Spark Streaming应用启动过程分析
Posted dabokele
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark Streaming应用启动过程分析相关的知识,希望对你有一定的参考价值。
本文为SparkStreaming源码剖析的第三篇,主要分析SparkStreaming启动过程。
在调用StreamingContext.start方法后,进入JobScheduler.start方法中,各子元素start方法的调用顺序如下:
private var eventLoop : EventLoop[JobSchedulerEvent] = null
val listenerBus = new StreamingListenerBus()
private val jobGenerator = new JobGenerator(this)
eventLoop.start
listenerBus.start(ssc.sparkContext)
receiverTracker = new ReceiverTracker(ssc)
inputInfoTracker = new InputInfoTracker(ssc)
receiverTracker.start()
jobGenerator.start() 时序图如下:
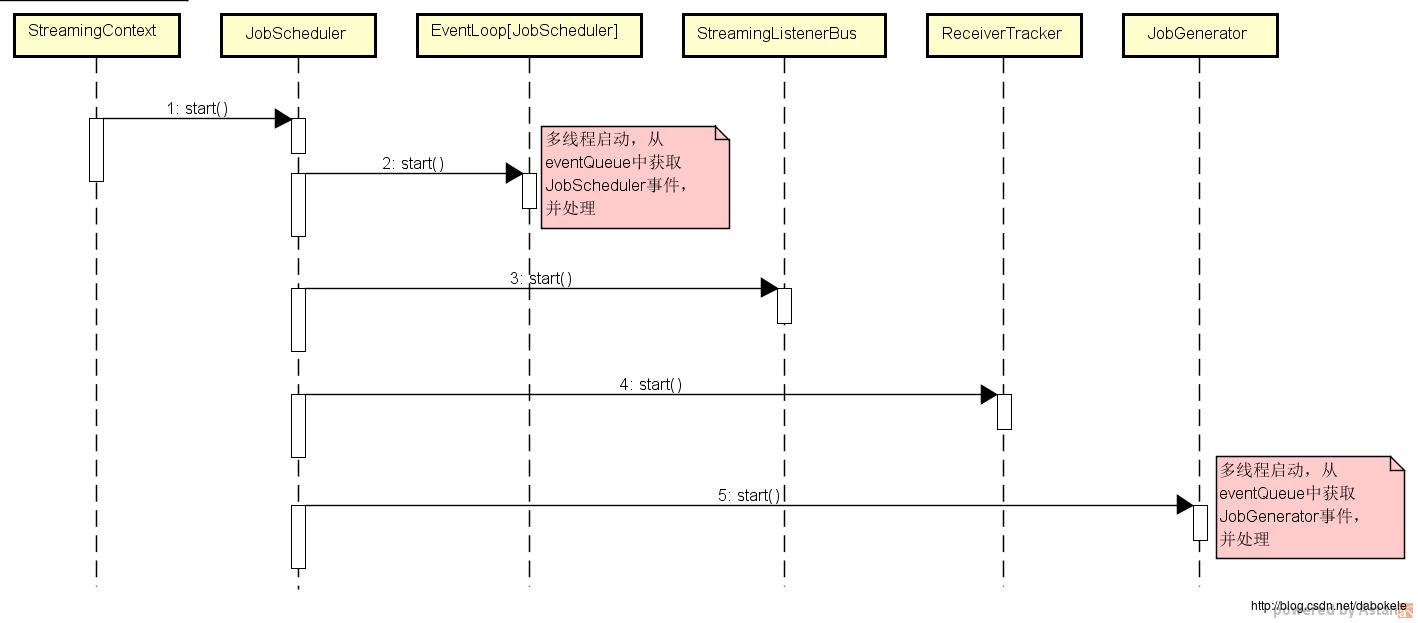
在eventLoop, listenerBus以及jobGenerator中都维持了一个事件队列,以多线程的形式从这些队列中取出事件并处理。一般来说,运行一个生产者消费者系统时, 往往先开始运行的是消费者。所以在上面的代码中,越是早start的对象,越不是Spark Streaming启动事件的入口。理解了这段话对于理解后续的启动过程分析是有帮助的。无法理解的话也可以先理解后续分析再回头想想这一点。
接下来分析上图中的主要对象。
一、JobGenerator类
JobGenerator的构造方法如下,使用到了前面提到的JobScheduler对象。
class JobGenerator(jobScheduler: JobScheduler) extends Logging 进入JobGenerator类。可以看到其start方法与JobScheduler的start方法结构十分类似。在这里面也有一个EventLoop类型的eventLoop对象,只不过这个对象传入的是JobGeneratorEvent类型的事件。
eventLoop = new EventLoop[JobGeneratorEvent]("JobGenerator") {
override protected def onReceive (event: JobGeneratorEvent): Unit = processEvent(event)
override protected def onError (e: Throwable ): Unit = {
jobScheduler.reportError("Error in job generator" , e)
}
}
eventLoop.start()1、eventLoop处理事件
看一眼JobGeneratorEvent,发现JobGenerator中的eventLoop主要处理的是Job生成,metadata以及checkpoint相关的事件。
private[scheduler] sealed trait JobGeneratorEvent
// 生成Jobs
private [scheduler] case class GenerateJobs(time: Time) extends JobGeneratorEvent
// 清除metadata
private [scheduler] case class ClearMetadata(time: Time) extends JobGeneratorEvent
// 设置checkpoint
private [scheduler] case class DoCheckpoint(
time: Time, clearCheckpointDataLater: Boolean) extends JobGeneratorEvent
// 清除checkpoint数据
private [scheduler] case class ClearCheckpointData(time: Time) extends JobGeneratorEvent 当JobGeneratorEvent对象开始执行时,会多线程启动eventLoop对象通过执行JobGenerator.processEvent方法处理JobGenerator事件。
看一下JobGenerator.processEvent方法中调用的JobGenerator.generateJobs方法是如何处理GenerateJobs事件的。
private def generateJobs (time: Time) {
Try {
// 获取JobScheduler中的receiverTracker对象,将接收到的batch事件分发出去
jobScheduler.receiverTracker.allocateBlocksToBatch(time)
// 获取StreamingContext中的graph对象,生成Jobs
graph.generateJobs(time) // generate jobs using allocated block
} match {
// 如果Jobs生成成功,则通过jobScheduler提交生成的JobSet
case Success(jobs) =>
val streamIdToInputInfos = jobScheduler.inputInfoTracker.getInfo(time)
jobScheduler.submitJobSet(JobSet(time, jobs, streamIdToInputInfos))
// 否则向jobScheduler返回一个报错信息
case Failure(e) =>
jobScheduler.reportError("Error generating jobs for time " + time , e)
}
// 最后,向eventLoop中提交一个检查点事件
eventLoop.post(DoCheckpoint(time, clearCheckpointDataLater = false))
} 有关ReceiverTracker.allocateBlocksToBatch方法的执行逻辑,可以参考前面有关ReceiverTracker的部分。
2、eventLoop接收事件
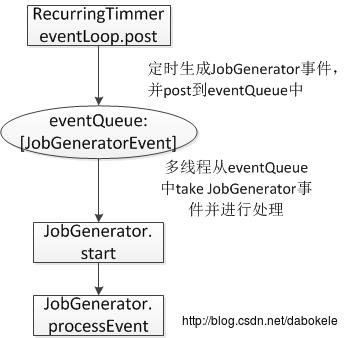
在JobGenerator类中有一个RecurringTimer类型的timer对象,这个对象以设置的batch duration定时往eventLoop中推送GenerateJobs事件,这样前面这个代码片段中的processEvent方法就可以处理这些事件了。
private val timer = new RecurringTimer(clock , ssc.graph.batchDuration.milliseconds ,
longTime => eventLoop.post(GenerateJobs(new Time(longTime))) , "JobGenerator") 另外,还可以看到,在JobGenerator.clearMetadata方法中,有提交检查点事件;在JobGenerator.onBatrchCompletion方法中,有提交清除metadata事件;在JobGenerator.onCheckpointCompletion方法中,有提交清除检查点数据事件。
在JobGenerator对象中的eventQueue生成和处理事件的流程图如下所示:
二、EventLoop[JobSchedulerEvent]类
1、JobSchedulerEvent类型
我们看一下eventLoop对象接收的事件类型JobSchedulerEvent都包含哪些,从下面代码中可以看出eventLoop对象主要是用来处理Job相关事件的。
private[scheduler] sealed trait JobSchedulerEvent
// Job开始
private [scheduler] case class JobStarted(job: Job , startTime: Long) extends JobSchedulerEvent
// Job结束
private [scheduler] case class JobCompleted(job: Job , completedTime: Long) extends JobSchedulerEvent
// 错误处理
private [scheduler] case class ErrorReported(msg: String , e: Throwable) extends JobSchedulerEvent2、事件队列eventQueue对象
(1)eventQueue处理事件
在EventLoop类中可以看到,里面维持了一个LinkedBlockingDeque类型的eventQueue事件队列,接收到的事件都存在该队列中。
当执行其start方法时,会多线程的执行EventLoop中的run方法。看一下其主要逻辑,
val event = eventQueue.take()
try {
onReceive(event)
} 从eventQueue中取出事件,调用EventLoop对象在JobScheduler中被重写的onReceive方法,最终进入JobScheduler.processEvent方法中。根据取出的不同事件类型,分别执行不同的逻辑。
private def processEvent (event: JobSchedulerEvent) {
try {
event match {
// 处理Job开始事件
case JobStarted(job , startTime) => handleJobStart(job , startTime)
// 处理Job完成事件
case JobCompleted(job , completedTime) => handleJobCompletion(job , completedTime)
// 处理Error事件
case ErrorReported(m , e) => handleError(m, e)
}
} catch {
case e: Throwable =>
reportError("Error in job scheduler" , e)
}
} 继续进入JobScheduler.handleJobStart方法。从这里看到,EventLoop取出对应事件后,最终是通过向listenerBus对象中post一个event作进一步处理的。有关这个listenerBus,可以参考下一节StreamingListenerBus类的分析。
private def handleJobStart (job: Job , startTime: Long) {
val jobSet = jobSets.get(job.time)
val isFirstJobOfJobSet = !jobSet.hasStarted
jobSet.handleJobStart(job)
if (isFirstJobOfJobSet) {
// "StreamingListenerBatchStarted" should be posted after calling "handleJobStart" to get the
// correct "jobSet.processingStartTime".
listenerBus.post(StreamingListenerBatchStarted(jobSet.toBatchInfo))
}
job.setStartTime(startTime)
listenerBus.post(StreamingListenerOutputOperationStarted(job.toOutputOperationInfo))
logInfo("Starting job " + job.id + " from job set of time " + jobSet.time)
}(2)eventQueue生成事件
EventLoop是从eventQueue中取出事件,那么往eventQueue队列中存入事件的是谁?
从JobScheduler类中的私有类JobHandler的run方法中可以看到,这里有_eventLoop.post(JobStarted(job, clock.getTimeMillis())以及_eventLoop.post(JobCompleted(job, clock.getTimeMillis())方法,分别往eventQueue队列中存入JobStarted和JobCompleted方法。
eventQueue中的事件生成和处理流程图如下。
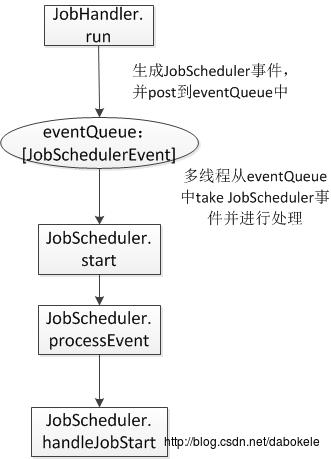
那么,我们只需要关注这个JobHandler.run方法是怎么执行起来的就行了。从下面的方法链中可以看到往EventLoop中提交JobSchedulerEvent的入口。从前面可以看到JobGenerator.start方法也是在JobScheduler.start方法中被执行起来的。
JobGenerator.start
---->JobGenerator.processEvent
-------->JobGenerator.generateJobs
------------>JobScheduler.submitJobSet
---------------->JobSet.jobs.foreach(job => jobExecutor.execute( new JobHandler(job)))JobGenerator中也维持了一个eventLoop对象,只不过这个对象处理的是JobGeneratorEvent事件。对于JobGenerator的进一步分析可以参考第四节。
三、StreamingListenerBus类
StreamingListenerBus是真正对这些不同场景的事件进行分发处理的对象。有关ListenerBus可以参考 Spark-1.6.0之Application运行信息记录器JobProgressListener。
1、eventQueue 处理事件
StreamingListenerBus类继承自AsynchronouseListenerBus,进入StreamingListenerBus类,可以看到其中有一个onPostEvent方法,通过接收到不同的StreamingListenerEvent事件,调用不同的逻辑进行处理不同的事件。
override def onPostEvent (listener: StreamingListener , event: StreamingListenerEvent): Unit = {
event match {
// 启动receiver
case receiverStarted: StreamingListenerReceiverStarted =>
listener.onReceiverStarted(receiverStarted)
// receiver出错
case receiverError: StreamingListenerReceiverError =>
listener.onReceiverError(receiverError)
// 停止receiver
case receiverStopped: StreamingListenerReceiverStopped =>
listener.onReceiverStopped(receiverStopped)
// 提交batch
case batchSubmitted: StreamingListenerBatchSubmitted =>
listener.onBatchSubmitted(batchSubmitted)
// 启动batch
case batchStarted: StreamingListenerBatchStarted =>
listener.onBatchStarted(batchStarted)
// 结束batch
case batchCompleted: StreamingListenerBatchCompleted =>
listener.onBatchCompleted(batchCompleted)
// 启动输出操作
case outputOperationStarted: StreamingListenerOutputOperationStarted =>
listener.onOutputOperationStarted(outputOperationStarted)
// 输出操作完成
case outputOperationCompleted: StreamingListenerOutputOperationCompleted =>
listener.onOutputOperationCompleted(outputOperationCompleted)
case _ =>
}
} 那么StreamingListenerBus是如何工作的呢?看一下其父类AsynchronousListenerBus,其中有一个eventQueue对象,
private val EVENT_QUEUE_CAPACITY = 10000
private val eventQueue = new LinkedBlockingQueue[E](EVENT_QUEUE_CAPACITY) eventQueue对象用于存储StreamingListenerEvent事件。这些事件基本上都在上面代码中有描述。
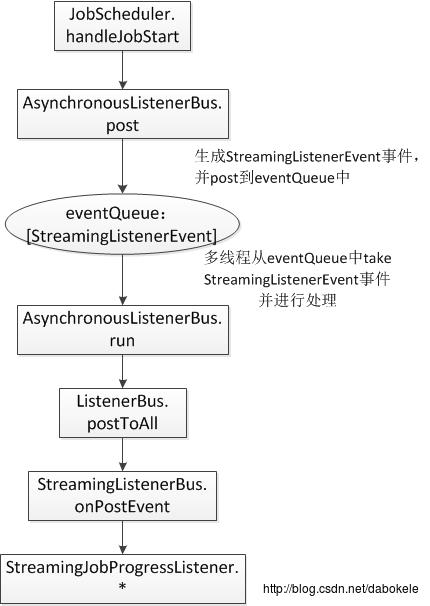
当JobScheduler对象中调用StreamingListenerBus.start多线程启动该对象后,就会在AsynchronousListenerBus.run方法中从eventQueue取出事件,并最终调用到上面代码中的StreamingListenerBus.onPostEvent方法。
具体调用链路如下:
AsynchronousListenerBus.run
---->ListenerBus.postToAll
-------->StreamingListenerBus.onPostEvent
------------>StreamingJobProgressListener.* 到这里,主要分析了StreamingListenerBus类中eventQueue中的事件是如何被后续处理的,那么eventQueue中的事件是如何生成的呢?
2、eventQueue接收事件
在第一节中JobScheduler.processEvent方法之后,程序处理逻辑就进入到这里了。在JobScheduler.processEvent方法中我们已经介绍过如何JobScheduler.handleJobStart方法了。
根据eventLoop中接收到的不同类型JobSchedulerEvent,最终调用不同的代码处理不同的事件。下面代码主要处理的是JobStarted类型事件。
val listenerBus = new StreamingListenerBus()
private def handleJobStart (job: Job , startTime: Long ) {
val jobSet = jobSets.get(job.time)
val isFirstJobOfJobSet = !jobSet.hasStarted
jobSet.handleJobStart(job)
if (isFirstJobOfJobSet) {
// 往StreamingListenerBus对象的eventQueue中提交事件
listenerBus.post(StreamingListenerBatchStarted(jobSet.toBatchInfo))
}
job.setStartTime(startTime)
// 往StreamingListenerBus对象的eventQueue中提交事件
listenerBus.post(StreamingListenerOutputOperationStarted(job.toOutputOperationInfo))
logInfo("Starting job " + job.id + " from job set of time " + jobSet.time)
} 在调用listenerBus.post方法后,将进入到AsynchronousListenerBus.post方法.
def post (event: E) {
if ( stopped.get) {
// Drop further events to make `listenerThread` exit ASAP
logError( s" $name has already stopped! Dropping event $ event" )
return
}
// 向eventQueue中提交事件
val eventAdded = eventQueue.offer(event)
if (eventAdded) {
eventLock.release()
} else {
onDropEvent(event)
}
} 有关StreamingListenerBus的处理逻辑如下图所示:
最终结合JobGenerator, JobScheduler以及StreamingListenerBus的事件流程图如下:
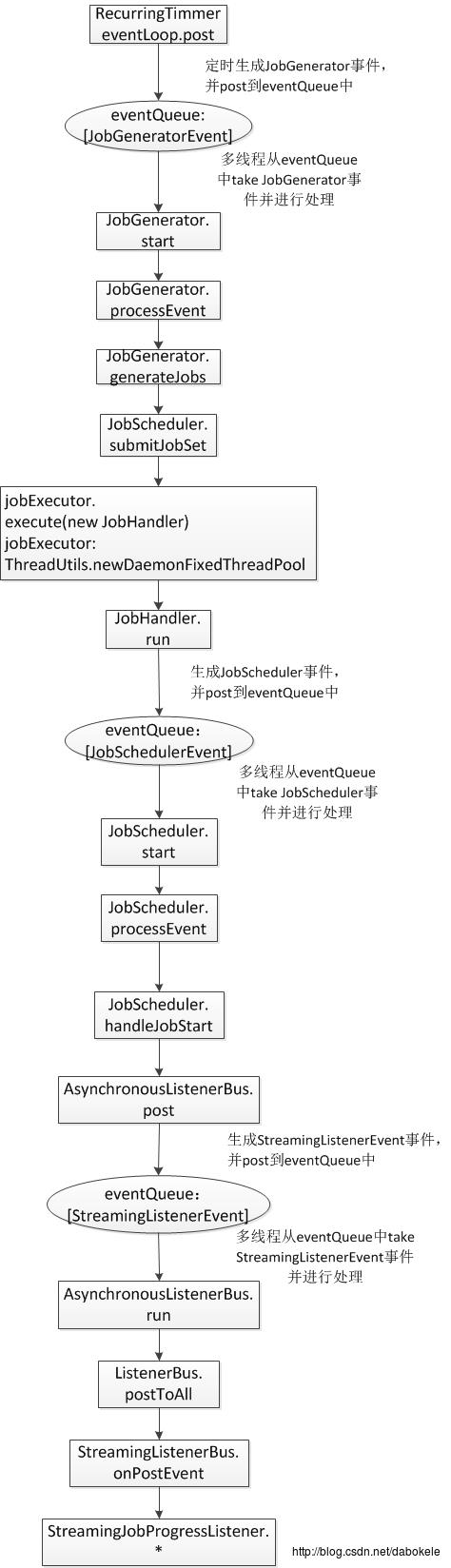
到这里,通过分析上面三个类型对象我们已经知道了Spark Streaming应用的启动过程。其他Spark应用一般是以一个RDD为源头,经过一系列的Transform和Action操作后,最终通过DAGScheduler、TaskScheduler等组件运行起来(具体可以参考 Spark Scheduler模块源码分析之DAGScheduler和 Spark Scheduler模块源码分析之TaskScheduler和SchedulerBackend)。
但是对于Spark Streaming应用,需要处理的数据并不是在应用运行起来前所确定的,并且上述对Spark Streaming应用的启动过程分析中也并没有涉及到处理的数据是如何输入的。那么Streaming应用的数据是如何进入应用的呢?请继续分析接下来的ReceiverTracker类。
四、ReceiverTracker类
ReceiverTracker对象在JobScheduler.start方法中new出来,随后调用start方法进入ReceiverTracker的逻辑。
receiverTracker = new ReceiverTracker(ssc)
receiverTracker.start() ReceiverTracker主要用于处理所有ReceiverInputDStreams中的receivers接收数据的逻辑。
1、接收输入数据
(1) ReceiverTracker.start方法
ReceiverTracker.start方法的主要逻辑是调用了ReceiverTracker.launchReceivers。这个方法处理receiverInputStreams中的每一个receiver后,分发到worker节点,启动并运行。
private def launchReceivers (): Unit = {
val receivers = receiverInputStreams.map(nis => {
val rcvr = nis.getReceiver() // 对不同的数据源有其具体实现
rcvr.setReceiverId(nis.id)
rcvr
})
// 在非local模式下,运行一段逻辑运算,确保所有的slaves都起来后再继续执行,避免了将receivers分配到同一节点上
runDummySparkJob()
logInfo("Starting " + receivers.length + " receivers")
// endpoint是RpcEndpointRef类型,通过它将receivers分发到worker节点
endpoint.send(StartAllReceivers(receivers))
}( 2)ReceiverTrackerEndpoint.receive方法
在endpoint.send方法被调用后,根据传入的对象类型,将进入ReceiverTrackerEndpoint.receive方法中,处理启动所有Receivers的事件。
override def receive : PartialFunction[Any , Unit] = {
// 处理StartAllReceivers事件
case StartAllReceivers(receivers) =>
val scheduledLocations = schedulingPolicy.scheduleReceivers(receivers , getExecutors)
for (receiver <- receivers) {
val executors = scheduledLocations(receiver.streamId)
updateReceiverScheduledExecutors(receiver.streamId, executors)
receiverPreferredLocations (receiver.streamId) = receiver.preferredLocation
startReceiver(receiver, executors)
}
case RestartReceiver(receiver) =>
...
} 最后进入ReceiverTracker.startReceiver方法。
private def startReceiver (
receiver: Receiver[_],
scheduledLocations: Seq [TaskLocation]): Unit = {
...
// 取出每一个Receiver对象
val receiver = iterator.next()
assert(iterator.hasNext == false)
val supervisor = new ReceiverSupervisorImpl(receiver, SparkEnv.get , serializableHadoopConf.value, checkpointDirOption)
supervisor.start()
supervisor.awaitTermination()
...
} 在ReceiverSupervisor.start方法中,开始真正的启动Receivers。
def start () {
onStart()
startReceiver()
}
def startReceiver (): Unit = synchronized {
try {
if (onReceiverStart()) {
logInfo("Starting receiver" )
receiverState = Started
// 调用Receiver.onStart方法开始接收数据。对不同的DStream有具体的Receiver实现
receiver.onStart()
logInfo("Called receiver onStart" )
} else {
// The driver refused us
stop( "Registered unsuccessfully because Driver refused to start receiver " + streamId, None)
}
} catch {
case NonFatal(t) =>
stop("Error starting receiver " + streamId , Some(t))
}
} 在receiver.onStart方法处,Spark Streaming根据具体情况对应不同的实现类,进入具体的实现逻辑中。
本文中使用的是SocketInputDStream。对应的为SocketReceiver,SocketReceiver直接继承自Receiver类。
( 3)SocketReceiver.onStart方法
在这个方法中,启动一个线程不停的执行receive方法接收数据。
def onStart () {
// Start the thread that receives data over a connection
new Thread( "Socket Receiver") {
setDaemon(true)
override def run () { receive() }
}.start()
}
def receive() {
...
socket = new Socket(host , port)
logInfo("Connected to " + host + ":" + port)
val iterator = bytesToObjects(socket.getInputStream())
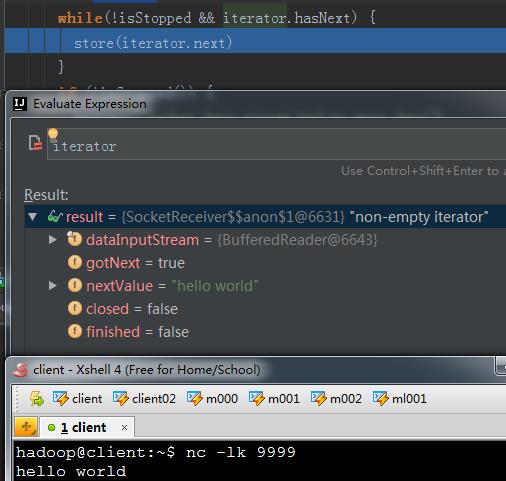
// 只有当这个连接存在,并且接收到数据时才会进入该逻辑。如下图所示
while (!isStopped && iterator.hasNext) {
store(iterator.next) // 接收一部分数据后,调用store方法将接收到的数据缓存到内存中
}
... 
( 4)ReceiverSupervisor后续流程
继续上一步中的Receiver.store方法
// Receiver.store方法
def store(dataItem: T ) {
supervisor.pushSingle(dataItem)
}后续将接收到的数据依次通过调用方法
ReceiverSupervisorImpl.pushSingle
----> BlockGenerator.addData 将接收到的数据放入一个ArrayBuffer缓存中。在将接收到的一条数据进行缓存之前,首先判断接收数据是否过于频繁,这个参数由spark.streaming.receiver.maxRate来控制,默认是Long.MaxValue。即如果数据产生速率超过Long.MaxValue,在对数据进行缓存时,就需要暂停等待一会。
@volatile private var currentBuffer = new ArrayBuffer[Any]
def addData (data: Any): Unit = {
// 在接收数据前判断是否接收数据太过频繁
waitToPush ()
...
currentBuffer += data
...
}
private val maxRateLimit = conf.getLong("spark.streaming.receiver.maxRate" , Long.MaxValue)
private lazy val rateLimiter = GuavaRateLimiter.create(maxRateLimit.toDouble)
def waitToPush() {
rateLimiter.acquire()
}到这里,就可以将数据源发送过来的数据接收到Spark Streaming应用中了。接下来需要考虑如何将数据缓存的数据取出来作后续逻辑处理。
2、处理数据
对缓存的数据进行处理的逻辑,主要是在BlockGenerator类中进行的。
同样使用本文中第一节JobGenerator中的RecurringTimer定时器,定时触发BlockGenerator.updateCurrentBuffer方法,处理currentBuffer对象中缓存的数据。这个时间间隔由spark.streaming.blockInterval参数确定,默认值为200ms。
private val blockIntervalMs = conf.getTimeAsMs("spark.streaming.blockInterval" , "200ms")
private val blockIntervalTimer =
new RecurringTimer(clock , blockIntervalMs, updateCurrentBuffer , "BlockGenerator")
private def updateCurrentBuffer (time: Long): Unit = {
var newBlock: Block = null
synchronized {
// 当前currentBuffer中有缓存数据时
if (currentBuffer.nonEmpty) {
// 接收currentBuffer中的对象
val newBlockBuffer = currentBuffer
// 清空currentBuffer对象
currentBuffer = new ArrayBuffer[Any]
val blockId = StreamBlockId(receiverId , time - blockIntervalMs )
listener.onGenerateBlock(blockId)
// 根据当前缓存的数据,生成newBlock对象
newBlock = new Block(blockId , newBlockBuffer)
}
}
if (newBlock != null) {
blocksForPushing.put(newBlock) // put is blocking when queue is full
}
} 上面讲newBlock对象缓存到blocksForPushing对象中。blocksForPushing对象中可以缓存若干个Block类型对象,即对应上面200ms时间内所接收到的数据形成的Block对象。具体Block对象个数由参数spark.streaming.blockQueueSize来确定,默认值为10。
private val blockQueueSize = conf.getInt("spark.streaming.blockQueueSize" , 10)
private val blocksForPushing = new ArrayBlockingQueue[Block](blockQueueSize) 这里blocksForPushing对象也是一个缓存队列,其中的数据由定时器定时put。并且有一个与之对应的线程专门从该队列中消费数据。
// 处理blocksForPushing队列的线程
private val blockPushingThread = new Thread() { override def run() { keepPushingBlocks() } }
// 该线程的运行逻辑
def start (): Unit = synchronized {
if ( state == Initialized) {
state = Active
// 启动定时器定时put数据
blockIntervalTimer.start()
// 启动消费线程消费缓存数据
blockPushingThread.start()
logInfo("Started BlockGenerator" )
}
}
// 消费数据逻辑
private def keepPushingBlocks () {
...
// 每10ms从blocksForPushing中取出一个对象
while (areBlocksBeingGenerated) {
Option(blocksForPushing.poll(10, TimeUnit.MILLISECONDS)) match {
case Some(block) => pushBlock(block)
case None =>
}
}
...
}
// 将当前取出的Block对象传入listener中
// listener: BlockGeneratorListener
private def pushBlock (block: Block) {
listener.onPushBlock(block.id, block.buffer)
logInfo("Pushed block " + block.id)
}
接下来进入ReceiverSupervisorImpl.pushArrayBuffer方法中。
在ReceiverSupervisorImpl类中,有以下四种push数据的处理方法。
/** 将单条记录push到block generator. */
def pushSingle(data: Any) {
defaultBlockGenerator .addData(data)
}
/** 将接收到的数据以ArrayBuffer形式缓存到Spark内存中 */
def pushArrayBuffer(
arrayBuffer: ArrayBuffer[_],
metadataOption: Option[Any] ,
blockIdOption: Option[StreamBlockId]
) {
pushAndReportBlock(ArrayBufferBlock(arrayBuffer) , metadataOption, blockIdOption)
}
/** 将接收到的数据以Iterator形式缓存到Spark内存中 */
def pushIterator(
iterator: Iterator [_] ,
metadataOption: Option[Any] ,
blockIdOption: Option[StreamBlockId]
) {
pushAndReportBlock(IteratorBlock(iterator) , metadataOption, blockIdOption)
}
/** 将接收到的数据以Bytes数据块形式缓存到Spark内存中 */
def pushBytes(
bytes: ByteBuffer,
metadataOption: Option[Any] ,
blockIdOption: Option[StreamBlockId]
) {
pushAndReportBlock(ByteBufferBlock(bytes) , metadataOption, blockIdOption)
}
/** 缓存数据块,并向Driver汇报 */
def pushAndReportBlock (
receivedBlock: ReceivedBlock,
metadataOption: Option[Any] ,
blockIdOption: Option[StreamBlockId]
) {
val blockId = blockIdOption.getOrElse(nextBlockId)
val time = System.currentTimeMillis
// 将接收到的数据封装成ReceivedBlock的形式发送给receiverBlockHandler进行缓存
val blockStoreResult = receivedBlockHandler.storeBlock(blockId , receivedBlock)
logDebug(s"Pushed block $ blockId in $ {(System.currentTimeMillis - time)} ms" )
val numRecords = blockStoreResult.numRecords
// 记录当前缓存block相关信息,并向Driver汇报
val blockInfo = ReceivedBlockInfo( streamId, numRecords , metadataOption , blockStoreResult)
trackerEndpoint.askWithRetry[ Boolean]( AddBlock(blockInfo))
logDebug(s"Reported block $ blockId" )
}以上是关于Spark Streaming应用启动过程分析的主要内容,如果未能解决你的问题,请参考以下文章
Spark Streaming源码解读之Receiver生成全生命周期彻底研究和思考
Spark 定制版:009~Spark Streaming源码解读之Receiver在Driver的精妙实现全生命周期彻底研究和思考