Kafka——性能逆天的存在
Posted _飞翔的企鹅_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka——性能逆天的存在相关的知识,希望对你有一定的参考价值。
Kafka——性能逆天的存在
0、引言
Kafka是LinkedIn开源出来的一款消息服务器,用scala语言实现;这货的性能是百万级的QPS(估计是挂载了多块磁盘),我随便写个测试程序就是十万级。
1、Kafka基本概念
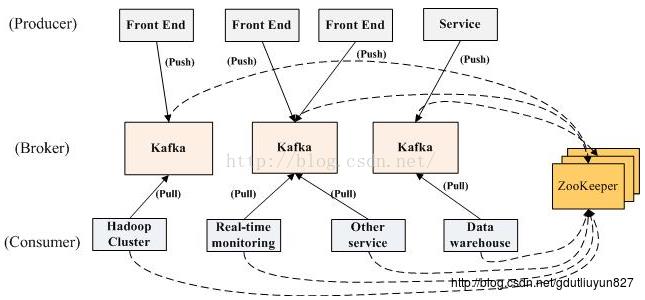
在Kafka中消息是按照Topic进行分类的;每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)。
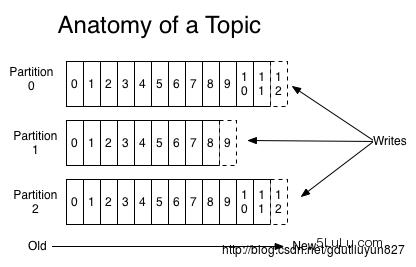
每个Topic包含一个或多个Parition;Parition是物理存储上的概念,创建Topic时可指定Parition数量。每个Parition对应一个存储文件夹,文件夹下存储该Parition所持有的消息数据和索引文件。Topic进行分区划分的主要目的是出于性能方面的考虑,Kafka尽量的使所有分区均匀的分布到集群所有的节点上而不是集中在某些节点上,另外主从关系也尽量均衡,这样每个节点都会担任一定比例的分区的Leader。每个Parition是一个有序的队列,每条消息在Parition中拥有一个offset。
消息的发布者可将消息发布到指定的Topic中,同时Producer也能决定将此消息发送到哪个Parition(也可以采取随机、哈希、轮训等策略)。
消息的消费者主动从Kafka中拉取消息进行消费(pull模式),在Kafka中一个Parition中的消息可以被无限多个消费者进行消费,每个消费者之间是完全独立,每个Consumer消费后的消息Kafka并不进行删除操作,Kafka中的消息删除是定期进行的,可以指定保留多长时间消息不被删除。通过指定offset就可以消费任意位置的消息,当然前提是指定的offset是存在的。从这点上看Kafka更像是一个只能追加、不能修改、支持随机读取的小文件管理系统。
上面提到每个Consumer是完全独立,如果多个Consume想轮流消费同一个Topic的同一个Parition就做不到;后来Kafka发明了一个Consumer-group的概念,每个Consumer客户端被创建时,会向Zookeeper注册自己的信息;一个group中的多个Consumer可以交错的消费一个Topic的所有Paritions;简而言之,保证此Topic的所有Paritions都能被此group所消费,且消费时为了性能考虑,让Parition相对均衡的分散到每个Consumer上,Consume-group之间是完全独立。主人的相反是挺好的,但是悲剧的是客户端基本都不支持,貌似只有java的客户端支持比较好。
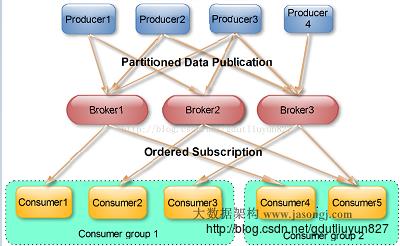
2、消息顺序性与可靠性设计
发布到Kafka的消息在一个Parition中是顺序存储的,发布者可以通过随机、哈希、轮训等方式发布到多个分区中,消费者通过指定offset进行消费;所以Kafka当中消息的顺序性更多的取决于使用方如何使用。
Kafka系统中消息支持容灾备份存储,每个Parition有主分区、备用分区的概念,一个Topic中的多个Parition的主分区可能落在不同的物理机器上面,Kafka也是尽量让其分布在不同的机器上以提高系统性能。消息的读写都是通过主分区直接完成,客户端要直连主分区所在的物理机进行读写操作。备用分区就像一个"Consumer"消费主分区的消息并保存在本地日志中进行备份;主分区负责跟踪所有的备用分区的状态,如果备用分区"落后"太多或者失效,主分区将会把它从同步列表中删除;主备分区的管理是通过zookeeper进行的。
发布时的可靠性取决于两点:发送端的确认机制、以及Kafka系统落地的策略。发送端支持无确认、主分区确认(主分区收到消息后发送确认回执)、以及主备分区确认(备用分区消息同步后主分区才发送确认回执)三种机制;Kafka系统落地的策略有两种刷盘方式:通过配置消息数、以及配置刷盘时间间隔。
消费时的可靠性取决于消费者的读取逻辑,Kafka是不保存消息的任何状态的。At most once、At least once 、Exactly once 三种模式需要自己按照业务实现,最容易实现就是At least once,两外两种在分布式系统中都不可能做到完全的绝对实现,只能无限靠近,降低错误率。
3、消息存储方式
Parition是以文件的形式存储在文件系统中,比如创建了一个名为tipocTest的Topic,其有4个Parition,在Kafka的数据目录下面会有四个文件夹,按照Topic-partnum命名。

每个文件夹的内容

Parition中的每条Message由offset来表示它在这个Parition中的偏移量,这个offset不是该Message在Parition数据文件中的实际存储位置,而是逻辑上一个值,它唯一确定了Parition中的一条Message。因此,可以认为offset是Parition中Message的id。Parition中的每条Message包含了三个属性: Offset 、DataSize 、Data;Parition的数据文件则包含了若干条上述格式的Message,按offset由小到大排列在一起;Kafka收到新的消息后追加到文件末尾即可,所以消息的发布效率是很高的。
下面我们来思考另一个问题,如果一个Parition只有一个数据文件会怎么样? 新消息是添加在文件末尾,不论文件数据文件有多大,这个操作永远都是O(1)。但是在读取的时候根据offset查找Message是顺序查找的,因此,如果数据文件很大的话,查找的效率就低。那么Kafka是如何解决查找效率的的问题呢?1) 分段、2) 索引。
4、数据文件的分段与索引
Kafka解决查询效率的手段之一是将数据文件分段,可以配置每个数据文件的最大值,每段放在一个单独的数据文件里面,数据文件以该段中最小的offset命名。这样在查找指定offset的Message的时候,用二分查找就可以定位到该Message在哪个段中。
数据文件分段使得可以在一个较小的数据文件中查找对应offset的Message了,但是这依然需要顺序扫描才能找到对应offset的Message。为了进一步提高查找的效率,Kafka为每个分段后的数据文件建立了索引文件,文件名与数据文件的名字是一样的,只是文件扩展名为.index。索引文件中包含若干个索引条目,每个条目表示数据文件中一条Message的索引——Offset与position(Message在数据文件中的绝对位置)的对应关系;index文件中并没有为数据文件中的每条Message建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。但缺点是没有建立索引的Message也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了。
每个分段还有一个.timeindex索引文件,这个文件的格式与.index文件格式一样,所记录的东西是消息发布时间与offset的稀疏索引,用于消息定期删除使用。
下图是一个分段索引的例子
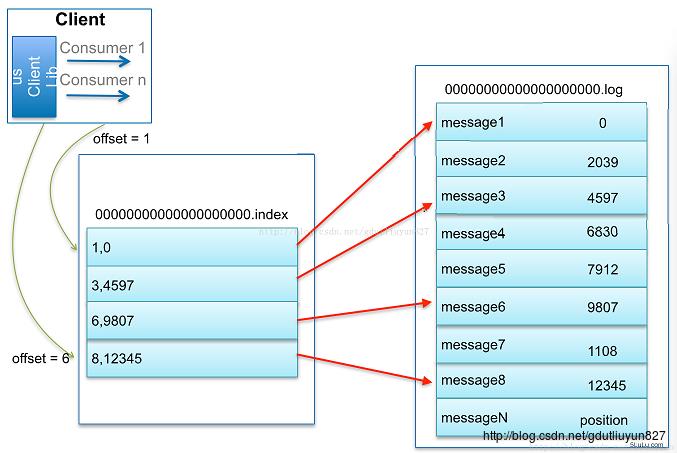
这套机制是建立在offset是有序的;索引文件被映射到内存中,所以查找的速度还是很快的。一句话,Kafka的Message存储采用了分区(Parition)、分段(segment)和稀疏索引这几个手段来达到高效发布和随机读取。
5、消费端设计
出于性能、容灾方面的考虑,实际需求是有多Consumer消费一个Topic的情况;由于多个Consumer之间是相互独立的,可以采用竞争Parition上岗的方式进行消费,同一个时刻只有一个Consumer在消费一个Parition,多个Consumer之间定期同步offset状态;如果是需要多通道消费,可以竞争不同的Parition对应资源上岗消费。
由于Kafka是按照offset进行读取的,一般的client都封装成:给定一个起始offset后续不停的get就可以顺序读取了,没有消费确认的概念,Kafka也不会维护每个消息、每个Consumer的状态。其实实现一套消费确认机制也不难,这需要我们实现一个proxy层,在proxy层保留一个循环缓冲区,业务端消费确认后方可从缓冲区里面移除,如果一段时间没有确认,下次来取的时候重复下发下去,类似于tcp滑动窗口的概念。
以上是关于Kafka——性能逆天的存在的主要内容,如果未能解决你的问题,请参考以下文章
阿里逆天级调优方案,内部这套Java性能调优实战宝典,堪称教科书