统计单词出现的频率
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了统计单词出现的频率相关的知识,希望对你有一定的参考价值。
统计单词出现的频率
参考 《C程序设计语言》第6章 结构
#include <stdio.h> #include <ctype.h> #include <string.h> #include <stdlib.h> #define MAXWORD 100 #define BUFSIZE 100 char buf[BUFSIZE]; int bufp; struct tnode{ //树的节点 char *word; //指向单词的指针 int count; //单词出现的次数 struct tnode *left; //左子节点 struct tnode *right; //右子节点 }; int getch(void);//取一个字符,可能是压回的字符 void ungetch(int);//把字符压回到输入栈中 int getword(char *word,int lim);//从输入中读取下一个单词或字符 struct tnode *talloc(void); //addtree函数: 在p的位置或p的下方增加一个w节点 struct tnode *addtree(struct tnode *,char *); //treeprint函数: 按序打印树p void treeprint(struct tnode *); //统计关键字出现的次数; 采用指针方式的版本 int main(){ struct tnode *root; char word[MAXWORD]; root=NULL; while(getword(word,MAXWORD)!=EOF) if(isalpha(word[0])) { root=addtree(root,word); printf("%s\n",root->word); } treeprint(root); return 0; } //addtree函数: 在p的位置或p的下方增加一个w节点 struct tnode *addtree(struct tnode *p,char *w){ int cond; if(p==NULL){//该单词是一个新单词 p=talloc();//创建一个新节点 p->word=strdup(w); p->count=1; p->left=p->right=NULL; //printf("%s\n",p->word); //printf("%d\n",p->count); } else if((cond=strcmp(w,p->word))==0){ p->count++;//新单词与节点中的单词匹配 //printf("%s\n",p->word); //printf("%d\n",p->count); } else if(cond<0){//如果小于该节点的单词,则进入左子树 p->left=addtree(p->left,w); //printf("%s\n",p->word); //printf("%d\n",p->count); } else{ p->right=addtree(p->right,w);//如果大于该节点的单词,则进入右子树 //printf("%s\n",p->word); //printf("%d\n",p->count); } return p; } //talloc函数: 创建一个tnode struct tnode *talloc(void){ return (struct tnode *) malloc(sizeof(struct tnode)); } char *strdup(char *s){ char *p; p=(char *)malloc(strlen(s)+1);//执行加1操作是为了在结尾加上字符‘\0‘ if(p!=NULL) strcpy(p,s); return p; } int getword(char *word,int lim)//从输入中读取下一个单词或字符 { int c; char *w=word; while(isspace(c=getch())) ; if(c!=EOF) *w++=c; if(!isalpha(c)){ *w++=‘\0‘; return c; } for(;--lim>0;w++) if(!isalpha(*w=getch())){ ungetch(*w); break; } *w=‘\0‘; return word[0]; } //treeprint函数: 按序打印树p void treeprint(struct tnode *p){ if(p!=NULL){ treeprint(p->left); printf("%4d %s\n",p->count,p->word); treeprint(p->right); } } int getch(void){//取一个字符,可能是压回的字符 return bufp>0?buf[--bufp]:getchar(); } void ungetch(int c){//把字符压回到输入栈中 if(bufp>=BUFSIZE) printf("栈已满\n"); else buf[bufp++]=c; }
实验结果
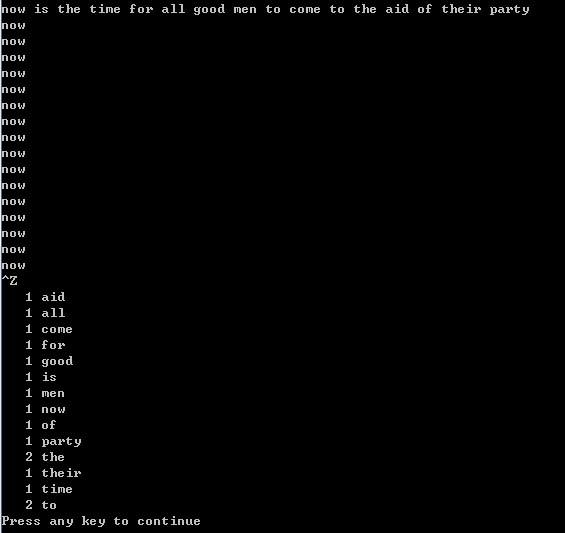
以上是关于统计单词出现的频率的主要内容,如果未能解决你的问题,请参考以下文章