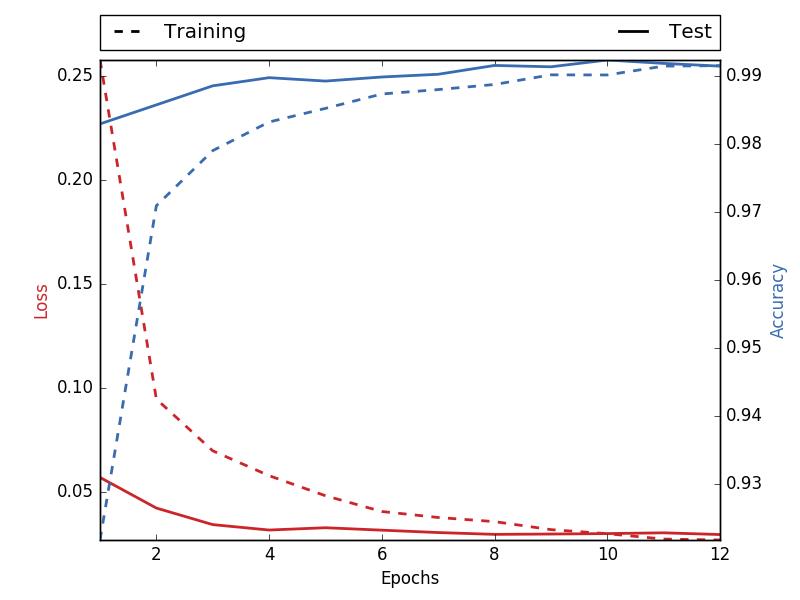
#Evaluate how the model does on the test set
score = model.evaluate(X_test, Y_test, verbose=0)
print(\'Test score:\', score[0])
print(\'Test accuracy:\', score[1])
Result:
另一个示例:
#coding:utf-8
\'\'\'
GPU run command:
THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32 python cnn.py
CPU run command:
python cnn.py
\'\'\'
#导入各种用到的模块组件
from __future__ import absolute_import
from __future__ import print_function
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.advanced_activations import PReLU
from keras.layers.convolutional import Convolution2D, MaxPooling2D
from keras.optimizers import SGD, Adadelta, Adagrad
from keras.utils import np_utils, generic_utils
from six.moves import range
from data import load_data
import random
import numpy as np
np.random.seed(1024) # for reproducibility
#加载数据
data, label = load_data()
#打乱数据
index = [i for i in range(len(data))]
random.shuffle(index)
data = data[index]
label = label[index]
print(data.shape[0], \' samples\')
#label为0~9共10个类别,keras要求格式为binary class matrices,转化一下,直接调用keras提供的这个函数
label = np_utils.to_categorical(label, 10)
###############
#开始建立CNN模型
###############
#生成一个model
model = Sequential()
#【第一个卷积层】,4个卷积核,每个卷积核大小5*5。1表示输入的图片的通道,灰度图为1通道。
#border_mode可以是valid或者full,参见这里:http://blog.csdn.net/niuwei22007/article/details/49366745
#激活函数用tanh
#你还可以在model.add(Activation(\'tanh\'))后加上dropout的技巧: model.add(Dropout(0.5))
model.add(Convolution2D(4, 5, 5, border_mode=\'valid\',input_shape=(1,28,28)))
model.add(Activation(\'tanh\'))
#【第二个卷积层】,8个卷积核,每个卷积核大小3*3。4表示输入的特征图个数,等于上一层的卷积核个数
#激活函数用tanh
#采用maxpooling,poolsize为(2,2)
model.add(Convolution2D(8, 3, 3, border_mode=\'valid\'))
model.add(Activation(\'tanh\'))
model.add(MaxPooling2D(pool_size=(2, 2)))
#【第三个卷积层】,16个卷积核,每个卷积核大小3*3
#激活函数用tanh
#采用maxpooling,poolsize为(2,2)
model.add(Convolution2D(16, 3, 3, border_mode=\'valid\'))
model.add(Activation(\'relu\'))
model.add(MaxPooling2D(pool_size=(2, 2)))
#【全连接层】,先将前一层输出的二维特征图flatten为一维的。
#Dense就是隐藏层。16就是上一层输出的特征图个数。4是根据每个卷积层计算出来的:(28-5+1)得到24,(24-3+1)/2得到11,(11-3+1)/2得到4
#全连接有128个神经元节点,初始化方式为normal
model.add(Flatten())
model.add(Dense(128, init=\'normal\'))
model.add(Activation(\'tanh\'))
#【Softmax分类】,输出是10类别
model.add(Dense(10, init=\'normal\'))
model.add(Activation(\'softmax\'))
#############
#开始训练模型
##############
#使用SGD + momentum
#model.compile里的参数loss就是损失函数(目标函数)
sgd = SGD(lr=0.05, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss=\'categorical_crossentropy\', optimizer=sgd,metrics=["accuracy"])
#调用fit方法,就是一个训练过程. 训练的epoch数设为10,batch_size为100.
#数据经过随机打乱shuffle=True。verbose=1,训练过程中输出的信息,0、1、2三种方式都可以,无关紧要。show_accuracy=True,训练时每一个epoch都输出accuracy。
#validation_split=0.2,将20%的数据作为验证集。
model.fit(data, label, batch_size=100, nb_epoch=10,shuffle=True,verbose=1,validation_split=0.2)
End.
以上是关于[Keras] mnist with cnn的主要内容,如果未能解决你的问题,请参考以下文章