机器学习实践一搭建心脏病预测案例
Posted 李博Garvin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习实践一搭建心脏病预测案例相关的知识,希望对你有一定的参考价值。
产品地址:https://data.aliyun.com/product/learn?spm=a21gt.99266.416540.102.OwEfx2
一、背景
心脏病是人类健康的头号杀手。全世界1/3的人口死亡是因心脏病引起的,而我国,每年有几十万人死于心脏病。 所以,如果可以通过提取人体相关的体侧指标,通过数据挖掘的方式来分析不同特征对于心脏病的影响,对于预测和预防心脏病将起到至关重要的作用。本文将会通过真实的数据,通过阿里云机器学习平台搭建心脏病预测案例。
二、数据集介绍
数据源: UCI开源数据集heart_disease
针对美国某区域的心脏病检查患者的体测数据,共303条数据。具体字段如下表:
| 字段名 | 含义 | 类型 | 描述 |
|---|---|---|---|
| age | 年龄 | string | 对象的年龄,数字表示 |
| sex | 性别 | string | 对象的性别,female和male |
| cp | 胸部疼痛类型 | string | 痛感由重到无typical、atypical、non-anginal、asymptomatic |
| trestbps | 血压 | string | 血压数值 |
| chol | 胆固醇 | string | 胆固醇数值 |
| fbs | 空腹血糖 | string | 血糖含量大于120mg/dl为true,否则为false |
| restecg | 心电图结果 | string | 是否有T波,由轻到重为norm、hyp |
| thalach | 最大心跳数 | string | 最大心跳数 |
| exang | 运动时是否心绞痛 | string | 是否有心绞痛,true为是,false为否 |
| oldpeak | 运动相对于休息的ST depression | string | st段压数值 |
| slop | 心电图ST segment的倾斜度 | string | ST segment的slope,程度分为down、flat、up |
| ca | 透视检查看到的血管数 | string | 透视检查看到的血管数 |
| thal | 缺陷种类 | string | 并发种类,由轻到重norm、fix、rev |
| status | 是否患病 | string | 是否患病,buff是健康、sick是患病 |
三、数据探索流程
数据挖掘流程如下:
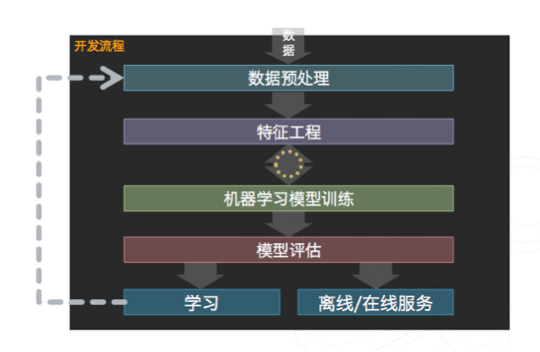
整体实验流程:
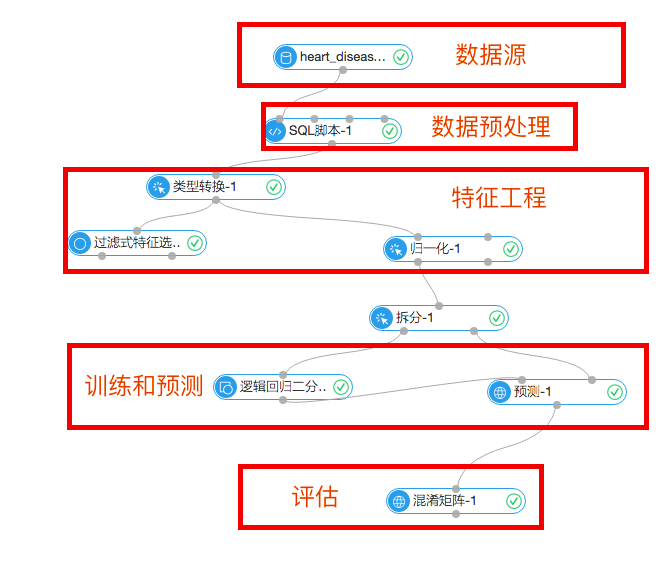
1.数据预处理
数据预处理也叫作数据清洗,主要在数据进入算法流程前对数据进行去噪、填充缺失值、类型变换等操作。本次实验的输入数据包括14个特征和1个目标队列。需要解决的场景是根据用户的体检指标预测是否会患有心脏病,每个样本只有患病或不患病两种,是分类问题。因为本次分类实验选用的是线性模型逻辑回归,要求输入的特征都是double型的数据。
输入数据展示:
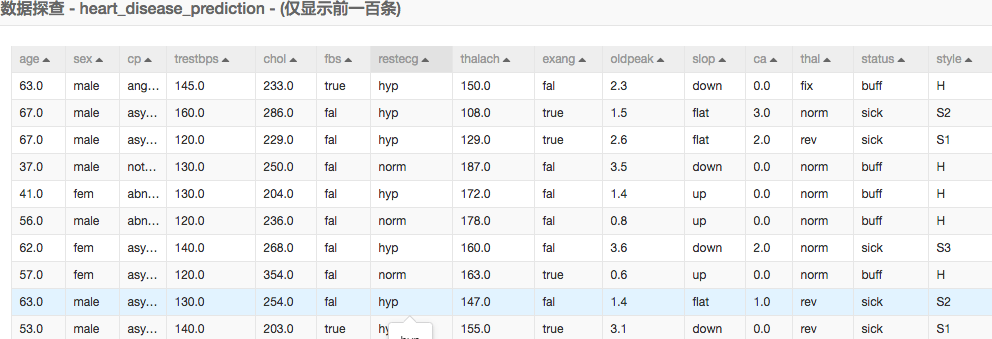
我们看到有很多数据是文字描述的,在数据预处理的过程中我们需要根据每个字段的含义将字符型转为数值。
1)二值类的数据
二值类的比较容易转换,如sex字段有两种表现形式female和male,我们可以将female表示成0,把male表示成1。
2)多值类的数据
比如cp字段,表示胸部的疼痛感,我们可以通过疼痛的由轻到重映射成0~3的数值。
数据的预处理通过sql脚本来实现,具体请参考SQL脚本-1组件,
select age,
(case sex when ‘male‘ then 1 else 0 end) as sex,
(case cp when ‘angina‘ then 0 when ‘notang‘ then 1 else 2 end) as cp,
trestbps,
chol,
(case fbs when ‘true‘ then 1 else 0 end) as fbs,
(case restecg when ‘norm‘ then 0 when ‘abn‘ then 1 else 2 end) as restecg,
thalach,
(case exang when ‘true‘ then 1 else 0 end) as exang,
oldpeak,
(case slop when ‘up‘ then 0 when ‘flat‘ then 1 else 2 end) as slop,
ca,
(case thal when ‘norm‘ then 0 when ‘fix‘ then 1 else 2 end) as thal,
(case status when ‘sick‘ then 1 else 0 end) as ifHealth
from ${t1};
2.特征工程
特征工程主要是包括特征的衍生、尺度变化等。本例中有两个组件负责特征工程的部分。
1)过滤式特征选择
主要是通过这个组件判断每个特征对于结果的影响,通过信息熵和基尼系数来表示,可以通过查看评估报告来显示最终的结果。
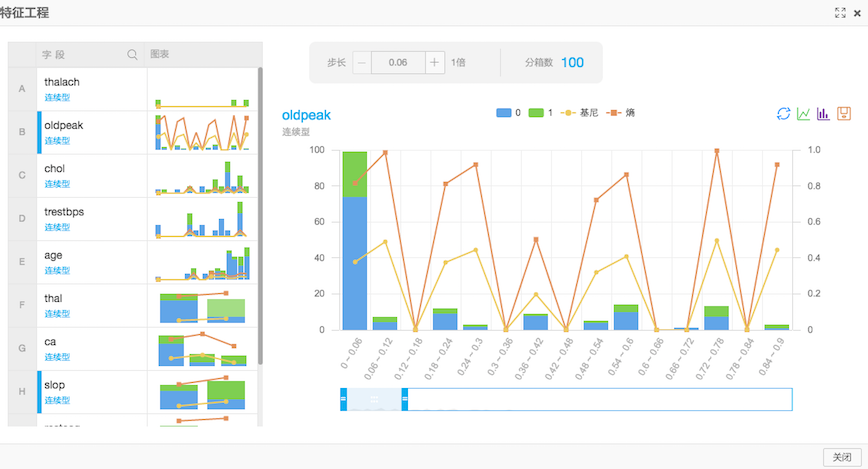
2)归一化
因为本次实验选择的是通过逻辑回归二分类来进行模型训练,需要每个特征去除量纲的影响。归一化的作用是将每个特征的数值范围变为0到1之间。归一化的公式为result=(val-min)/(max-min)。
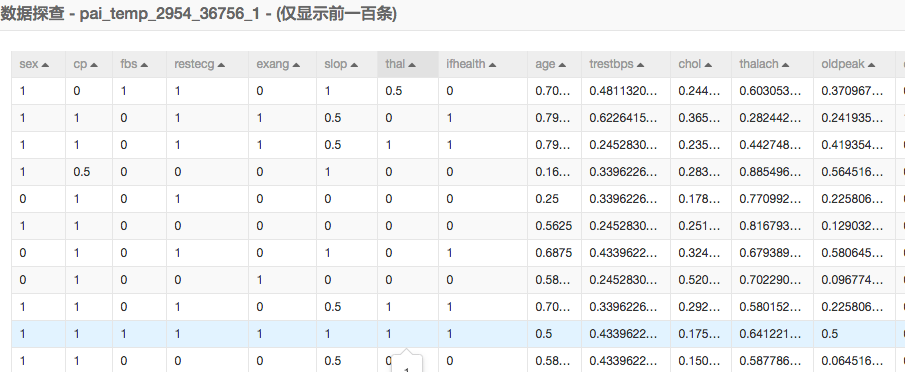
归一化结果:
3.模型训练和预测
本次实验是监督学习,因为我们已经知道每个样本是否患有心脏病,所谓监督学习就是已知结果来训练模型。解决的问题是预测一组用户是否患有心脏病。
1)拆分
首先通过拆分组件将数据分为两部分,本次实验按照训练集和预测集7:3的比例拆分。训练集数据流入逻辑回归二分类组件用来训练模型,预测集数据进入预测组件。
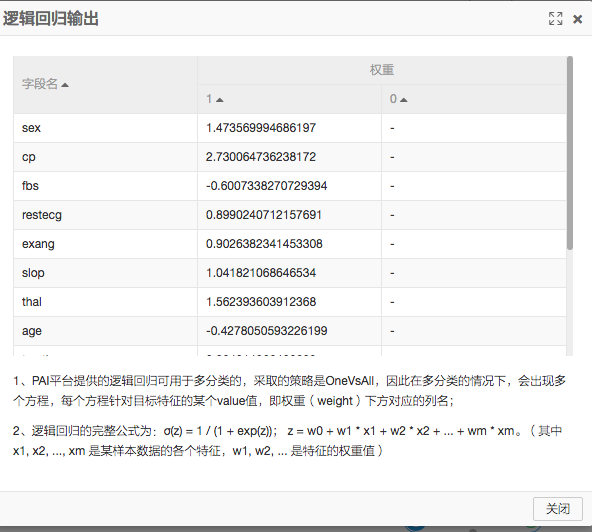
2)逻辑回归二分类
逻辑回归是一个线性模型,在这里通过计算结果的阈值实现分类。具体的算法详情推荐大家在网上或者书籍中自行了解。逻辑回归训练好的模型可以在模型页签中查看。
3)预测
预测组件的两个输入分别是模型和预测集。预测结果展示的是预测数据、真实数据、每组数据不同结果的概率。
4.评估
通过混淆矩阵组件可以评估模型的准确率等参数,
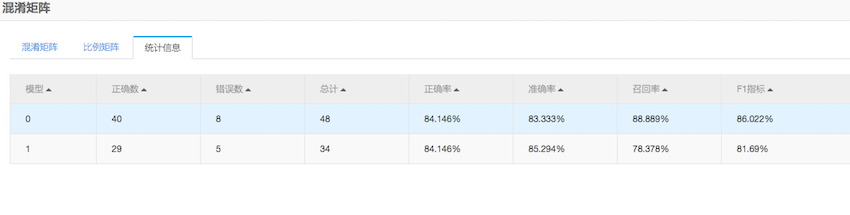
通过此组件可以方便的通过预测的准确性来评估模型。
四.总结
通过以上数据探索的流程我们可以得到以下的结论。
1)特征权重
我们可以通过过滤式特征选择得到每个特征对于结果的权重。
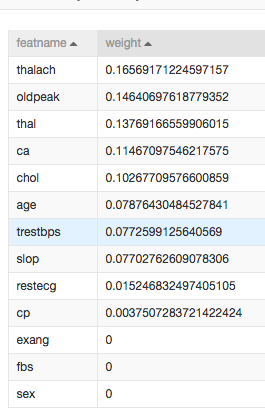
-可以看出thalach(心跳数)对于是否发生心脏病影响最大。
-性别对于心脏病没有影响
2)模型效果
通过上文提供的14个特征,可以达到百分之八十多的心脏病预测准确率。模型可以用来做预测,辅助医生预防和治疗心脏病。
五、其它
免费体验:阿里云数加机器学习平台
以上是关于机器学习实践一搭建心脏病预测案例的主要内容,如果未能解决你的问题,请参考以下文章
《Python机器学习及实践》----良/恶性乳腺癌肿瘤预测
java-springboot基于机器学习得心脏病预测系统 的设计与实现-计算机毕业设计