python运行后中断,存入文件内容完整吗
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python运行后中断,存入文件内容完整吗相关的知识,希望对你有一定的参考价值。
参考技术A 热门频道首页
博客
研修院
VIP
APP
问答
下载
社区
推荐频道
活动
招聘
专题
打开CSDN APP
Copyright © 1999-2020, CSDN.NET, All Rights Reserved
python数据写入文件不完整
打开APP
解决python写入文件数据不全的问题 原创
2019-05-15 17:08:35
4点赞
琼雪染霜华
码龄6年
关注
如果利用语句
向txt文件中写入内容时,运行程序之后,
查看test.txt文件发现文件中的内容并不完整,
这时候就需要检查在代码的最后是否有这样一句话
这样就能截断程序与文件中的联系,
将缓存在内存中的内容全部写入到文件中
且能对test.txt文件进行删除等其他操作,
不必担心是否文件被程序占用的问题。
另一个解决方案就是利用with语句,
这样就不用单独使用close()语句,
因为with语句会自动调用该语句:
文章知识点与官方知识档案匹配
Python入门技能树基本技能数据文件读写
199361 人正在系统学习中
打开CSDN,阅读体验更佳
Python | 多线程处理数据并写入到文件,但数据内容存在残缺混乱的情况...
python—多线程之数据混乱问题 python全栈 1443 一、加入线程同步的原因由于同一进程中的所有线程都是共享数据的,如果对线程中共享数据的并发访问不加以限制,结果将不可预期,在严重的情况下,还会产生死锁在一个进程内的所有线程共享全局变...
Python爬虫写入excel数据内容不完整有空白行_Quest_sec的博客
百度没有看到任何相似问题,只好自己写了。观察发现,这几组数据是不完整的,少了一列,且恰恰是这一列爬到的数据是不完全正确的(既有片长又有上映年份)于是明确两点:(1)对于数据部分缺失的问题,我们想要的结果并不是直接舍弃整组数据,...
浅谈python写入大量文件的问题
今天准备把几个txt文件合并成一个文件时,用f.write方法写入时,发现程序执行完了,本应该十万行左右的txt记录,实际上只被写入了4k多行。 网上查了是因为程序执行速度太快,以至于读到内容还没有完全写入文件,文件就已经关闭了 方法一:加入缓冲区 f.flush() //operation os.
Python爬虫之运用scrapy框架将爬取的内容存入文件和数据库
前言
主要运用了scrapy持久化存储操作,下面主要展示spider和管道文件及一些设置。源码
爬取的是itcast师资信息http://www.itcast.cn/channel/teacher.shtml#ajavaee
爬虫文件(test1)
这部分主要是对内容解析
import scrapy
class Test1Spider(scrapy.Spider):
name = 'test1'
# allowed_domains = ['https://www.baidu.com/']
start_urls = ['http://www.itcast.cn/channel/teacher.shtml#ajavaee']
def parse(self, response):
li_list = response.xpath('/html/body/div[10]/div/div[2]/ul/li')
for li in li_list:
item={}
item["name"] = li.xpath(".//h2/text()").extract_first()
if li.xpath(".//p/span[2]/text()").extract_first()!= None:
item["title"] = li.xpath(".//p/span[1]/text()").extract_first() + li.xpath(".//p/span[2]/text()").extract_first()
else:
item["title"]= li.xpath(".//p/span[1]/text()").extract_first()
yield item
pipelines.py
这部分是对解析后的内容进行持久化存储
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pymysql
#存储到文件中
class TestprojectPipeline:
fp =None
def open_spider(self,spider):
print("开始爬虫......")
self.fp = open('./shizi.text','w',encoding='utf-8')
def process_item(self, item, spider):
author = item['name']
content = item['title']
self.fp.write(author+':'+content+'\\n')
return item
def close_spider(self,spider):
print("爬虫结束!")
self.fp.close()
#存储到数据库中
class mysqlPileLine(object):
conn = None
cursor = None
def open_spider(self,spider):
self.conn = pymysql.Connect(host='127.0.0.1',port=3306,user='root',password='zpx',db='pydata',charset='utf8')
def process_item(self,item,spider):
self.cursor = self.conn.cursor()
try:
self.cursor.execute('insert into shizi value ("%s","%s")'%(item["name"],item["title"]))
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback()
return item
def close_spider(self,spider):
self.cursor.close()
self.conn.close()
setting.py
# Scrapy settings for testproject project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'testproject'
SPIDER_MODULES = ['testproject.spiders']
NEWSPIDER_MODULE = 'testproject.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.17 (KHTML, like Gecko) Version/12.0.1 Safari/605.1.17"
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
LOG_LEVEL= 'WARNING'
#显示的日志等级
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'testproject.middlewares.TestprojectSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'testproject.middlewares.TestprojectDownloaderMiddleware': 543,
}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'testproject.pipelines.TestprojectPipeline': 300,
'testproject.pipelines.mysqlPileLine': 301,
#两种持久化存储的优先级,数越小,优先级越高
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
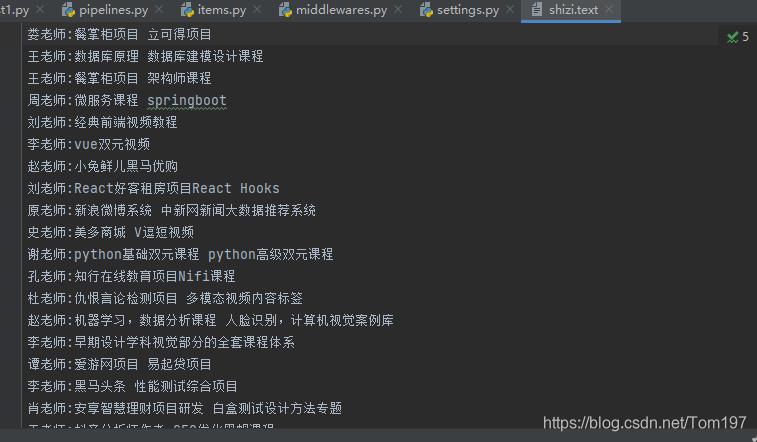
运行结果



以上是关于python运行后中断,存入文件内容完整吗的主要内容,如果未能解决你的问题,请参考以下文章