Python学习笔记1——Python基础
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python学习笔记1——Python基础相关的知识,希望对你有一定的参考价值。
一. 数据类型和变量
- 整数:十六进制用0x前缀和0-9,a-f表示
- 浮点数:小数,科学计数法:10用e代替;整数和浮点数在计算机内部存储的方式是不同的,整数运算永远是精确的(包括除法),浮点数运算则可能会有四舍五入的误差
- 字符串和编码
(1)以单引号‘或双引号“括起来的任意文本。
(2)可以用转义字符\来标识‘和“。(\n:换行(Python允许使用’’’…’’’格式表示多行内容,eg。’’’a…b…c’’’),\t:制表符,\\:表示\,)
(3)r’’表示’’内部的字符默认不转义
(4)编码:

ASCII编码:1个字节(包括大小写英文字母,数字和一些符号)
Unicode编码:把所有语言都统一到一套编码里,清除乱码问题(多为2字节,把ASCII编码的字符用Unicode编码,在前面补8个0)
UTF-8:把Unicode编码转化为“可变长编码“,因为Unicode编码比ASCII编码需要多一倍的存储空间,若文本全为英文的话,及其不节约。
~~ASCII编码实际上可以被看成是UTF-8编码的一部分。
~~在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就装换为UTF-8编码
(5)Python3版本中,字符串是以Unicode编码,即支持多语言。ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符。
(6)如果要在网络上传输,或者保存到磁盘上,就需要把字符串变为以字节为单位的bytes,用带b前缀的单引号或双引号表示:x=b’ABC’。encode()将字符变为bytes,decode()将bytes变为字符。

(7)在操作字符串时,我们经常遇到str和bytes的互相转换。为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。
(8)由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3 # -*- coding: utf-8 -*-
第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
申明了UTF-8编码并不意味着你的.py文件就是UTF-8编码的,必须并且要确保文本编辑器正在使用UTF-8 without BOM编码:
(9)格式化:%
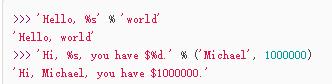
%d:整数
%f:浮点数
%s:字符串
%x:十六进制整数
%%:%
4.布尔值:True和False;and、or和not运算
在python中,and和or执行布尔逻辑运算时,并不返回布尔值,而是返回他们实际进行比较的值之一。在布尔上下文中从左到右演算表达式的值。对于and,如果布尔上下文中的所有值为真,那么and返回最后一个值;如果布尔上下文中的某个值为假,则and返回第一个假值。对于or,如果有值为真,则返回第一个真值,若所有值都为假,则返回最后一个假值。
5.空值:None,不能理解为0。
6.变量:变量名必须是大小写英文、数字和_的组合。
动态语言:

静态语言:

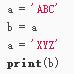
b:ABC
7 . 常量:通常用全部大写的变量名表示常量
8. 1.1+1.1+1.1=3.3000000000003:因为精度损失
二. 条件判断

三. 循环
(1)for x in ..

(2)while

四. 列表
(1)list是一种有序的集合,可以随时添加和删除其中的元素
classmates = [‘Michael‘, ‘Bob‘, ‘Tracy‘]
(2)用len()函数可以获得list元素的个数,用索引来访问list中每一个位置的元素,记得索引是从0开始的当索引超出了范围时,Python会报一个IndexError错误,所以,要确保索引不要越界,记得最后一个元素的索引是len(classmates) - 1。
(3)如果要取最后一个元素,除了计算索引位置外,还可以用-1做索引,直接获取最后一个元素。
(4)list元素也可以是另一个list
五. 元祖tuple
(1)不可变的列表(指向永远不变);除改变列表内容的方法外,其他方法均适用于元组;因此:索引、切片、len、print可用;append、extend、del等不可用
classmates = (‘Michael‘, ‘Bob‘, ‘Tracy‘)
(2)因为tuple不可变,所以代码更安全。如果可能,能用tuple代替list就尽量用tuple。
(3)定义一个空的tuple:t = ()
(4)t=(1):定义的不是tuple,而是1这个数,只有1个元素的tuple定义时必须加一个逗号,。t=(1,)
六. 字典
(1) Python内置了字典:dict的支持,dict全称dictionary,在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度
my_dict={‘john‘:1234,‘Mike‘:5678,‘Bob‘:8765}
my_dict[‘Bob‘]
(2) 给定一个名字,比如‘Michael‘:95,dict在内部就可以直接计算出Michael对应的存放成绩的“页码”,也就是95这个数字存放的内存地址,直接取出来,所以速度非常快
(3) dict内部存放的顺序和key放入的顺序是没有关系的
(4) 和list比较,查找和插入的速度极快,不会随着key的增加而增加;需要占用大量的内存,内存浪费多。
(5) 要保证hash的正确性,作为key的对象就不能变。在Python中,字符串、整数等都是不可变的,因此,可以放心地作为key。而list是可变的,就不能作为key
(6) 字典预算符合方法
len(my_dict)
key in my_dict 快速判断key是否为字典中的键:O(1);==my_dict.has_key(key)
for key in my_dict 枚举字典中的键:键是无序的
my_dict.items() 全部的键-值对;返回的键值对是以列表的形式
my_dict.keys() 全部的键
my_dict.values() 全部的值
my_dict.clear() 清空字典
七. 集合
(1) 无序不重复元素(键)集;和字典类似,但是无“值”
创建: x=set()
x={key1,key2,...}
添加和删除 x.add(‘body‘)
x.remove(‘body‘)
集合的运算符: - & | !=
(2) set的原理和dict一样,所以,同样不可以放入可变对象,因为无法判断两个可变对象是否相等,也就无法保证set内部“不会有重复元素”
(3) 中文分词————算法:正向最大匹配(从左到右取尽可能长的词)
(1)加载词典:lexicon.txt
def load_dic(filename): f= open(filename) word_dic=set() max_length=1 for line in f: word=unicode(line.strip(),‘utf-8‘) word_dict.add(word) if len(word)>max_len: max_len=len(word) return max_len,word_dict
(2)正向最大匹配分词
def fmm_word_seg(sent,max_len,word_dict): begin=0 words=[] sent=unicode(sent,‘utf-8‘) while begin<len(sent): for end in range(begin+max_len,begin,-1): if sent[begin:end] in word_dict: words.append(sent[begin:end]) break begin=end return words
(3)应用
max_len,word_dict=load_dict(‘lexcion.txt‘) sent=raw_input(‘Input a sententce:‘) words =fmm_word_seg(sent,max_len,word_dict) for word in words: print word
以上是关于Python学习笔记1——Python基础的主要内容,如果未能解决你的问题,请参考以下文章