线程进程
Posted xone
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了线程进程相关的知识,希望对你有一定的参考价值。
操作系统发展史
手工操作(无操作系统)
1946年第一台计算机诞生--20世纪50年代中期,还未出现操作系统,计算机工作采用手工操作方式。
手工操作
程序员将对应于程序和数据的已穿孔的纸带(或卡片)装入输入机,然后启动输入机把程序和数据输入计算机内存,接着通过控制台开关启动程序针对数据运行;计算完毕,打印机输出计算结果;用户取走结果并卸下纸带(或卡片)后,才让下一个用户上机。
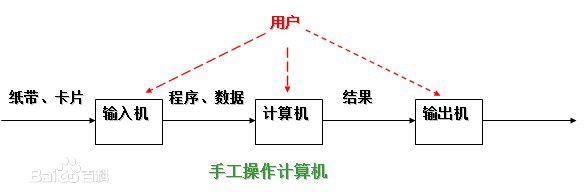
手工操作方式两个特点:
(1)用户独占全机。不会出现因资源已被其他用户占用而等待的现象,但资源的利用率低。
(2)CPU 等待手工操作。CPU的利用不充分。
20世纪50年代后期,出现人机矛盾:手工操作的慢速度和计算机的高速度之间形成了尖锐矛盾,手工操作方式已严重损害了系统资源的利用率(使资源利用率降为百分之几,甚至更低),不能容忍。唯一的解决办法:只有摆脱人的手工操作,实现作业的自动过渡。这样就出现了成批处理。
批处理系统
批处理系统:加载在计算机上的一个系统软件,在它的控制下,计算机能够自动地、成批地处理一个或多个用户的作业(这作业包括程序、数据和命令)。
联机批处理系统
首先出现的是联机批处理系统,即作业的输入/输出由CPU来处理。
主机与输入机之间增加一个存储设备——磁带,在运行于主机上的监督程序的自动控制下,计算机可自动完成:成批地把输入机上的用户作业读入磁带,依次把磁带上的用户作业读入主机内存并执行并把计算结果向输出机输出。完成了上一批作业后,监督程序又从输入机上输入另一批作业,保存在磁带上,并按上述步骤重复处理。
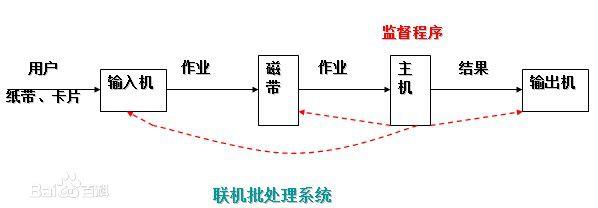
监督程序不停地处理各个作业,从而实现了作业到作业的自动转接,减少了作业建立时间和手工操作时间,有效克服了人机矛盾,提高了计算机的利用率。
但是,在作业输入和结果输出时,主机的高速CPU仍处于空闲状态,等待慢速的输入/输出设备完成工作: 主机处于“忙等”状态。
脱机批处理系统
为克服与缓解高速主机与慢速外设的矛盾,提高CPU的利用率,又引入了脱机批处理系统,即输入/输出脱离主机控制。
这种方式的显著特征是:增加一台不与主机直接相连而专门用于与输入/输出设备打交道的卫星机。
其功能是:
(1)从输入机上读取用户作业并放到输入磁带上。
(2)从输出磁带上读取执行结果并传给输出机。
这样,主机不是直接与慢速的输入/输出设备打交道,而是与速度相对较快的磁带机发生关系,有效缓解了主机与设备的矛盾。主机与卫星机可并行工作,二者分工明确,可以充分发挥主机的高速计算能力。

脱机批处理系统:20世纪60年代应用十分广泛,它极大缓解了人机矛盾及主机与外设的矛盾。IBM-7090/7094:配备的监督程序就是脱机批处理系统,是现代操作系统的原型。
不足:每次主机内存中仅存放一道作业,每当它运行期间发出输入/输出(I/O)请求后,高速的CPU便处于等待低速的I/O完成状态,致使CPU空闲。
为改善CPU的利用率,又引入了多道程序系统。
多道程序系统
多道程序设计技术
所谓多道程序设计技术,就是指允许多个程序同时进入内存并运行。即同时把多个程序放入内存,并允许它们交替在CPU中运行,它们共享系统中的各种硬、软件资源。当一道程序因I/O请求而暂停运行时,CPU便立即转去运行另一道程序。
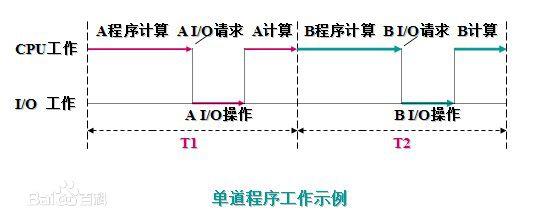
单道程序的运行过程:
在A程序计算时,I/O空闲, A程序I/O操作时,CPU空闲(B程序也是同样);必须A工作完成后,B才能进入内存中开始工作,两者是串行的,全部完成共需时间=T1+T2。
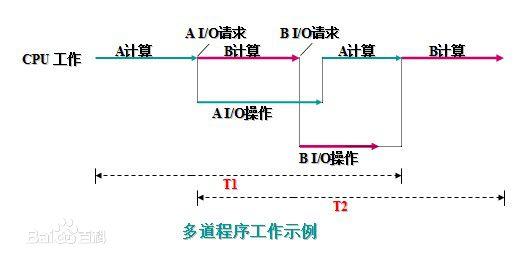
多道程序的运行过程:
将A、B两道程序同时存放在内存中,它们在系统的控制下,可相互穿插、交替地在CPU上运行:当A程序因请求I/O操作而放弃CPU时,B程序就可占用CPU运行,这样 CPU不再空闲,而正进行A I/O操作的I/O设备也不空闲,显然,CPU和I/O设备都处于“忙”状态,大大提高了资源的利用率,从而也提高了系统的效率,A、B全部完成所需时间<<T1+T2。
多道程序设计技术不仅使CPU得到充分利用,同时改善I/O设备和内存的利用率,从而提高了整个系统的资源利用率和系统吞吐量(单位时间内处理作业(程序)的个数),最终提高了整个系统的效率。
单处理机系统中多道程序运行时的特点:
(1)多道:计算机内存中同时存放几道相互独立的程序;
(2)宏观上并行:同时进入系统的几道程序都处于运行过程中,即它们先后开始了各自的运行,但都未运行完毕;
(3)微观上串行:实际上,各道程序轮流地用CPU,并交替运行。
多道程序系统的出现,标志着操作系统渐趋成熟的阶段,先后出现了作业调度管理、处理机管理、存储器管理、外部设备管理、文件系统管理等功能。
多道批处理系统
20世纪60年代中期,在前述的批处理系统中,引入多道程序设计技术后形成多道批处理系统(简称:批处理系统)。
它有两个特点:
(1)多道:系统内可同时容纳多个作业。这些作业放在外存中,组成一个后备队列,系统按一定的调度原则每次从后备作业队列中选取一个或多个作业进入内存运行,运行作业结束、退出运行和后备作业进入运行均由系统自动实现,从而在系统中形成一个自动转接的、连续的作业流。
(2)成批:在系统运行过程中,不允许用户与其作业发生交互作用,即:作业一旦进入系统,用户就不能直接干预其作业的运行。
批处理系统的追求目标:提高系统资源利用率和系统吞吐量,以及作业流程的自动化。
批处理系统的一个重要缺点:不提供人机交互能力,给用户使用计算机带来不便。
虽然用户独占全机资源,并且直接控制程序的运行,可以随时了解程序运行情况。但这种工作方式因独占全机造成资源效率极低。
一种新的追求目标:既能保证计算机效率,又能方便用户使用计算机。 20世纪60年代中期,计算机技术和软件技术的发展使这种追求成为可能。
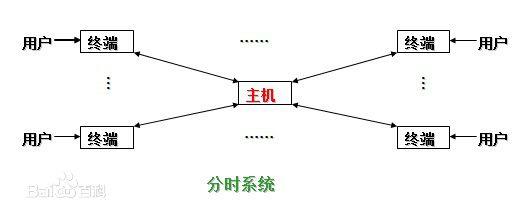
分时系统
由于CPU速度不断提高和采用分时技术,一台计算机可同时连接多个用户终端,而每个用户可在自己的终端上联机使用计算机,好象自己独占机器一样。
分时技术:把处理机的运行时间分成很短的时间片,按时间片轮流把处理机分配给各联机作业使用。
若某个作业在分配给它的时间片内不能完成其计算,则该作业暂时中断,把处理机让给另一作业使用,等待下一轮时再继续其运行。由于计算机速度很快,作业运行轮转得很快,给每个用户的印象是,好象他独占了一台计算机。而每个用户可以通过自己的终端向系统发出各种操作控制命令,在充分的人机交互情况下,完成作业的运行。
具有上述特征的计算机系统称为分时系统,它允许多个用户同时联机使用计算机。
特点:
(1)多路性。若干个用户同时使用一台计算机。微观上看是各用户轮流使用计算机;宏观上看是各用户并行工作。
(2)交互性。用户可根据系统对请求的响应结果,进一步向系统提出新的请求。这种能使用户与系统进行人机对话的工作方式,明显地有别于批处理系统,因而,分时系统又被称为交互式系统。
(3)独立性。用户之间可以相互独立操作,互不干扰。系统保证各用户程序运行的完整性,不会发生相互混淆或破坏现象。
(4)及时性。系统可对用户的输入及时作出响应。分时系统性能的主要指标之一是响应时间,它是指:从终端发出命令到系统予以应答所需的时间。
分时系统的主要目标:对用户响应的及时性,即不至于用户等待每一个命令的处理时间过长。
分时系统可以同时接纳数十个甚至上百个用户,由于内存空间有限,往往采用对换(又称交换)方式的存储方法。即将未“轮到”的作业放入磁盘,一旦“轮到”,再将其调入内存;而时间片用完后,又将作业存回磁盘(俗称“滚进”、“滚出“法),使同一存储区域轮流为多个用户服务。
多用户分时系统是当今计算机操作系统中最普遍使用的一类操作系统。
实时系统
虽然多道批处理系统和分时系统能获得较令人满意的资源利用率和系统响应时间,但却不能满足实时控制与实时信息处理两个应用领域的需求。于是就产生了实时系统,即系统能够及时响应随机发生的外部事件,并在严格的时间范围内完成对该事件的处理。
实时系统在一个特定的应用中常作为一种控制设备来使用。
实时系统可分成两类:
(1)实时控制系统。当用于飞机飞行、导弹发射等的自动控制时,要求计算机能尽快处理测量系统测得的数据,及时地对飞机或导弹进行控制,或将有关信息通过显示终端提供给决策人员。当用于轧钢、石化等工业生产过程控制时,也要求计算机能及时处理由各类传感器送来的数据,然后控制相应的执行机构。
(2)实时信息处理系统。当用于预定飞机票、查询有关航班、航线、票价等事宜时,或当用于银行系统、情报检索系统时,都要求计算机能对终端设备发来的服务请求及时予以正确的回答。此类对响应及时性的要求稍弱于第一类。
实时操作系统的主要特点:
(1)及时响应。每一个信息接收、分析处理和发送的过程必须在严格的时间限制内完成。
(2)高可靠性。需采取冗余措施,双机系统前后台工作,也包括必要的保密措施等。
进程与线程
什么是进程(process)?
An executing instance of a program is called a process.
Each process provides the resources needed to execute a program. A process has a virtual address space, executable code, open handles to system objects, a security context, a unique process identifier, environment variables, a priority class, minimum and maximum working set sizes, and at least one thread of execution. Each process is started with a single thread, often called the primary thread, but can create additional threads from any of its threads.
程序并不能单独运行,只有将程序装载到内存中,系统为它分配资源才能运行,而这种执行的程序就称之为进程。程序和进程的区别就在于:程序是指令的集合,它是进程运行的静态描述文本;进程是程序的一次执行活动,属于动态概念。
在多道编程中,我们允许多个程序同时加载到内存中,在操作系统的调度下,可以实现并发地执行。这是这样的设计,大大提高了CPU的利用率。进程的出现让每个用户感觉到自己独享CPU,因此,进程就是为了在CPU上实现多道编程而提出的。
有了进程为什么还要线程?
进程有很多优点,它提供了多道编程,让我们感觉我们每个人都拥有自己的CPU和其他资源,可以提高计算机的利用率。很多人就不理解了,既然进程这么优秀,为什么还要线程呢?其实,仔细观察就会发现进程还是有很多缺陷的,主要体现在两点上:
-
进程只能在一个时间干一件事,如果想同时干两件事或多件事,进程就无能为力了。
-
进程在执行的过程中如果阻塞,例如等待输入,整个进程就会挂起,即使进程中有些工作不依赖于输入的数据,也将无法执行。
例如,我们在使用qq聊天, qq做为一个独立进程如果同一时间只能干一件事,那他如何实现在同一时刻 即能监听键盘输入、又能监听其它人给你发的消息、同时还能把别人发的消息显示在屏幕上呢?你会说,操作系统不是有分时么?但我的亲,分时是指在不同进程间的分时呀, 即操作系统处理一会你的qq任务,又切换到word文档任务上了,每个cpu时间片分给你的qq程序时,你的qq还是只能同时干一件事呀。
再直白一点, 一个操作系统就像是一个工厂,工厂里面有很多个生产车间,不同的车间生产不同的产品,每个车间就相当于一个进程,且你的工厂又穷,供电不足,同一时间只能给一个车间供电,为了能让所有车间都能同时生产,你的工厂的电工只能给不同的车间分时供电,但是轮到你的qq车间时,发现只有一个干活的工人,结果生产效率极低,为了解决这个问题,应该怎么办呢?。。。。没错,你肯定想到了,就是多加几个工人,让几个人工人并行工作,这每个工人,就是线程!
什么是线程(thread)?
线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务
线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务
A thread is an execution context, which is all the information a CPU needs to execute a stream of instructions.
Suppose you\'re reading a book, and you want to take a break right now, but you want to be able to come back and resume reading from the exact point where you stopped. One way to achieve that is by jotting down the page number, line number, and word number. So your execution context for reading a book is these 3 numbers.
If you have a roommate, and she\'s using the same technique, she can take the book while you\'re not using it, and resume reading from where she stopped. Then you can take it back, and resume it from where you were.
Threads work in the same way. A CPU is giving you the illusion that it\'s doing multiple computations at the same time. It does that by spending a bit of time on each computation. It can do that because it has an execution context for each computation. Just like you can share a book with your friend, many tasks can share a CPU.
On a more technical level, an execution context (therefore a thread) consists of the values of the CPU\'s registers.
Last: threads are different from processes. A thread is a context of execution, while a process is a bunch of resources associated with a computation. A process can have one or many threads.
Clarification: the resources associated with a process include memory pages (all the threads in a process have the same view of the memory), file descriptors (e.g., open sockets), and security credentials (e.g., the ID of the user who started the process).
进程与线程的区别?
- Threads share the address space of the process that created it; processes have their own address space.
- Threads have direct access to the data segment of its process; processes have their own copy of the data segment of the parent process.
- Threads can directly communicate with other threads of its process; processes must use interprocess communication to communicate with sibling processes.
- New threads are easily created; new processes require duplication of the parent process.
- Threads can exercise considerable control over threads of the same process; processes can only exercise control over child processes.
- Changes to the main thread (cancellation, priority change, etc.) may affect the behavior of the other threads of the process; changes to the parent process does not affect child processes.
Python GIL(Global Interpreter Lock)
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
上面的核心意思就是,无论你启多少个线程,你有多少个cpu, Python在执行的时候会淡定的在同一时刻只允许一个线程运行。
实例
import threading import time def run(n): time.sleep(1) #print(threading.get_ident()) print("thread",n) print(threading.current_thread()) print(threading.active_count()) t = threading.Thread(target=run,args=(1,)) t.start() print(\'-------------\') t2 = threading.Thread(target=run,args=(2,)) t2.start() print(threading.active_count())
以上代码运行结果
1 ------------- 3 thread 1 <Thread(Thread-1, started 8088)> thread 2 <Thread(Thread-2, started 12816)>
主线程启动子线程后,主线程跟子线程是平级的,主线程结束,子线程继续跑。
实例
子线程运行完了就退出
import threading import time def run(n): time.sleep(1) #print(threading.get_ident()) print("thread",n) print(threading.current_thread())#打印当前正在运行的线程的实例 for i in range(10): t = threading.Thread(target=run, args=(i,)) t.start() t.setName("t-%s"%i) print(t.getName()) print(threading.active_count()) print(threading.current_thread()) time.sleep(1.5) print(threading.active_count())
以上代码运行结果
t-0 t-1 t-2 t-3 t-4 t-5 t-6 t-7 t-8 t-9 11 <_MainThread(MainThread, started 5328)> thread 0 thread 3 <Thread(t-3, started 11760)> <Thread(t-0, started 14116)> thread 4 <Thread(t-4, started 5500)> thread 1 <Thread(t-1, started 13904)> thread 2 <Thread(t-2, started 14068)> thread 5 <Thread(t-5, started 968)> thread 9 <Thread(t-9, started 7728)> thread 8 <Thread(t-8, started 6724)> thread 7 <Thread(t-7, started 10912)> thread 6 <Thread(t-6, started 10076)> 1
线程等待
import threading import time def run(n): time.sleep(1) print("thread",n) t_list = [] for i in range(10): t = threading.Thread(target=run, args=(i,)) t.start() t_list.append(t) # print(t_list) for t in t_list: t.join() print("--main thread---")
以上代码运行结果
thread 4 thread 2 thread 1 thread 3 thread 0 thread 7 thread 5 thread 8 thread 6 thread 9 --main thread---
守护线程
import threading import time def run(n): time.sleep(1) print("thread",n) for i in range(10): t = threading.Thread(target=run, args=(i,)) t.setDaemon(True) t.start() print("--main thread---")
以上代码运行结果
--main thread---
线程LOCK
import threading,time def run(n): global num l.acquire() #获取锁 num+=1 time.sleep(0.5) l.release() #释放锁 time.sleep(0.5) # print(threading.get_ident()) print(num) def run2(): count=0 while num<5: print(\'------\',count) count+=1 l=threading.Lock() num=0 t_list=[] for i in range(10): t = threading.Thread(target=run, args=(i,)) t.start() t_list.append(t) t2 = threading.Thread(target=run2) t2.start() for t in t_list: t.join() #join等待线程终止 print(threading.current_thread()) print(num)
递归锁
import threading,time def run1(): print("grab the first part data") lock.acquire() global num num +=1 lock.release() return num def run2(): print("grab the second part data") lock.acquire() global num2 num2+=1 lock.release() return num2 def run3(): lock.acquire() res = run1() print(\'--------between run1 and run2-----\') res2 = run2() lock.release() print(res,res2) if __name__ == \'__main__\': num,num2 = 0,0 lock = threading.RLock() for i in range(10): t = threading.Thread(target=run3) t.start() while threading.active_count() != 1: print(threading.active_count()) else: print(\'----all threads done---\') print(num,num2)
信号量
import threading,time def run(n): semaphore.acquire() time.sleep(1) print("run the thread: %s\\n" %n) semaphore.release() if __name__ == \'__main__\': num= 0 semaphore = threading.BoundedSemaphore(5) #最多允许5个线程同时运行 for i in range(20): t = threading.Thread(target=run,args=(i,)) t.start() while threading.active_count() != 1: pass #print threading.active_count() else: print(\'----all threads done---\') print(num)
timer设置程序定时运行
import threading def hello(): print(\'hello world\') t=threading.Timer(3.0,hello) t.start()
Events
event = threading.Event()
# a client thread can wait for the flag to be set
event.wait()
# a server thread can set or reset it
event.set()
event.clear()
If the flag is set, the wait method doesn’t do anything.
If the flag is cleared, wait will block until it becomes set again.
任意数量的线程都可以等待同一个事件。
import threading,time def lighter(): count=0 while True: if count<30: if not event.is_set(): event.set() print(\'\\033[32;1m green light---\\033[0m\') elif count<34: print(\'\\033[33;1m yellow light---\\033[0m\') elif count < 60: if event.is_set(): event.clear() print(\'\\033[31;1m red light---\\033[0m\') else: count=0 count+=1 time.sleep(0.2) def car(n): count=0 while True: event.wait() print(\'car %s is running\'%n) count+=1 time.sleep(0.5) event=threading.Event() red_light=threading.Thread(target=lighter) red_light.start() c1=threading.Thread(target=car,args=(1,)) c1.start()
queue队列
生产者消费者模型
在并发编程中使用生产者和消费者模式能够解决绝大多数并发问题。该模式通过平衡生产线程和消费线程的工作能力来提高程序的整体处理数据的速度。
为什么要使用生产者和消费者模式
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
什么是生产者消费者模式
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
import queue,threading,time def consumer(name): while True: print(\'%s 取到骨头 %s 并吃了它\'%(name,q.get())) time.sleep(0.5) q.task_done() def producer(name): count=0 # while q.qsize()<5: for i in range(10): print(\'%s生成骨头%s\'%(name,count)) q.put(count) count+=1 time.sleep(0.3) q.join() q=queue.Queue(maxsize=5) # p=threading.Thread(target=producer) p2=threading.Thread(target=producer,args=(\'alex\',)) # p3=threading.Thread(target=producer,args=(\'fds\',)) c=threading.Thread(target=consumer,args=(\'李闯\',))
以上代码运行结果
alex生成骨头0 李闯 取到骨头 0 并吃了它 alex生成骨头1 李闯 取到骨头 1 并吃了它 alex生成骨头2 alex生成骨头3 李闯 取到骨头 2 并吃了它 alex生成骨头4 李闯 取到骨头 3 并吃了它 alex生成骨头5 alex生成骨头6 李闯 取到骨头 4 并吃了它 alex生成骨头7 alex生成骨头8 李闯 取到骨头 5 并吃了它 alex生成骨头9 李闯 取到骨头 6 并吃了它 李闯 取到骨头 7 并吃了它 李闯 取到骨头 8 并吃了它 李闯 取到骨头 9 并吃了它
多进程multiprocessing
from multiprocessing import Process import time def f(name): time.sleep(2) print(\'hello\', name) if __name__ == \'__main__\': for i in range(10): p = Process(target=f, args=(\'bob\',)) p.start() p.join()
以上代码运行结果
hello bob
hello bob
hello bob
hello bob
hello bob
hello bob
hello bob
hello bob
hello bob
hello bob
进程间通讯
方式一:Queue
from multiprocessing import Process, Queue def f(q): q.put([42, None, \'hello\']) if __name__ == \'__main__\': q = Queue() p = Process(target=f, args=(q,)) p.start() print(q.get()) # prints "[42, None, \'hello\']" p.join()
以上代码运行结果
[42, None, \'hello\']
方式二:PIPE
from multiprocessing import Process, Pipe def f(conn): conn.send([42, None, \'hello\']) conn.send([41, None, \'hello\']) print(\'from parent\',conn.recv()) print(\'from 2\',conn.recv()) conn.close() if __name__ == \'__main__\': parent_conn, child_conn = Pipe() p = Process(target=f, args=(child_conn,)) p.start() print(parent_conn.recv()) # prints "[42, None, \'hello\']" parent_conn.send(\'hello son\') p.join()
以上代码运行结果
[42, None, \'hello\'] from parent hello son
manager现在进程间同时修改同一份数据
from multiprocessing import Process, Manager def f(d, l,n): d[n] = n # d[\'2\'] = 2 # d[0.25] = None l.append(1) # print(l) if __name__ == \'__main__\': with Manager() as manager: d = manager.dict() l = manager.list(range(5)) p_list = [] for i in range(10): p = Process(target=f, args=(d, l,i)) p.start() p_list.append(p) for res in p_list: res.join() print(d) print(l)
以上代码运行结果
{0: 0, 1: 1, 2: 2, 3: 3, 4: 4, 5: 5, 6: 6, 7: 7, 8: 8, 9: 9}
[0, 1, 2, 3, 4, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
进程锁
保证多进程在同时对屏幕输出时不错位
from multiprocessing import Process, Lock def f(l, i): l.acquire() try: print(\'hello world\', i) finally: l.release() if __name__ == \'__main__\': lock = Lock() for num in range(10): Process(target=f, args=(lock, num)).start()
以上代码运行结果
hello world 0 hello world 1 hello world 3 hello world 2 hello world 4 hello world 5 hello world 6 hello world 7 hello world 8 hello world 9
进程池
from multiprocessing import Process,Pool import time,os def Foo(i): time.sleep(1) print(\'--->\',os.getpid()) return i+100 def Bar(arg): print(\'-->exec done:\',arg,os.getpid()) if __name__ == \'__main__\': pool = Pool(processes=5)#同时开的进程数别大于cpu核数的2倍 for i in range(10): pool.apply_async(func=Foo, args=(i,),callback=Bar) #pool.apply(func=Foo, args=(i,)) print(\'end\') pool.close() pool.join()#进程池中进程执行完毕后再关闭,如果注释,那么程序直接关闭。
以上代码运行结果
end ---> 5136 -->exec done: 100 13632 ---> 5940 -->exec done: 101 13632 ---> 5768 -->exec done: 102 13632 ---> 1996 -->exec done: 103 13632 ---> 15516 -->exec done: 104 13632 ---> 5136 -->exec done: 105 13632 ---> 5940 -->exec done: 106 13632 ---> 5768 -->exec done: 107 13632 ---> 1996 -->exec done: 108 13632 ---> 15516 -->exec done: 109 13632
paramiko模块
ssh远程连接并执行相关操作
import paramiko # 创建SSH对象 ssh = paramiko.SSHClient() # 允许连接不在know_hosts文件中的主机 ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) # 连接服务器 ssh.connect(hostname=\'c1.salt.com\', port=22, username=\'wupeiqi\', password=\'123\') # 执行命令 stdin, stdout, stderr = ssh.exec_command(\'df\') # 获取命令结果 result = stdout.read() # 关闭连接 ssh.close()
以上是关于线程进程的主要内容,如果未能解决你的问题,请参考以下文章