NVMe over Fabrics又让RDMA技术火了一把
Posted rodenpark
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NVMe over Fabrics又让RDMA技术火了一把相关的知识,希望对你有一定的参考价值。
RDMA是个什么鬼?相信大部分不关心高性能网络的童鞋都不太了解。但是NVMe over Fabrics的出现让搞存储的不得不抽出时间来看看这个东西,这篇文章就来介绍下我所了解的RDMA。
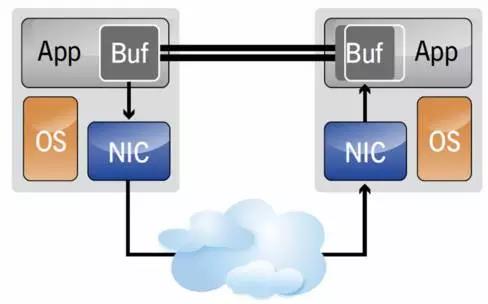
RDMA(Remote Direct Memory Access)意为在远端直接访问主机的内存,而不需要主机参与。如下图,当主机和Client端都配备RDMA NIC的时候,数据通过NIC的DMA引擎直接在两端内存之间转移,而不需要经过OS的网络协议栈。这种技术对于局域网高带宽的存储系统非常有吸引力。
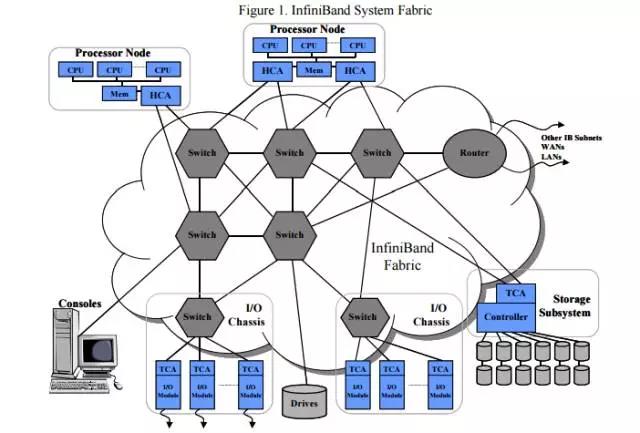
网络技术中,协议是必不可少的部分。RDMA环境下,传统的TCP/IP协议过于庞大,所以需要一种特殊的协议来发挥其优势,这就是InfiniBand协议(简称IB)。InfiniBand定义了一套完整的IB框架,这个框架中有我们在以太网中了解的大部分概念:交换机,路由器,子网络等。
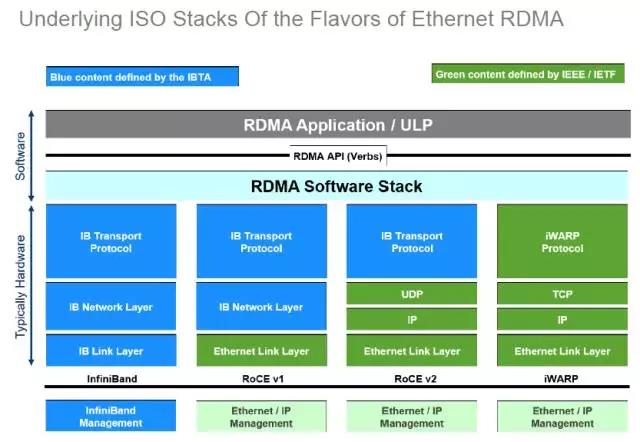
虽然InfiniBand看起来非常不错,但是组建一个IB网络,尤其当网络拓扑比较复杂的时候,对于习惯以太网的用户来说,在技术和成本方面花销太大。为了适应这方面的需求,IB组织在IB协议基础上增加了适用于以太网的协议:ROCE和iWARP。使用这两类协议就可以通过普通的以太网硬件组网。
这些协议的关系可以看下图,其中IB性能最好,ROCE则用得最多。无论是哪种技术,都必须保证RDMA的实现。
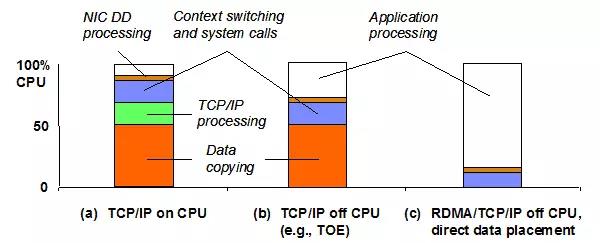
简单了解了RDMA,我们与传统的网卡对比来进一步说明。
普通的网卡都是基于OS的TCP/IP技术为上层提供网络服务。在Linux内核中,有一个著名的结构体sk_buff,这个结构体用来暂时存储传输的数据,它贯穿于内核网络协议栈和网卡驱动,用户的收发数据都要经过sk_buff。可以推断,这种设计至少需要一次内存copy,再加上TCP/IP等的处理,整个下来就造成了不少的overhead(引入的Latency和CPU处理时间)。
RDMA在编程模型上跟Socket有几分相似之处,比如都会使用Send和Receive交换信息。在RDMA中,还有一个Queue Pair(QP)的概念,每个QP由一个Send Queue和Receive Queue组成,Send Queue用来发送数据,Receive Queue则在另一端接收数据。在进行通信前,Server和Client端都需要建立这样的Queue Pair。RDMA支持多个QP,其数量限制由对应的网卡决定。
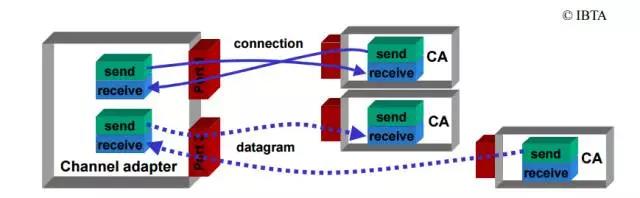
QP中的传输使用Work Request(WR)进行,而非数据流的形式。应用程序在Work Request中指定收发数据的地址(RDMA对数据存放的地址有要求,这些地址在使用前,必须注册到IB驱动中)。除此之外,QP的Send Queue和Receive Queue还需要配备一个Completion Queue,这个Completion Queue用来保存WR处理结果(发送或者收到),WR信息可以从Completion Queue中的Work Completion(WC)中获得。
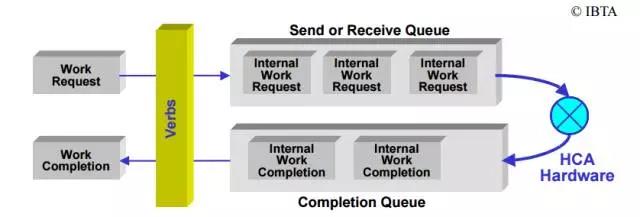
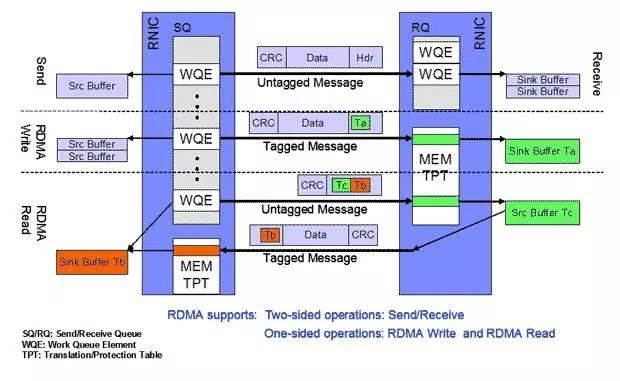
进一步讲,WR还分为Receive WR和Send WR,Receive WR用来指定另一端发过来的数据存放位置,Send WR则是实际的数据发送请求。在主机中注册的内存类型(ib_access_flags)决定了远端client操作主机内存的方式。如果具有Remote Access权限,则可以直接在Send WR中指定待操作的地址(此为RDMA Read/Write操作),主机无需参与操作;否则Send WR对远端地址没有控制权,即发送的数据的存放地址不由Send WR决定(只能Send/Recv操作),主机需要处理请求。使用哪种操作方式可以在ib_wr_opcode中指定。

这两种方式就是经常提到的one-sided和Two-sided。one-sided(RDMA Read/Write)相比于Two-sided的好处是释放了主机端的CPU,降低了传输的Latency。从下图可以看出,one-sided方式在主机端无需生成WQE,也就不需要处理Work Completion。
最后,我们回到NVMe over Fabrics,以client的一个写请求的处理过程来展示NVMf如何利用RDMA技术。
1,NVMe Queue与Client端RDMA QP一一对应,把NVMe Submission Queue中的NVMe Command存放到RDMA QP注册的内存地址中(有可能带上I/O Payload),然后通过RDMA Send Queue发送出去;
2,当Target的NIC收到Work Request后把NVMe Command DMA到Target RDMA QP注册的内存中,并在Targe的QP的Completion Queue中设置一个Work Completion。
3,Target处理Work Completion时,把NVMe Command发送到后端PCIe NVMe驱动,如果本次传输没有带上I/O Payload,则使用RDMA Read获取;
4,Target收到PCIe NVMe驱动处理结果后通过QP的Send Queue把NVMe Completion结果返回给client。
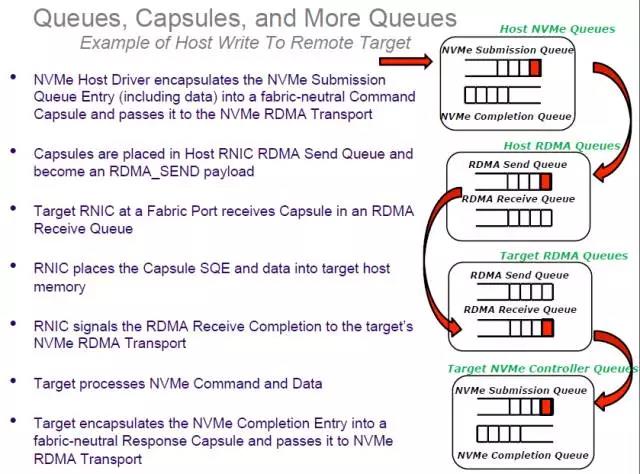
上面这个流程是当前NVMf的实现,可以看出,目前NVMe Command使用的是two-sided形式。一部分原因是Target端 CPU需要处理QP的Work Completion:将收到的NVMe 命令提交给PCIe NVMe驱动。如果把这一块能够offload,也许能够实现NVMf的one-sided传输,到时候性能会更强悍。
总结
这篇文章介绍了NVMf中最先实现的Transport-RDMA的部分技术细节。RDMA已经是一个成熟的技术,之前更多的是用在高性能计算中,而NVMe的出现,让它的使用范围迅速扩大。对于今天的存储从业者尤其是NVMe领域,了解RDMA技术对于跟进NVMe的发展趋势有比较大的帮助,希望这篇文章对您了解RDMA有一定的帮助,但是更多的RDMA技术细节还需要根据自己的需求去挖掘。
说明
本文最先发布于公众号《存储技术最前线》
感谢下列链接中的专家为本文中提供的素材
1, http://www.mellanox.com/pdf/whitepapers/IB_Intro_WP_190.pdf
2, How_Ethernet_RDMA_Protocols_Support_NVMe_over_Fabrics_Final,John Kim, Mellanox,under SINA.
3, RDMA programming concepts, OpenFabrics Alliance
4, https://www.zurich.ibm.com/sys/rdma/model.html
5, http://lxr.free-electrons.com/source/include/rdma/ib_verbs.h
相关阅读

以上是关于NVMe over Fabrics又让RDMA技术火了一把的主要内容,如果未能解决你的问题,请参考以下文章
NVMe over Fabrics 协议Discovery服务交互过程跟踪
iSCSI vs iSER vs NVMe-TCP vs NVMe-RDMA
iSCSI vs iSER vs NVMe-TCP vs NVMe-RDMA
iSCSI vs iSER vs NVMe-TCP vs NVMe-RDMA