SQL Server--你可能不知道的技术细节:存储过程参数传递的影响
Posted ashin312
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL Server--你可能不知道的技术细节:存储过程参数传递的影响相关的知识,希望对你有一定的参考价值。
前言
---创建测试表 SELECT IDENTITY(INT,1,1) AS RID, * INTO TB1 FROM sys.all_columns GO ---模拟大量数据 INSERT INTO TB1 SELECT * FROM sys.all_columns GO 100 --在 user_type_id列 创建一个索引 CREATE NONCLUSTERED INDEX [NonClusteredIndex-20160625-164531] ON [dbo].[TB1] ( [user_type_id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO --开启IO统计 set statistics io on --测试查询执行计划 select * from tb1 where user_type_id = 10


测试一
--测试1:使用定义变量,把参数值传递给变量 create PROCEDURE dbo.USP_GetData ( @PID INT ) AS BEGIN DECLARE @ID INT SET @ID= @PID SELECT * FROM TB1 WHERE user_type_id = @ID END GO EXEC dbo.USP_GetData @PID=10


结论:如果在存储过程中定义变量,并为变量SET赋值,该变量的值无法为执行计划提供参考(即执行计划不考虑该变量),将会出现预估行数和实际行数相差过大导致执行计划不优的情况
测试二
---测试2 : 对参数进行运算 create PROCEDURE dbo.USP_GetData2 ( @PID INT ) AS BEGIN SET @PID=@PID-1 SELECT* FROM TB1 WHERE user_type_id = @PID END GO EXEC dbo.USP_GetData2 @PID=11


结论:如果在存储过程中使用SET为存储过程参数重新赋值,执行计划仍采用执行时传入的值来生成执行计划。
测试三
--测试3 :对参数行进拼接 create PROCEDURE dbo.USP_GetData3 ( @PID INT ) AS BEGIN DECLARE @ID INT set @ID = 2 SET @PID = @ID + @PID SELECT * FROM TB1 WHERE user_type_id = @PID END GO EXEC dbo.USP_GetData3 @PID= 8


结论:如果在存储过程中使用新定义的变量与传入参数拼接重新赋值,执行计划仍采用执行时传入的值来生成执行计划。
测试四
--测试4 : 对变量进行运算 create PROCEDURE dbo.USP_GetData4 ( @PID INT ) AS BEGIN SELECT * FROM TB1 WHERE user_type_id = @PID+ 2 END GO EXEC dbo.USP_GetData4 @PID=8


结论:虽然传入参数在传入后被修改,但是生成执行计划时仍使用传入时的值
测试五
--测试5 :对变量进行复杂运算 create PROCEDURE dbo.USP_GetData5 ( @PID INT ) AS BEGIN SELECT * FROM TB1 WHERE user_type_id = @PID+ CAST(RAND()*600 AS INT) END GO EXEC dbo.USP_GetData5 @PID=8 GO


结论:对参数做复杂运算,无法获得准确的值,因此不能准确地预估行数,也不能生成合理的执行计划
测试六
--测试6 : 复杂运算使用变量拼接 create PROCEDURE dbo.USP_GetData6 ( @PID INT ) AS BEGIN DECLARE @ID INT set @ID = CAST(RAND()*600 AS INT) SET @PID = @ID + @PID SELECT * FROM TB1 WHERE user_type_id = @PID END GO EXEC dbo.USP_GetData6 @PID=8 GO
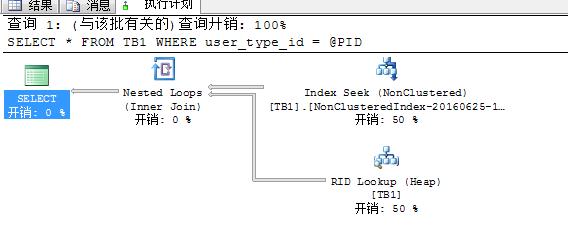

结论:针对测试五可以使用参数拼接的方式,以便准确地预估行数,使用正确的执行计划
总结
技术支持做了比较长的时间了,遇到了很多很多坑,在这些坑中不断反思,慢慢成长!不要说什么数据库更优秀,不要说我们海量数据库需要什么什么高端的技术,其实解决问题的关键只是那么一点点的基础知识。
注:本例中还有另外一种情况就是查询的数据量很大,那么本身走全表扫描是最优计划,而由于参数传递的问题错误的走了index seek + key look up 道理是一样的。
--------------博客地址-----------------------------------------------------------------------------
原文地址: http://www.cnblogs.com/double-K/
如有转载请保留原文地址!
----------------------------------------------------------------------------------------------------
注:此文章为原创,欢迎转载,请在文章页面明显位置给出此文链接!
以上是关于SQL Server--你可能不知道的技术细节:存储过程参数传递的影响的主要内容,如果未能解决你的问题,请参考以下文章
你可能不知道SQL Server索引列的升序和降序带来的性能问题