如何查看oracle的日志文件
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何查看oracle的日志文件相关的知识,希望对你有一定的参考价值。
Oracle日志文件查看方法:
1、以sysdba权限用户登录数据库。
2、执行sql语句:
3、结果显示即为日志路径:

4、另外还有其他的操作日志可用以下两个sql语句查询:
select * fromv $sqlarea;--(#查看最近所作的操作) 参考技术A
1、因为oracle运行在Linux系统下,首先,要连接Linux系统。
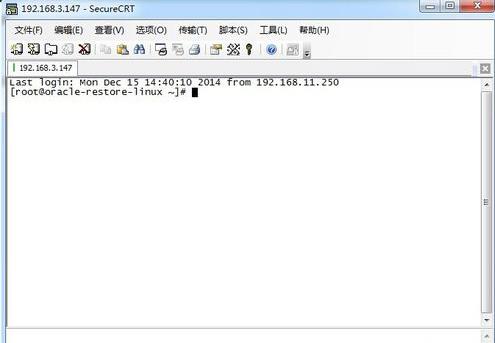
2、切换到oracle安装用户下。 我的用户是 oracle。
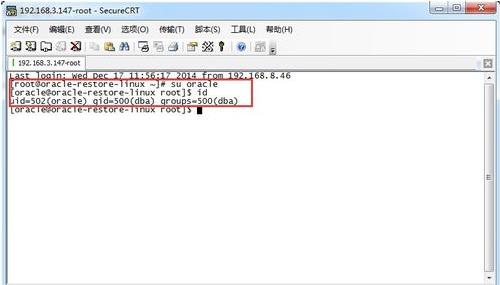
3、运行oracle的环境变量,在oracle 的根目录下面,运行 soruce .bash_prfile 命令, 以便 输入相关命令。
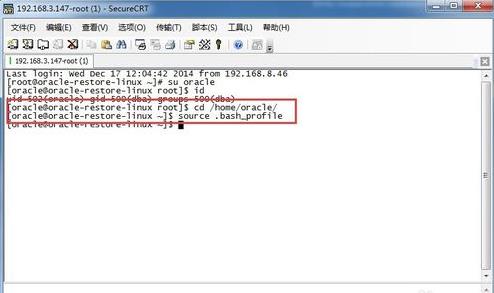
4、运行命令: cd $ORACLE_HOME 进入oracle的安装目录。
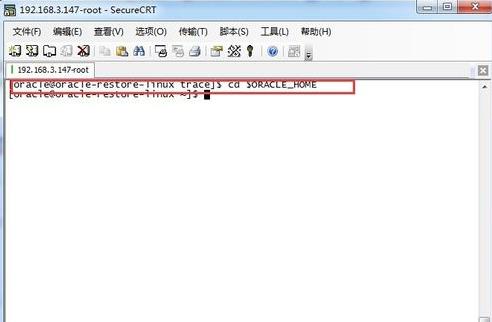
5、在此输入命令: find -name listener.log ,查找监控日志文件。
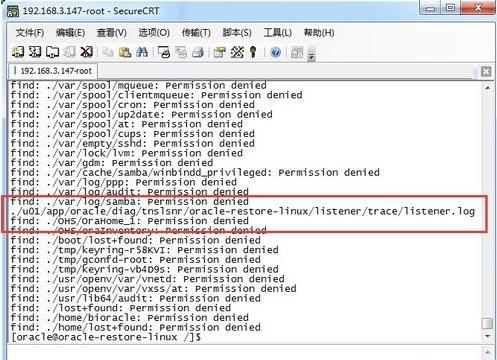
6、运行命令 cd 到查看到的日志文件目录。

7、运行cat listener.log命令 查看日志文件。
一.Oracle日志的路径:
登录:sqlplus "/as sysdba"
查看路径:SQL> select * from v$logfile;
SQL> select * from v$logfile;(#日志文件路径)
二.Oracle日志文件包含哪些内容:(日志的数量可能略有不同)
control01.ctl example01.dbf redo02.log sysaux01.dbf undotbs01.dbf
control02.ctl redo03.log system01.dbf users01.dbf
control03.ctl redo01.log SHTTEST.dbf temp01.dbf
三.Oracle日志的查看方法:
SQL>select * from v$sql (#查看最近所作的操作)
SQL>select * fromv $sqlarea(#查看最近所作的操作)
Oracle 数据库的所有更改都记录在日志中,从目前来看,分析Oracle日志的唯一方法就是使用Oracle公司提供的LogMiner来进行,因为原始的日志信息我们根本无法看懂,Oracle8i后续版本中自带了LogMiner,而LogMiner就是让我们看懂日志信息的工具,通过这个工具可以:查明数据库的逻辑更改,侦察并更正用户的误操作,执行事后审计,执行变化分析。
四.LogMiner的使用:
1、创建数据字典文件(data-dictionary)
1).首先在init.ora初始化参数文件中,添加一个参数UTL_FILE_DIR,该参数值为服务器中放置数据字典文件的目录。如:UTL_FILE_DIR = ($ORACLE_HOME\logs) ,重新启动数据库,使新加的参数生效:
SQL> shutdown;
SQL>startup;
2).然后创建数据字典文件
SQL> connect /as sysdba
SQL> execute dbms_logmnr_d.build(dictionary_filename => 'dict.ora',dictionary_location => '/data1/oracle/logs');
PL/SQL procedure successfully completed
2、创建要分析的日志文件列表
1).创建分析列表,即所要分析的日志
SQL>execute dbms logmnr.add logfile(LogFileName => '/data1/oracle/oradata/akazamdb/redo01.log',Options => dbms_logmnr.new);
PL/SQL procedure successfully completeds
2).添加分析日志文件,一次添加1个为宜
SQL>execute dbms_ logmnr.add_ logfile(LogFileName => '/data1/oracle/oradata/akazamdb/redo01.log',Options => dbms_logmnr.ADDFILE);
PL/SQL procedure successfully completed
3、使用LogMiner进行日志分析(具体要查询什么内容可以自己修改)
(1)无限制条件
SQL> EXECUTE dbms_logmnr.start_logmnr(
DictFileName=>'/data1/oracle/logs/v816dict.ora ');
(2)有限制条件
通过对过程DBMS_ LOGMNR.START_LOGMNR中几个不同参数的设置,可以缩小要分析日志文件的范围。通过设置起始时间和终止时间参数我们可以限制只分析某一时间范围的日志。如下面的例子,我们仅仅分析2007年9月18日的日志:
SQL> EXECUTE dbms_logmnr.start_logmnr(
DictFileName => ' /data1/oracle/logs/ v816dict.ora ',
StartTime => to_date('2007-9-18 00:00:00','YYYY-MM-DD HH24:MI:SS')
EndTime => to_date(''2007-9-18 23:59:59','YYYY-MM-DD HH24:MI:SS '));
也可以通过设置起始SCN和截至SCN来限制要分析日志的范围:
SQL> EXECUTE dbms_logmnr.start_logmnr(
DictFileName => ' /data1/oracle/logs/ v816dict.ora ',
StartScn => 20,
EndScn => 50);
4、观察分析结果(v$logmnr_contents)
到现在为止,我们已经分析得到了重作日志文件中的内容。动态性能视图v$logmnr_contents包含LogMiner分析得到的所有的信息。
SELECT sql_redo FROM v$logmnr_contents;
如果我们仅仅想知道某个用户对于某张表的操作,可以通过下面的SQL查询得到,该查询可以得到用户DB_ZGXT对表SB_DJJL所作的一切工作。
SQL> SELECT sql_redo FROM v$logmnr_contents WHERE username='DB_ZGXT' AND tablename='SB_DJJL';
需要强调一点的是,视图v$logmnr_contents中的分析结果仅在我们运行过程'dbms_logmrn.start_logmnr'这个会话的生命期中存在。这是因为所有的LogMiner存储都在PGA内存中,所有其他的进程是看不到它的,同时随着进程的结束,分析结果也随之消失。
最后,使用过程DBMS_LOGMNR.END_LOGMNR终止日志分析事务,此时PGA内存区域被清除,分析结果也随之不再存在。
5、查看LogMiner工具分析结果
SQL> select * from dict t where t.table_name like '%LOGMNR%';-看所有与logmnr相关的视图
TABLE_NAME COMMENTS
------------------------------ --------------------------------------------------------------------------------
GV$LOGMNR_CALLBACK Synonym for GV_$LOGMNR_CALLBACK
GV$LOGMNR_CONTENTS Synonym for GV_$LOGMNR_CONTENTS
GV$LOGMNR_DICTIONARY Synonym for GV_$LOGMNR_DICTIONARY
GV$LOGMNR_LOGFILE Synonym for GV_$LOGMNR_LOGFILE
GV$LOGMNR_LOGS Synonym for GV_$LOGMNR_LOGS
GV$LOGMNR_PARAMETERS Synonym for GV_$LOGMNR_PARAMETERS
GV$LOGMNR_PROCESS Synonym for GV_$LOGMNR_PROCESS
GV$LOGMNR_REGION Synonym for GV_$LOGMNR_REGION
GV$LOGMNR_SESSION Synonym for GV_$LOGMNR_SESSION
GV$LOGMNR_STATS Synonym for GV_$LOGMNR_STATS
GV$LOGMNR_TRANSACTION Synonym for GV_$LOGMNR_TRANSACTION
V$LOGMNR_CALLBACK Synonym for V_$LOGMNR_CALLBACK
V$LOGMNR_CONTENTS Synonym for V_$LOGMNR_CONTENTS
V$LOGMNR_DICTIONARY Synonym for V_$LOGMNR_DICTIONARY
V$LOGMNR_LOGFILE Synonym for V_$LOGMNR_LOGFILE
V$LOGMNR_LOGS Synonym for V_$LOGMNR_LOGS
V$LOGMNR_PARAMETERS Synonym for V_$LOGMNR_PARAMETERS
V$LOGMNR_PROCESS Synonym for V_$LOGMNR_PROCESS
V$LOGMNR_REGION Synonym for V_$LOGMNR_REGION
V$LOGMNR_SESSION Synonym for V_$LOGMNR_SESSION
TABLE_NAME COMMENTS
------------------------------ --------------------------------------------------------------------------------
V$LOGMNR_STATS Synonym for V_$LOGMNR_STATS
V$LOGMNR_TRANSACTION Synonym for V_$LOGMNR_TRANSACTION
GV$LOGMNR_LOGS 是分析日志列表视图
分析结果在GV$LOGMNR_CONTENTS 视图中,可按以下语句查询:
select scn,timestamp,log_id,seg_owner,seg_type,table_space,data_blk#,data_obj#,data_objd#,
session#,serial#,username,session_info,sql_redo,sql_undo from logmnr3 t where t.sql_redo like 'create%';
如果不能正常查询GV$LOGMNR_CONTENTS视图,并报以下错误,ORA-01306: 在从 v$logmnr_contents 中选择之前必须调用 dbms_logmnr.start_logmnr() 。可采用如下方法:
create table logmnr3 as select * from GV$LOGMNR_CONTENTS;
Oracle端口:1521 参考技术C Oracle日志查看
一.Oracle日志的路径:
登录:sqlplus "/as sysdba"
查看路径:SQL> select * from v$logfile;
SQL> select * from v$logfile;(#日志文件路径)
二.Oracle日志文件包含哪些内容:(日志的数量可能略有不同)
control01.ctl example01.dbf redo02.log sysaux01.dbf undotbs01.dbf
control02.ctl redo03.log system01.dbf users01.dbf
control03.ctl redo01.log SHTTEST.dbf temp01.dbf
三.Oracle日志的查看方法:
SQL>select * from v$sql (#查看最近所作的操作)
SQL>select * fromv $sqlarea(#查看最近所作的操作)
Oracle 数据库的所有更改都记录在日志中,从目前来看,分析Oracle日志的唯一方法就是使用Oracle公司提供的LogMiner来进行,因为原始的日志信息我们根本无法看懂,Oracle8i后续版本中自带了LogMiner,而LogMiner就是让我们看懂日志信息的工具,通过这个工具可以:查明数据库的逻辑更改,侦察并更正用户的误操作,执行事后审计,执行变化分析。本回答被提问者采纳 参考技术D oracle日志文件路径怎么找
1、默认情况下,oracle的日志文件记录在$ORACLE/rdbms/log目录下
1
2
[oracle@oracle log]$ pwd
/home/oracle/oracle/product/11.2.0/db_1/rdbms/log
日志文件为(alert_<ORACLE_SID>.log):
1
2
3
[oracle@oracle log]$ ll
总计 848
-rw-rw-r-- 1 aaa aaa 962 06-20 15:57 alert_TESTDB.log
2、如果不是在默认位置,则可通过sql查询日志文件位置:
1
2
3
4
5
6
7
8
9
10
11
12
SQL> show parameter dump_dest
NAME TYPE
------------------------------------ ----------------------
VALUE
------------------------------
background_dump_dest string
/home/oracle/oracle/admin/TESTDB/bdump
core_dump_dest string
/home/oracle/oracle/admin/TESTDB/cdump
user_dump_dest string
/home/oracle/oracle/admin/TESTDB/udump
其中background_dump_dest的value值即为日志文件存放位置
oracle数据库的警告日志如何查看
oracle数据库的警告日志如何查看
测试环境中出现了一个异常的告警现象:一条告警通过 Thanos Ruler 的 HTTP 接口观察到持续处于 active 状态,但是从 AlertManager 这边看这条告警为已解决状态。按照 DMP 平台的设计,告警已解决指的是告警上设置的结束时间已经过了当前时间。一条发送至 AlertManager 的告警为已解决状态有三种可能:1. 手动解决了告警2. 告警只产生了一次,第二次计算告警规则时会发送一个已解决的告警3. AlertManager 接收到的告警会带着一个自动解决时间,如果还没到达自动解决时间,则将该时间重置为 24h 后首先,因为了解到测试环境没有手动解决过异常告警,排除第一条;其次,由于该告警持续处于 active 状态,所以不会是因为告警只产生了一次而接收到已解决状态的告警,排除第二条;最后,告警的告警的产生时间与自动解决时间相差不是 24h,排除第三条。那问题出在什么地方呢?
分析
下面我们开始分析这个问题。综合第一节的描述,初步的猜想是告警在到达 AlertManager 前的某些阶段的处理过程太长,导致告警到达 AlertManager 后就已经过了自动解决时间。我们从分析平台里一条告警的流转过程入手,找出告警在哪个处理阶段耗时过长。首先,一条告警的产生需要两方面的配合:
metric 数据
告警规则
将 metric 数据输入到告警规则进行计算,如果符合条件则产生告警。DMP 平台集成了 Thanos 的相关组件,数据的提供和计算则会分开,数据还是由 Prometheus Server 提供,而告警规则的计算则交由 Thanos Rule(下文简称 Ruler)处理。下图是 Ruler 组件在集群中所处的位置:
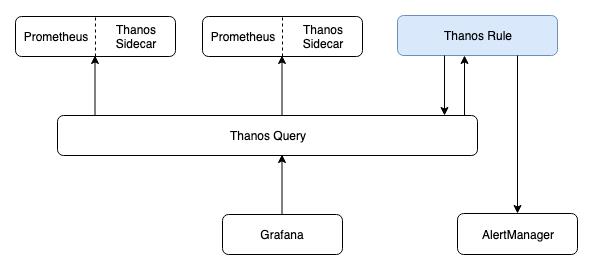
看来,想要弄清楚现告警的产生到 AlertManager 之间的过程,需要先弄清除 Ruler 的大致机制。官方文档对 Ruler 的介绍是:You can think of Rule as a simplified Prometheus that does not require a sidecar and does not scrape and do PromQL evaluation (no QueryAPI)。
不难推测,Ruler 应该是在 Prometheus 上封装了一层,并提供一些额外的功能。通过翻阅资料大致了解,Ruler 使用 Prometheus 提供的库计算告警规则,并提供一些额外的功能。下面是 Ruler 中告警流转过程:

请点击输入图片描述
请点击输入图片描述
首先,图中每个告警规则 Rule 都有一个 active queue(下面简称本地队列),用来保存一个告警规则下的活跃告警。
其次,从本地队列中取出告警,发送至 AlertManager 前,会被放入 Thanos Rule Queue(下面简称缓冲队列),该缓冲队列有两个属性:
capacity(默认值为 10000):控制缓冲队列的大小,
maxBatchSize(默认值为 100):控制单次发送到 AlertManager 的最大告警数
了解了上述过程,再通过翻阅 Ruler 源码发现,一条告警在放入缓冲队列前,会为其设置一个默认的自动解决时间(当前时间 + 3m),这里是影响告警自动解决的开始时间,在这以后,有两个阶段可能影响告警的处理:1. 缓冲队列阶段2. 出缓冲队列到 AlertManager 阶段(网络延迟影响)由于测试环境是局域网环境,并且也没在环境上发现网络相关的问题,我们初步排除第二个阶段的影响,下面我们将注意力放在缓冲队列上。通过相关源码发现,告警在缓冲队列中的处理过程大致如下:如果本地队列中存在一条告警,其上次发送之间距离现在超过了 1m(默认值,可修改),则将该告警放入缓冲队列,并从缓冲队列中推送最多 maxBatchSize 个告警发送至 AlertManager。反之,如果所有本地队列中的告警,在最近 1m 内都有发送过,那么就不会推送缓冲队列中的告警。也就是说,如果在一段时间内,产生了大量重复的告警,缓冲队列的推送频率会下降。队列的生产方太多,消费方太少,该队列中的告警就会产生堆积的现象。因此我们不难猜测,问题原因很可能是是缓冲队列推送频率变低的情况下,单次推送的告警数量太少,导致缓冲队列堆积。下面我们通过两个方面验证上述猜想:首先通过日志可以得到队列在大约 20000s 内推送了大约 2000 次,即平均 10s 推送一次。结合缓冲队列的具体属性,一条存在于队列中的告警大约需要 (capacity/maxBatchSize)*10s = 16m,AlertManager 在接收到告警后早已超过了默认的自动解决时间(3m)。其次,Ruler 提供了 3 个 metric 的值来监控缓冲队列的运行情况:
thanos_alert_queue_alerts_dropped_total
thanos_alert_queue_alerts_pushed_total
thanos_alert_queue_alerts_popped_total
通过观察 thanos_alert_queue_alerts_dropped_total 的值,看到存在告警丢失的总数,也能佐证了缓冲队列在某些时刻存在已满的情况。
解决通过以上的分析,我们基本确定了问题的根源:Ruler 组件内置的缓冲队列堆积造成了告警发送的延迟。针对这个问题,我们选择调整队列的 maxBatchSize 值。下面介绍一下这个值如何设置的思路。由于每计算一次告警规则就会尝试推送一次缓冲队列,我们通过估计一个告警数量的最大值,得到 maxBatchSize 可以设置的最小值。假设你的业务系统需要监控的实体数量分别为 x1、x2、x3、...、xn,实体上的告警规则数量分别有 y1、y2、y3、...、yn,那么一次能产生的告警数量最多是(x1 * y2 + x2 * y2 + x3 * y3 + ... + xn * yn),最多推送(y1 + y2 + y3 + ... + yn)次,所以要使缓冲队列不堆积,maxBatchSize 应该满足:maxBatchSize >= (x1 * y2 + x2 * y2 + x3 * y3 + ... + xn * yn) / (y1 + y2 + y3 + ... + yn),假设 x = max(x1,x2, ...,xn), 将不等式右边适当放大后为 x,即 maxBatchSize 的最小值为 x。也就是说,可以将 maxBatchSize 设置为系统中数量最大的那一类监控实体,对于 DMP 平台,一般来说是 MySQL 实例。
注意事项
上面的计算过程只是提供一个参考思路,如果最终计算出该值过大,很有可能对 AlertManager 造成压力,因而失去缓冲队列的作用,所以还是需要结合实际情况,具体分析。因为 DMP 将 Ruler 集成到了自己的组件中,所以可以比较方便地对这个值进行修改。如果是依照官方文档的介绍使用的 Ruler 组件,那么需要对源码文件进行定制化修改。
http://www.cnblogs.com/kerrycode/p/3899558.html本回答被提问者和网友采纳
以上是关于如何查看oracle的日志文件的主要内容,如果未能解决你的问题,请参考以下文章