filebeat + logstash 对message提取指定字段
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了filebeat + logstash 对message提取指定字段相关的知识,希望对你有一定的参考价值。
参考技术A filebeat中message要么是一段字符串,要么在日志生成的时候拼接成json然后在filebeat中指定为json。但是大部分系统日志无法去修改日志格式,filebeat则无法通过正则去匹配出对应的field,这时需要结合logstash的grok来过滤,架构如下:以系统登录日志格式为例:
这里需要定义两个field,Status和ClientIP来获取某个IP登录服务器的频率和状态
而单filebeat输出信息为:
message为字符串,且filebeat无法通过正则匹配出想要的数据,所以filebeat只负责在服务器上收索转发日志数据,过滤功能则交给logstash来处理,配置如下:
filebeat_ssh.yaml
logstash_ssh.conf
Logstash:使用 Logshark 来调试 Logstash 及 Filebeat pipelines
我们知道 Logstash 及 Filebeat 在 Elasticsearch 数据摄入及清理中起到非常大的作用。它们是常用的工具用来对数据进行处理。我们可以运用 Logstash 丰富的过滤器来处理数据,我们也可以使用 Filebeat 的 processors 来处理数据。
使用这些工具(和其他工具)对管道进行编码是一个高度迭代的过程,特别是在处理 grok 模式以解析非结构化日志时:你获得一些示例数据,将其提供给 input,然后你将重复:
- 对管道逻辑进行编码( Logstash 中的过滤器和 Filebeat 中的处理器)
- 检查输出,直到日志被正确解析。
我一直觉得这个改变管道和检查输出的迭代周期有点慢 — 确保你在 Logstash 和 Filebeat 中都有控制台输出,但你最终会混合这些程序的输出和你的输出,你会肯定会滚动很多。 当然,这两种工具都有文件输出,但在处理包含数百个字段的文档时很容易迷失方向,因为每个文档都写在一行中,没有漂亮的打印。
我们需要一种方法来立即判断我们的管道输出是否正确,打印漂亮且可导航的输出是我的主要要求,如果我们有的话,我们的开发迭代会快得多! 这样的工具不存在。幸运的是,一个开源的项目 Logshark (灵感来自流行的网络检查工具 Wireshark)应运而生。

它是一个带有用 Go 编写的终端 UI 的 CLI 应用程序。它通过启动一个小型网络服务器来工作,该服务器通过接受 _bulk 请求模仿 Elasticsearch 的行为,因此你需要做的就是将 Logstash/Filebeat elasticsearch 输出重定向到该工具。
这个工具在更改生产管道时特别方便,因为你可以向管道添加第二个 elasticsearch 输出以检查事件,默认情况下它会收集它看到并接受的前 100 个事件,但丢弃其余的,你可以检查下一个通过点击 r (reset)来刷新它。
它还会告诉您每秒发生的事件数和平均文档大小,当你需要通过调整 bulk/batch 大小来优化吞吐量时,这些信息非常方便,如果你正在从南半球的机器收集日志,这就非常重要发送到北部的 Elasticsearch 集群。
你可以直接使用二进制文件 (<5mb) 或在 docker 上运行它。 UI 可以用于任何可以模拟终端的东西,比如你的常规 Linux 终端、iTerm、tmux、PuTTY 甚至 VSCode。
上手
启动服务器
我们可以参考网站 GitHub - ugosan/logshark: Logshark is a debugger for JSON logs. 下载最新的发布版。
二进制
./logshark --host 0.0.0.0 --port 9200 --max 1000上述命令将启动一个服务器。它侦听 9200 端口,也就是 Elasticsearch 运行的端口。我们需要停止自己的 Elasticsearch 运行,你运行 Logshark 和 Elasticsearch 在同一个机器上的话。我们使用如下的命令来检查侦听 9200 的端口。
$ sudo lsof -i -P | grep LISTEN | grep 9200
Password:
logshark 69585 liuxg 10u IPv6 0xe92fabcdd6634ab3 0t0 TCP *:9200 (LISTEN)docker
docker run -p 9200:9200 -it ugosan/logshark -host 0.0.0.0 -port 9200docker-compose.yml
version: "3.2"
services:
logshark:
image: ugosan/logshark
tty: true
stdin_open: true注意:你不应使用 “docker-compose up”,而应使用 “docker-compose run logshark sh”,因为 docker-compose 不会附加到带有 “up” 的容器。 docker-compose run -p 9200:9200 logshark -port 9200
将的 Logstash 管道的输出指向它
就像普通的 elasticsearch 输出一样。针对 docker 的情况:
input
filter
output
elasticsearch
hosts => ["http://host.docker.internal:9200"]
使用 docker 时,你可以使用 host.docker.internal 从另一个容器访问 logshark 容器,例如 docker run --rm byrnedo/alpine-curl -v -XPOST -d '"hello":"test"' http:/ /host.docker.internal:9200。
针对非 docker 部署,我们可以使用如下的 logstash.conf 来进行测试:
logstash.conf
input
stdin
filter
output
stdout codec => rubydebug
elasticsearch
hosts => ["http://localhost:9200"]
在上面,我使用 stdin 来输入我们的文档。我们使用如下的命令来启动 Logstash:
./bin/logstash -f logstash.conf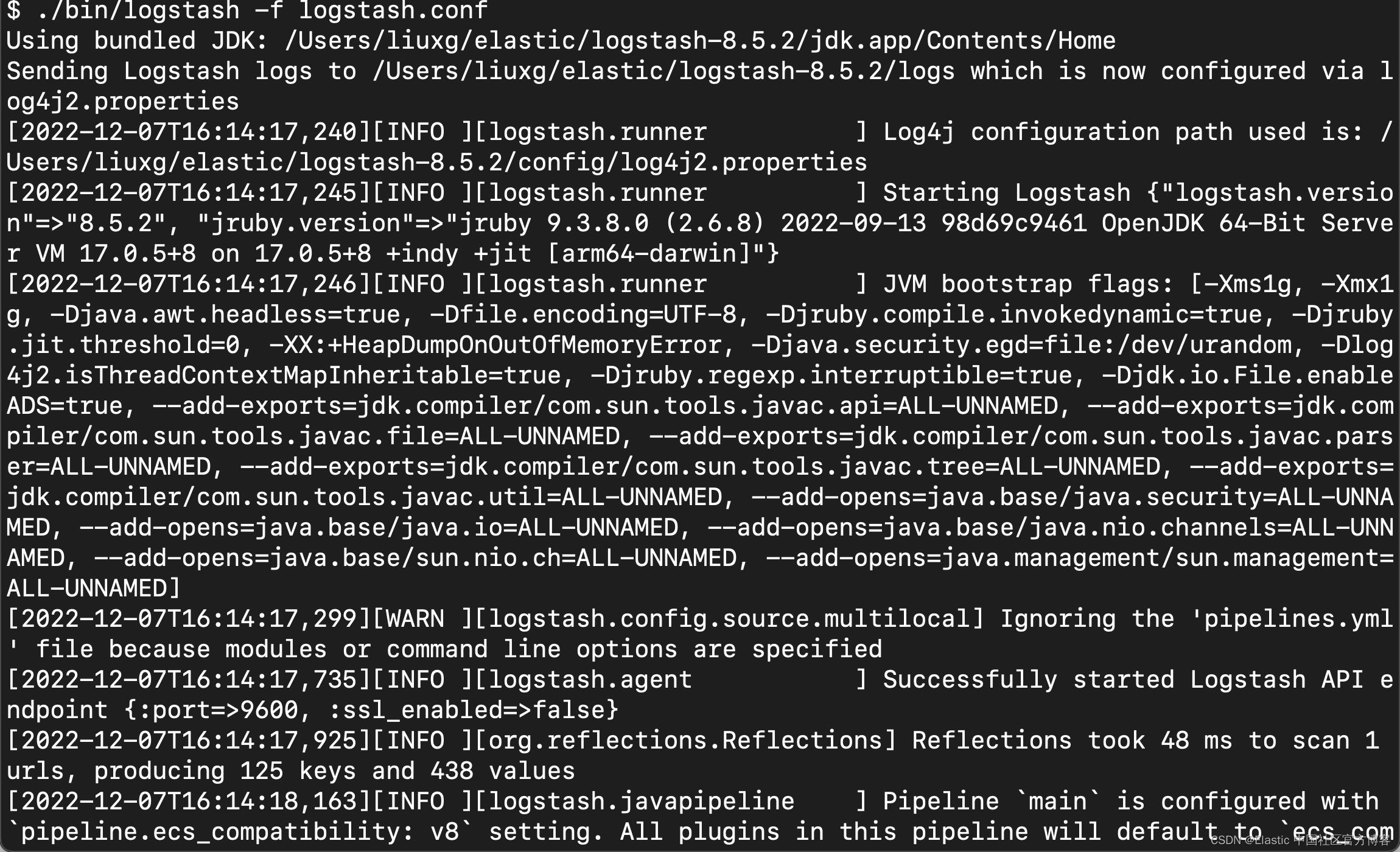
我们在 console 中打入一些我们喜欢的文字:
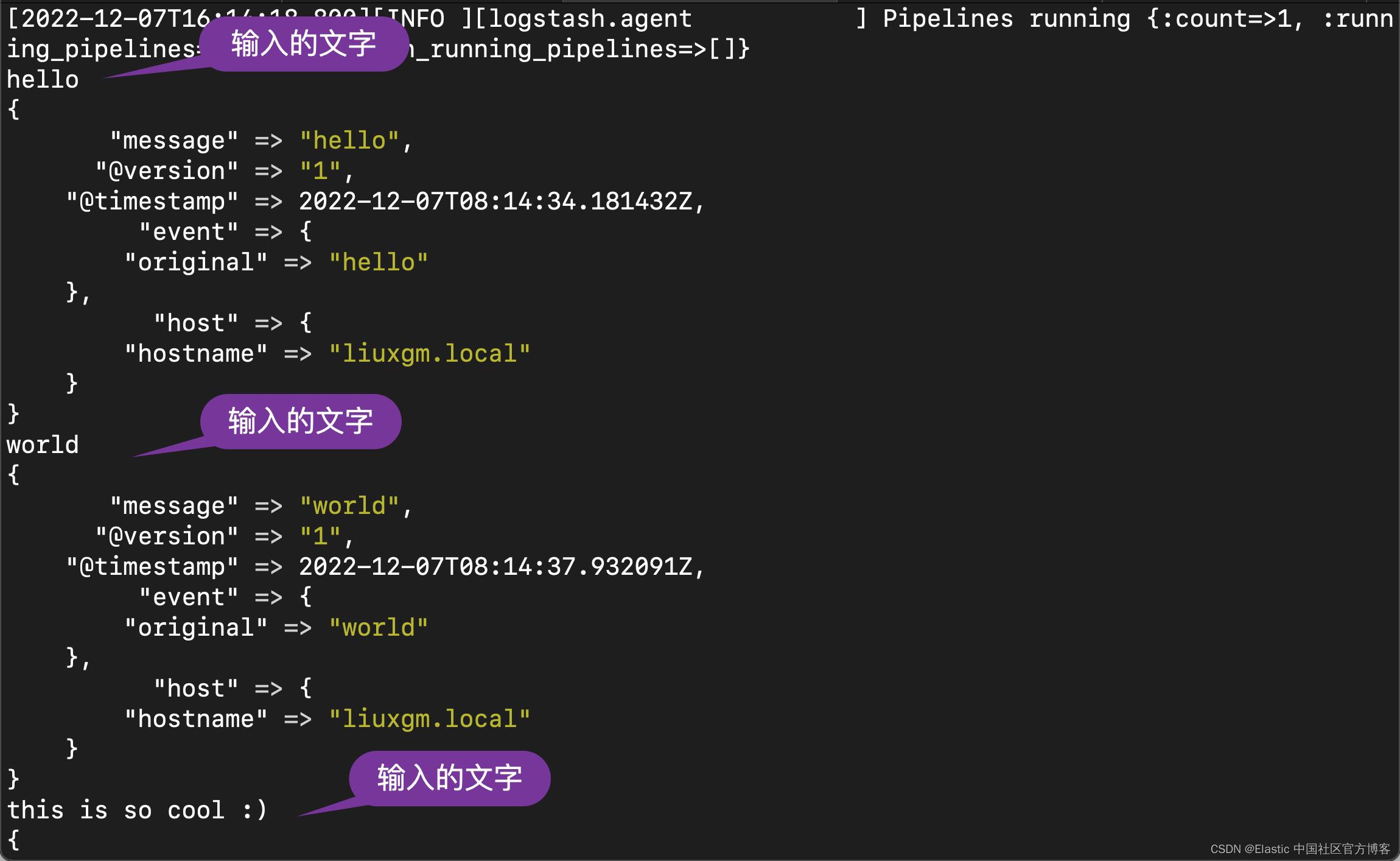
我们切换到 Logshark 所在的 terminal:
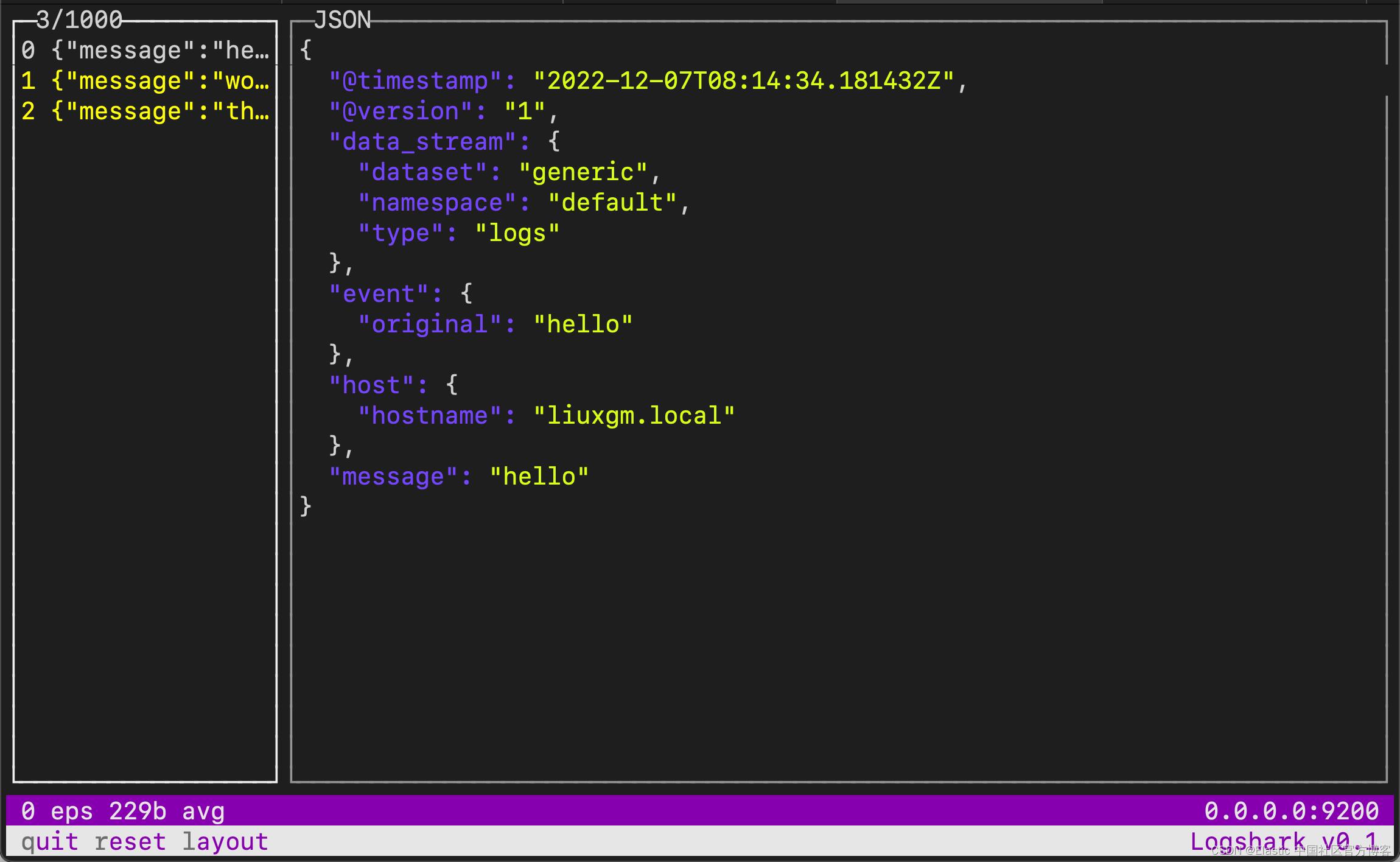
我们可以输入 l 来改变布局:
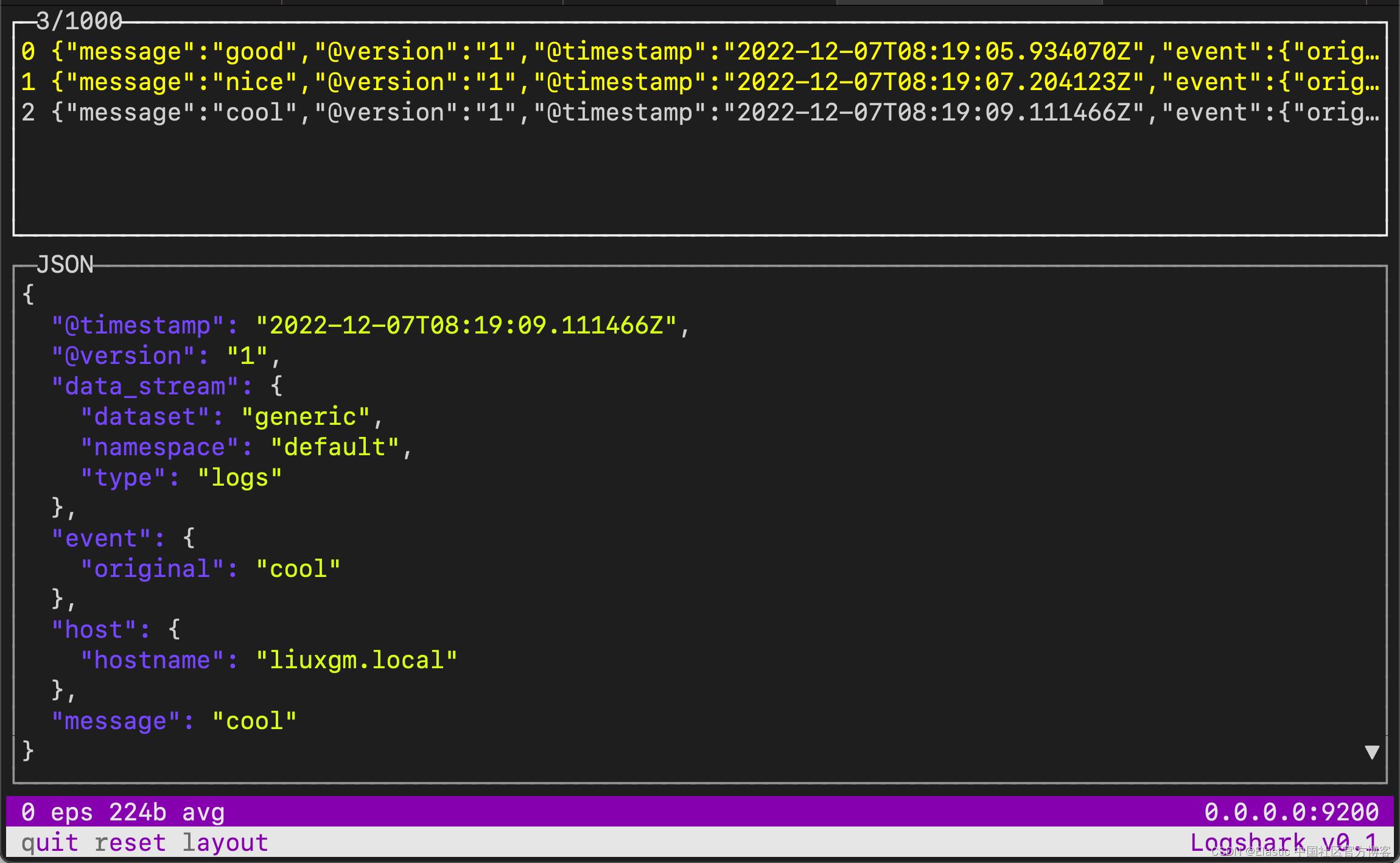
我们可以清楚地看到每个输出。它对我们调试 pipeline 非常有用。
以上是关于filebeat + logstash 对message提取指定字段的主要内容,如果未能解决你的问题,请参考以下文章
Logstash:使用 Logshark 来调试 Logstash 及 Filebeat pipelines
filebeat+logstash+elasticsearch收集haproxy日志
filebeat + logstash + elasticsearch + granfa
Filebeat和pipleline processor-不部署logstash,实现对数据的处理