Hbase的WAL在RegionServer基本调用过程
Posted 偶素浅小浅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hbase的WAL在RegionServer基本调用过程相关的知识,希望对你有一定的参考价值。
版权声明:本文由熊训德原创文章,转载请注明出处:
文章原文链接:https://www.qcloud.com/community/article/221
来源:腾云阁 https://www.qcloud.com/community
Hbase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。本文档用于说明hbase的wal简单原理以及从源码的角度分析一个“写”请求是如何到达wal,wal又会做哪些请求。
本文档用于说明hbase的wal简单原理以及从源码的角度分析一个“写”请求是如何到达wal,wal又会做哪些请求。特别说明Hbase不同版本的wal的源码差异比较大,但是原理几乎类似,本文档是采用当前线上使用版本(Hbase1.1.3)来分析的。
简单原理
有关hbase的wal基本原理在《Hbase权威指南》以及网络教程中叙述的算比较清晰详尽,在此只做简单的叙述。
hbase是基于LSM树的存储系统,它使用日志文件和内存存储来的存储架构将随机写转换成顺序写,以此保证稳定的数据插入速率。而这里说的日志文件即是wal文件,用于在服务器崩溃后回滚还没持久化的数据。
WAL(Write-Ahead-Log)是HBase的RegionServer在处理数据插入和删除的过程中用来记录操作内容的一种日志。大致过程如下图所示,首先客户端启动一个操作来修改数据,每一个修改都封装到KeyValue对象实例中,并通过RPC调用发送到含有匹配Region的HRegionServer。一旦KeyValue到达,它们就会被发送管理相应行的HRegion实例。数据被写到WAL,然后被放入到实际拥有记录的存储文件的MemStore中。同时还会检查MemStore是否满了,如果满了就会被刷写到磁盘中去。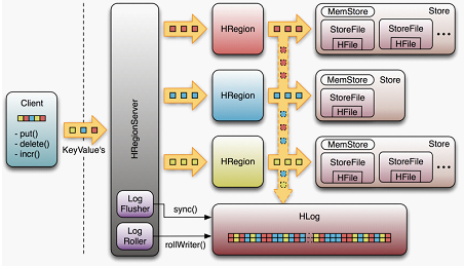
wal调用链源码分析
本节将从源码角度如上所简述分析hbase的一个“写”过程。
其中基本调用过程如下:
从时序图中可以大体看到
-
首先client端先把put/delete等api操作封装成List,然后使用protobuf协议使用rpc服务发送到对应的HRegionServer,HRegionServer调用execRegionServerService()方法解析发送过来的protobuf协议二进制包,通过serviceName找到相应的service并调用callMethod方法执行:

-
put/delet等“写”操作会使用MultiRowMutationService这个service来作用,在service中将会调用mutateRows()方法去处理List,真正调用mutateRows()的是MultiRowMutationService的一个实现类MultiRowMutationEndpoint,MultiRowMutationEndpoint类实现了hbase的行事务。从MultiRowMutationEndpoint类文档可以看出其主要作用:
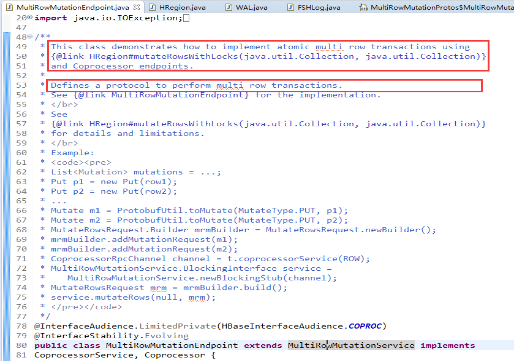
mutateRows()方法会row所找到对应的Region,并调用其对应实例HRegion的mutateRowsWithLocks方法具体实现写入过程。
-
在HRegion类中mutateRowsWithLocks方法查看有没执行器(RowProcessor),如果没有则创建一个再调用processRowsWithLocks()方法。processRowsWithLocks方法是整个“写”操作最核心的方法:把写wal,刷wal以及写memstore流程都在这里流转。在这里包括异常处理一共有14步之多。
它的原型如下:

其中processor的实现类是MultiRowMutationProcessor。
虽然processRowsWithLocks方法步骤很多,但是最关键的是如下几步:

在这里,HRegion将会对Region加锁,加锁的方式是把所有写row相关的行锁都拿到的二阶段锁方式。
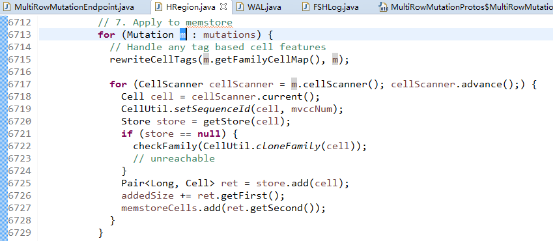
在这里将会把List放入,但是这里并不是真正的放到了memstore,真正的执行会等sync()方法把日志或者说WALEdite真正刷入磁盘后,通过mvcc版本号异步通知再把数据写到memstore。

在这里HRegion会把封装好的WALEdit使用FSHLog的append方法追加到日志文件,但是由于文件本身在内存中有缓存的原因,还需要调用sync刷入磁盘。这里只是把WALEdit数据放到一个LMAX Disrutpor RingBuffer中。这个RingBuffer是一个线程安全的消息队列,在wal中主要用于有效且安全的协调多个生产者一个消费者模型。其中多个生产者就是这个append方法,将会有很多client产生数据都放到这个消息队列中,但是只有一个消费者从这个队列中取数据并调用sync方法把数据从缓存刷到磁盘,这样能保证WAL日志并发写入时日志的全局唯一顺序。
(其中有关LMAX Disrutpor RingBuffer可以参看文章,介绍的非常详尽:https://github.com/LMAX-Exchange/disruptor/wiki/Introduction)

在这步中会会调用syncOrDefer方法,除了metaRegion,syncOrDefer将根据client设置的持久化等级选择是否调用wal(FSHLog)的sync方法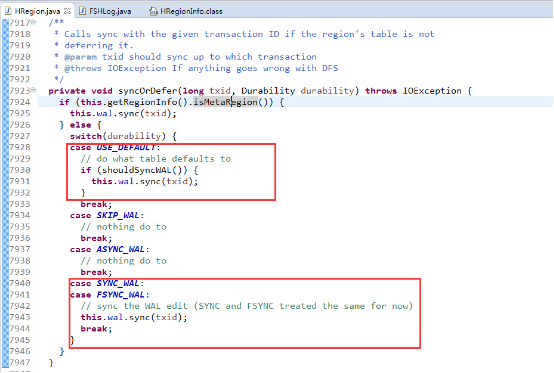
HBase中可以通过设置WAL的持久化等级决定是否开启WAL机制、以及HLog的落盘方式。
client可以通过设置WAL持久化等级,如代码:put.setDurability(Durability. SYNC_WAL );
1.1.3版本的WAL的持久化等级分为如下四个等级:
USER_DEFAULT:默认如果用户没有指定持久化等级,HBase使用SYNC_WAL等级持久化数据。
SKIP_WAL:只写缓存,不写HLog日志。这种方式因为只写内存(memstore),因此可以提升写入性能,但是数据有丢失的风险。
ASYNC_WAL:异步将数据写入HLog日志中。
SYNC_WAL:同步将数据写入日志文件中,有可能只是被写入文件系统中,并没有真正落盘。
FSYNC_WAL:同步将数据写入日志文件并强制落盘。最严格的日志写入等级,可以保证数据不会丢失,但是性能相对比较差。
如代码中所示当前sync_wal和fsync_wal采用的是同一策略都是:调用HFLog的sync()方法。sync()是一个阻塞方法,需要等到数据真正的刷到磁盘后,便会唤醒它,然后工作线程返回写入memstore,完成一次“写”操作。
小结
Hbase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。本文档在介绍hbase基本“写”原理后着重从源码角度,比较浅显地分析了一个“写”操作后在RegionServer的调用过程,为以后继续更深入学习研究hbase“写”过程梳理了脉络。
以上是关于Hbase的WAL在RegionServer基本调用过程的主要内容,如果未能解决你的问题,请参考以下文章
记一次HBase RegionServer 经常挂掉 故障排查过程