HMM是啥意思?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HMM是啥意思?相关的知识,希望对你有一定的参考价值。
意思?

隐马尔可夫模型(HMM)是指隐马尔可夫模型,是一种用于描述参数未知的马尔可夫过程的统计模型。困难在于从可观察的参数中确定过程的隐藏参数。这些参数然后被用于进一步的分析,例如模式识别。
隐马尔可夫模型最早是由伦纳德·鲍姆(Leonard E. Baum)和其他作者在20世纪60年代下半叶的一系列统计论文中描述的。隐马尔可夫模型的最初应用之一是语音识别,始于20世纪70年代中期。
20世纪80年代后半期,隐马尔可夫模型开始应用于生物序列的分析,特别是DNA。自此,隐马尔可夫模型逐渐成为生物信息学领域不可或缺的技术。
扩展资料:
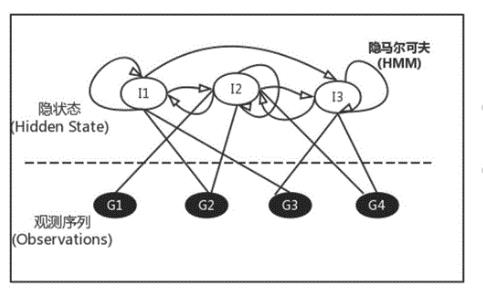
隐马尔可夫模型三大假设。
1)齐次马尔可夫假设。又叫一阶马尔可夫假设,即任意时刻的状态只依赖前一时刻的状态,与其他时刻无关。符号表示为:
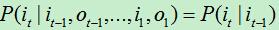
2)观测独立性假设。任意时刻的观测只依赖于该时刻的状态,与其他状态无关。
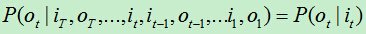
3)参数不变性假设。上面介绍的三大要素不随时间的变化而改变,即在整个训练过程中一直保持不变。
参考资料来源:百度百科-隐马尔可夫模型
参考技术AHMM是隐马尔可夫模型(Hidden Markov Model,HMM),即是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数。然后利用这些参数来作进一步的分析,例如模式识别。
HMM算是个特别常见的模型,早在我没有挖ML这个坑的时候,就已经在用HMM做基于字符序列标注的分词和词性标注了,甚至照葫芦画瓢实现了一个2阶的HMM分词器。隐马尔可夫模型是一个数学模型,到目前为之,它一直被认为是实现快速精确的语音识别系统的最成功的方法。复杂的语音识别问题通过隐含马尔可夫模型能非常简单地被表述、解决。

扩展资料:
隐马尔可夫模型的状态不能直接观察到,但能通过观测向量序列观察到,每个观测向量都是通过某些概率密度分布表现为各种状态,每一个观测向量是由一个具有相应概率密度分布的状态序列产生。所以,隐马尔可夫模型是一个双重随机过程,具有一定状态数的隐马尔可夫链和显示随机函数集。
其实对于HMM来说,如果提前知道所有隐含状态之间的转换概率和所有隐含状态到所有可见状态之间的输出概率,做模拟是相当容易的。但是应用HMM模型时候呢,往往是缺失了一部分信息的,有时候你知道骰子有几种,每种骰子是什么,但是不知道掷出来的骰子序列;有时候你只是看到了很多次掷骰子的结果,剩下的什么都不知道。
参考资料:百度百科-隐马尔可夫模型
参考技术B hmm的意思很多。有人说,这类象声词比普通的词汇更难掌握,本人严重同意。hmm可以表:
同意
怀疑
犹豫
(拖延时间发出的)嗯嗯声
满意
我的回答已经很详细了
我查过了 hmm不是单词的缩写
在这里应该是满意的意思 参考技术C
隐马尔可夫模型(HMM)是指隐马尔可夫模型,是一种用于描述参数未知的马尔可夫过程的统计模型。困难在于从可观察的参数中确定过程的隐藏参数。这些参数然后被用于进一步的分析,例如模式识别。
隐马尔可夫模型最早是由伦纳德·鲍姆(Leonard E. Baum)和其他作者在20世纪60年代下半叶的一系列统计论文中描述的。隐马尔可夫模型的最初应用之一是语音识别,始于20世纪70年代中期。
20世纪80年代后半期,隐马尔可夫模型开始应用于生物序列的分析,特别是DNA。自此,隐马尔可夫模型逐渐成为生物信息学领域不可或缺的技术。
扩展资料:
隐马尔可夫模型三大假设。
1)齐次马尔可夫假设。又叫一阶马尔可夫假设,即任意时刻的状态只依赖前一时刻的状态,与其他时刻无关。符号表示为:
2)观测独立性假设。任意时刻的观测只依赖于该时刻的状态,与其他状态无关。
3)参数不变性假设。上面介绍的三大要素不随时间的变化而改变,即在整个训练过程中一直保持不变。
参考资料来源:百度百科-隐马尔可夫模型
参考技术D 是 嗯 的意思语音识别中区分性训最大似然估计的区别是啥?
参考技术A语音识别系统的一般架构如左图,分训练和解码两阶段。训练,即通过大量标注的语音数据训练声学模型,包括GMM-HMM、DNN-HMM和RNN+CTC等;解码,即通过声学模型和语言模型将训练集外的语音数据识别成文字。目前常用的开源工具有HTK Speech Recognition Toolkit,Kaldi ASR以及Tensorflow(speech-to-text-wavenet)实现端到端系统。我以古老而又经典的HTK为例,来阐述语音识别领域涉及到的概念及其原理。HTK提供了丰富的语音数据处理,以及训练和解码的工具。 语音识别,分为孤立词和连续词语音识别系统。早期,1952年贝尔实验室和1962年IBM实现的都是孤立词(特定人的数字及个别英文单词)识别系统。连续词识别,因为不同人在不同的场景下会有不同的语气和停顿,很难确定词边界,切分的帧数也未必相同;而且识别结果,需要语言模型来进行打分后处理,得到合乎逻辑的结果。

由于神经网络强大的建模能力,End-to-end的输出标签也不再需要像传统架构一样的进行细分。例如对于中文,输出不再需要进行细分为状态、音素或者声韵母,直接将汉字作为输出即可;对于英文,考虑到英文单词的数量庞大,可以使用字母作为输出标签。从这一点出发,我们可以认为神经网络将声学符号到字符串的映射关系也一并建模学习了出来,这部分是在传统的框架中时词典所应承担的任务。针对这个模块,传统框架中有一个专门的建模单元叫做G2P(grapheme-to-phoneme),来处理集外词(out of vocabulary,OOV)。在end-to-end的声学模型中,可以没有词典,没有OOV,也没有G2P。这些全都被建模在一个神经网络中。另外,在传统的框架结构中,语音需要分帧,加窗,提取特征,包括MFCC、PLP等等。在基于神经网络的声学模型中,通常使用更裸的Fbank特征。在End-to-en的识别中,使用更简单的特征比如FFT点,也是常见的做法。或许在不久的将来,语音的采样点也可以作为输入,这就是更加彻底的End-to-end声学模型。除此之外,End-to-end的声学模型中已经带有了语言模型的信息,它是通过RNN在输出序列上学习得到的。但这个语言模型仍然比较弱,如果外加一个更大数据量的语言模型,解码的效果会更好。因此,End-to-end现在指声学模型部分,等到不需要语言模型的时候,才是完全的end-to-end。

以上是关于HMM是啥意思?的主要内容,如果未能解决你的问题,请参考以下文章