TF Boys (TensorFlow Boys ) 养成记
Posted Charles-Wan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TF Boys (TensorFlow Boys ) 养成记相关的知识,希望对你有一定的参考价值。
圣诞节玩的有点嗨,差点忘记更新。祝大家昨天圣诞节快乐,再过几天元旦节快乐。
来继续学习,在/home/your_name/TensorFlow/cifar10/ 下新建文件夹cifar10_train,用来保存训练时的日志logs,继续在/home/your_name/TensorFlow/cifar10/ cifar10.py中输入如下代码:
def train(): # global_step global_step = tf.Variable(0, name = \'global_step\', trainable=False) # cifar10 数据文件夹 data_dir = \'/home/your_name/TensorFlow/cifar10/data/cifar-10-batches-bin/\' # 训练时的日志logs文件,没有这个目录要先建一个 train_dir = \'/home/your_name/TensorFlow/cifar10/cifar10_train/\' # 加载 images,labels images, labels = my_cifar10_input.inputs(data_dir, BATCH_SIZE) # 求 loss loss = losses(inference(images), labels) # 设置优化算法,这里用 SGD 随机梯度下降法,恒定学习率 optimizer = tf.train.GradientDescentOptimizer(LEARNING_RATE) # global_step 用来设置初始化 train_op = optimizer.minimize(loss, global_step = global_step) # 保存操作 saver = tf.train.Saver(tf.all_variables()) # 汇总操作 summary_op = tf.merge_all_summaries() # 初始化方式是初始化所有变量 init = tf.initialize_all_variables() os.environ[\'CUDA_VISIBLE_DEVICES\'] = str(0) config = tf.ConfigProto() # 占用 GPU 的 20% 资源 config.gpu_options.per_process_gpu_memory_fraction = 0.2 # 设置会话模式,用 InteractiveSession 可交互的会话,逼格高 sess = tf.InteractiveSession(config=config) # 运行初始化 sess.run(init) # 设置多线程协调器 coord = tf.train.Coordinator() # 开始 Queue Runners (队列运行器) threads = tf.train.start_queue_runners(sess = sess, coord = coord) # 把汇总写进 train_dir,注意此处还没有运行 summary_writer = tf.train.SummaryWriter(train_dir, sess.graph) # 开始训练过程 try: for step in xrange(MAX_STEP): if coord.should_stop(): break start_time = time.time() # 在会话中运行 loss _, loss_value = sess.run([train_op, loss]) duration = time.time() - start_time # 确认收敛 assert not np.isnan(loss_value), \'Model diverged with loss = NaN\' if step % 30 == 0: # 本小节代码设置一些花哨的打印格式,可以不用管 num_examples_per_step = BATCH_SIZE examples_per_sec = num_examples_per_step / duration sec_per_batch = float(duration) format_str = (\'%s: step %d, loss = %.2f (%.1f examples/sec; %.3f \' \'sec/batch)\') print (format_str % (datetime.now(), step, loss_value, examples_per_sec, sec_per_batch)) if step % 100 == 0: # 运行汇总操作, 写入汇总 summary_str = sess.run(summary_op) summary_writer.add_summary(summary_str, step) if step % 1000 == 0 or (step + 1) == MAX_STEP: # 保存当前的模型和权重到 train_dir,global_step 为当前的迭代次数 checkpoint_path = os.path.join(train_dir, \'model.ckpt\') saver.save(sess, checkpoint_path, global_step=step) except Exception, e: coord.request_stop(e) finally: coord.request_stop() coord.join(threads) sess.close() def evaluate(): data_dir = \'/home/your_name/TensorFlow/cifar10/data/cifar-10-batches-bin/\' train_dir = \'/home/your_name/TensorFlow/cifar10/cifar10_train/\' images, labels = my_cifar10_input.inputs(data_dir, BATCH_SIZE, train = False) logits = inference(images) saver = tf.train.Saver(tf.all_variables()) os.environ[\'CUDA_VISIBLE_DEVICES\'] = str(0) config = tf.ConfigProto() config.gpu_options.per_process_gpu_memory_fraction = 0.2 sess = tf.InteractiveSession(config=config) coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(sess = sess, coord = coord) # 加载模型参数 print("Reading checkpoints...") ckpt = tf.train.get_checkpoint_state(train_dir) if ckpt and ckpt.model_checkpoint_path: ckpt_name = os.path.basename(ckpt.model_checkpoint_path) global_step = ckpt.model_checkpoint_path.split(\'/\')[-1].split(\'-\')[-1] saver.restore(sess, os.path.join(train_dir, ckpt_name)) print(\'Loading success, global_step is %s\' % global_step) try: # 对比分类结果,至于为什么用这个函数,后面详谈 top_k_op = tf.nn.in_top_k(logits, labels, 1) true_count = 0 step = 0 while step < 157: if coord.should_stop(): break predictions = sess.run(top_k_op) true_count += np.sum(predictions) step += 1 precision = true_count / 10000 print(\'%s: precision @ 1 = %.3f\' % (datetime.now(), precision)) except tf.errors.OutOfRangeError: coord.request_stop() finally: coord.request_stop() coord.join(threads) sess.close() if __name__ == \'__main__\': if TRAIN: train () else: evaluate()
现在说明一下 in_top_k 这个函数的作用,官方文档介绍中: tf.nn.in_top_k(predictions, targets, k, name=None)这个函数返回一个 batch_size 大小的布尔矩阵 array,predictions 是一个 batch_size*classes 大小的矩阵,targets 是一个 batch_size 大小的类别 index 矩阵,这个函数的作用是,如果 targets[i] 是 predictions[i][:] 的前 k 个最大值,则返回的 array[i] = True, 否则,返回的 array[i] = False。可以看到,在上述评估程序 evaluate 中,这个函数没有用 softmax 的结果进行计算,而是用 inference 最后的输出结果(一个全连接层)进行计算。
写完之后,点击运行,可以看到,训练的 loss 值,从刚开始的 2.31 左右,下降到最终的 0.00 左右,在训练的过程中,/home/your_name/TensorFlow/cifar10/cifar10_train/ 文件夹下会出现12个文件,其中有 5 个 model.ckpt-0000 文件,这个是训练过程中保存的模型,后面的数字表示迭代次数,5 个 model.ckpt-0000.meta 文件,这个是训练过程中保存的元数据(暂时不清楚功能),TensorFlow 默认只保存近期的几个模型和几个元数据,删除前面没用的模型和元数据。还有个 checkpoint 的文本文档,和一个 out.tfevents 形式的文件,是summary 的日志文件。如果不想用 tensorboard 看网络结构和训练过程中的权重分布,损失情况等等,在程序中可以不写 summary 语句。
训练完成之后,我们用 tensorboard 进行可视化(事实上在训练的过程中,随时可以可视化)。在任意位置打开命令行终端,输入:
tensorboard --logdir=/home/your_name/TensorFlow/cifar10/cifar10_train/
会出现如下指示:
根据指示,打开浏览器,输入 http://127.0.1.1:6006(有的浏览器可能不支持,建议多换几个浏览器试试)会看到可视化的界面,有六个选项卡:
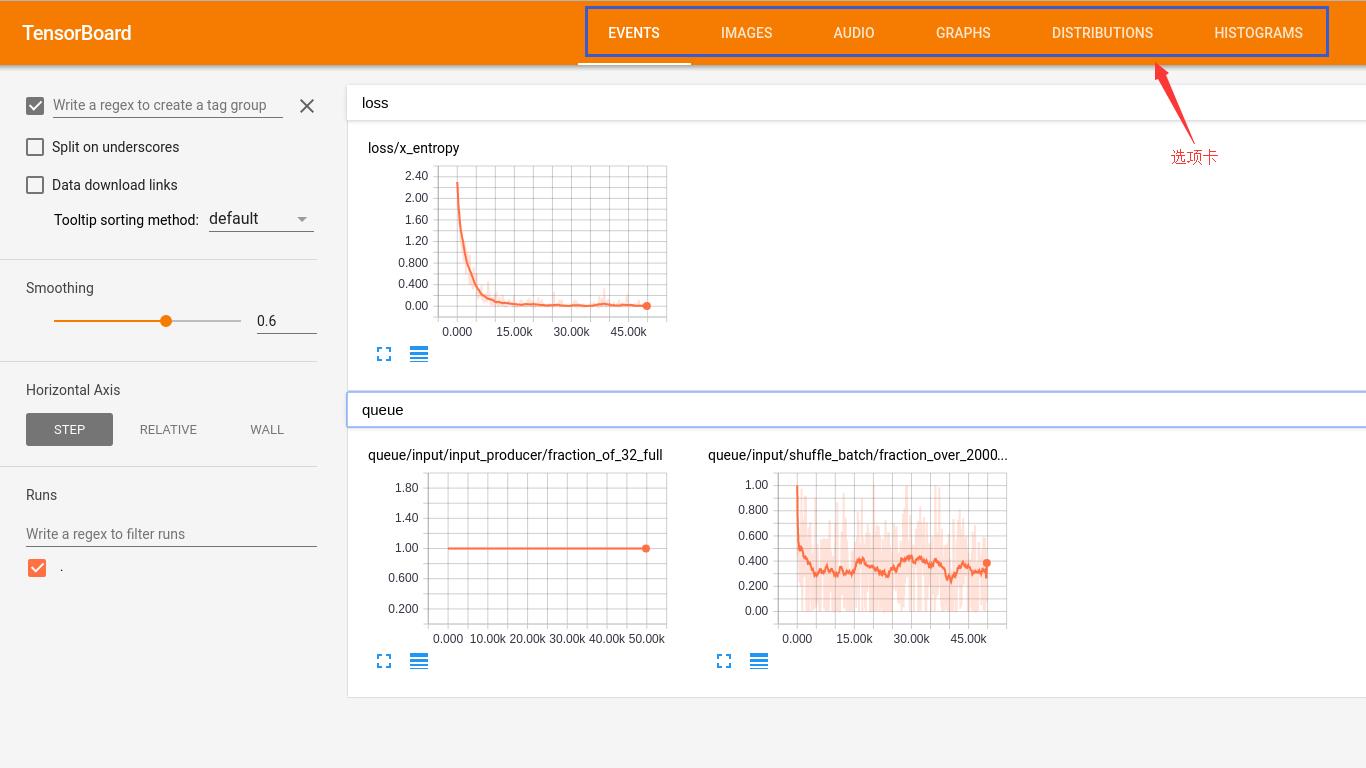
EVENTS 对话框里面有两个图,一个是训练过程中的 loss 图,一个是队列 queue 的图;由于没有 image_summary() 和 audio_summary() 语句,所以,IMAGES 和 AUDIO 选项卡都没有内容;GRAPHS 选项卡包含了整个模型的流程图,如下图,可以展开和移动选定的 namespace;DISTRBUTIONS 和 HISTOGRAMS 包含了训练时的各种汇总的分布和柱状图。

训练完之后,设置 TRAIN = False,进行测试,得到如下结果:

可以看到,测试的精度只有 76%,测试结果不够高的原因可能是,测试的时候没有经过 softmax 层,直接用全连接层的权重(存疑?),另外官方的代码也给出了官方的运行结果,如下:
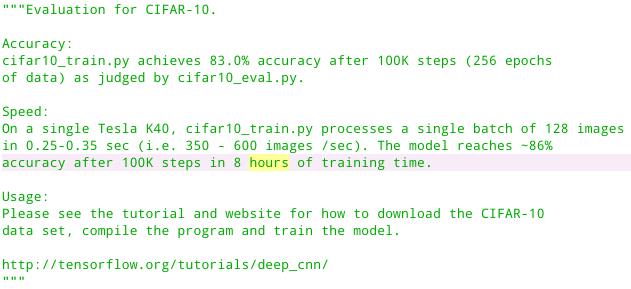
可以看到,经过 10 万次迭代,官方给出的正确率达到 83%,我们只进行了 5 万次,达到 76% 的正确率,相对来说,还算可以,效果没有官方好的原因可能是:
1. 官方使用了非固定的学习率;
2. 官方迭代比本代码迭代次数多一倍;
参考文献:
1. https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10
以上是关于TF Boys (TensorFlow Boys ) 养成记的主要内容,如果未能解决你的问题,请参考以下文章