正则表达式如何换行且有空格提取
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式如何换行且有空格提取相关的知识,希望对你有一定的参考价值。
如下,怎么用正则表达式提取出68.00这个数值,jmeter后置处理器的正则表达式
</span><strong class="price">¥<em id="totalPayable">
68.00
</em></strong></div>
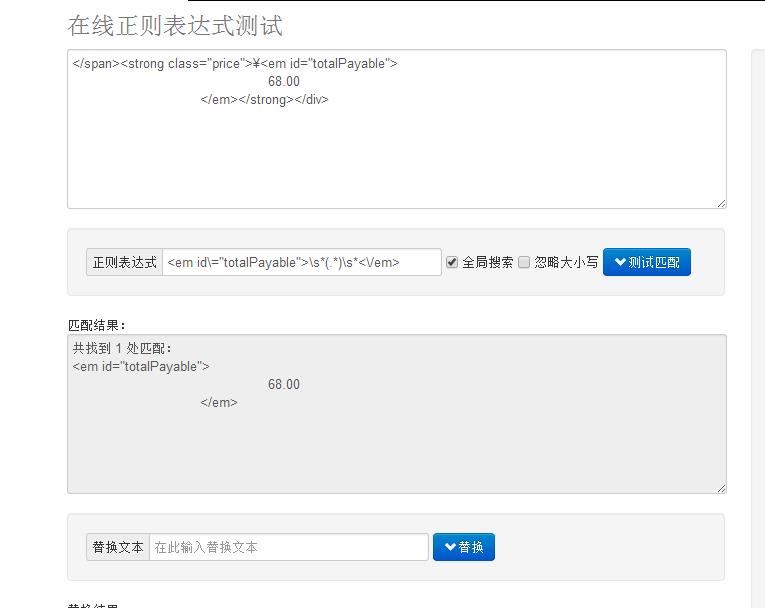
取分组1

good,提取出来了,你这个在线测试工具?发下地址给我吧
参考技术A <em id\="totalPayable">\s*(.*)\s*<\/em>追问good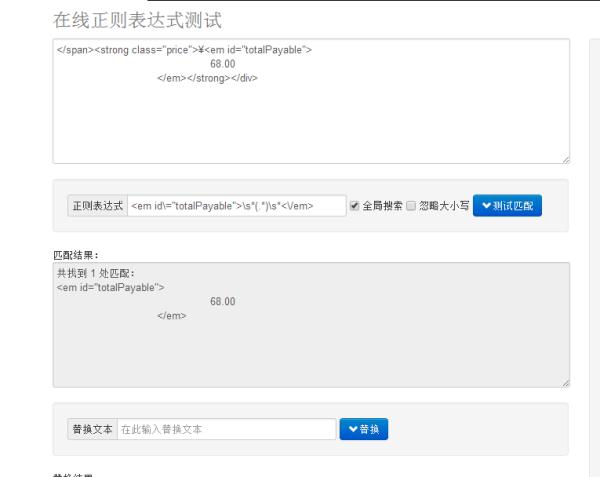
允许单词之间有空格的正则表达式
【中文标题】允许单词之间有空格的正则表达式【英文标题】:Regular expression to allow spaces between words 【发布时间】:2013-03-06 13:11:44 【问题描述】:我想要一个禁止符号并且只允许字母和数字的正则表达式。下面的正则表达式效果很好,但它不允许单词之间有空格。
^[a-zA-Z0-9_]*$
例如,当使用这个正则表达式“HelloWorld”可以,但“Hello World”不匹配。
如何调整它以允许空格?
【问题讨论】:
【参考方案1】:tl;博士
只需在 character class 中添加一个空格即可。
^[a-zA-Z0-9_ ]*$
现在,如果你想严格...
以上内容并不完全正确。由于* 表示零个或多个,它会匹配以下所有通常不匹配的情况:
最初我认为这些细节不值得讨论,因为 OP 提出了一个如此基本的问题,以至于严格性似乎不是问题。既然这个问题已经流行起来了,我想说...
...使用@stema's answer。
在我看来(不使用\w)转换为:
^[a-zA-Z0-9_]+( [a-zA-Z0-9_]+)*$
(无论如何,请为@stema投票。)
关于这个(和@stema 的)答案的一些注意事项:
如果您想在单词之间允许 多个 空格(例如,如果您想允许意外的双空格,或者如果您正在处理从 PDF 复制粘贴的文本),然后在空格后添加+:
^\w+( +\w+)*$
如果您想允许制表符和换行符(空白字符),则将空格替换为\s+:
^\w+(\s+\w+)*$
这里我建议默认使用+,因为例如,Windows 换行符由 两个 连续的空白字符组成,\r\n,因此您需要+ 来捕获这两个字符.
还是不行?
检查您使用的正则表达式的方言。*在像 Java 这样的语言中,您必须转义反斜杠,ie \\w 和 \\s .在较旧或更基本的语言和实用程序中,例如 sed、\w 和 \s 未定义,因此请使用字符类将它们写出来,eg [a-zA-Z0-9_] 和 [\f\n\p\r\t],分别。
* 我知道这个问题被标记为vb.net,但根据超过 25,000 次浏览,我猜想遇到这个问题的不仅仅是那些人。目前它是 google 搜索词组的第一次点击,正则表达式空格词。
【讨论】:
它允许空字符串 哇,好简单!谢谢。是不是有一个网站或什么东西可以用来生成正则表达式,对于菜鸟我的意思是...... @Pierre - 接受人工指令并将其转换为明确的规则是相当困难的。 (人类语言是流动的,充满歧义,我们的大脑完成了解决问题和填补空白所需的大部分工作。计算机没有这样的大脑,模仿大脑的聪明尝试还不够强大。 ) 确实存在像debuggex.com 这样的工具,它们可以直观地代表您的正则表达式,但尽管它很吸引人,但对于初学者来说可能不是很有帮助。不过,我建议使用interactive tutorial 来了解基础知识。 是的,如果只有空格,您的正则表达式也会匹配。我的回复是对 Neha choudary 的评论。 @Pierre 三年后——我今天遇到了这个问题,看到了你的评论;我使用 regex hero (regexhero.net) 来测试正则表达式。我认为在线版本仅适用于带有 Silverlight 的 Internet Explorer,但总比没有好。【参考方案2】:一种可能性是将空格添加到您的字符类中,就像 acheong87 建议的那样,这取决于您对模式的严格程度,因为这也允许以 5 个空格开头的字符串,或仅由空格组成的字符串.
另一种可能性是定义一个模式:
我将使用\w,这在大多数正则表达式风格中与[a-zA-Z0-9_] 相同(在某些情况下它基于Unicode)
^\w+( \w+)*$
这将允许一系列至少一个单词,并且单词被空格分隔。
^匹配字符串的开头
\w+匹配一系列至少一个单词字符
( \w+)* 是重复 0 次或多次的组。在组中,它需要一个空格,后跟一系列至少一个单词字符
$ 匹配字符串的结尾
【讨论】:
This : regex101.com/#javascript 也为您要分析的正则表达式模式提供了很好的解释。 不错的正则表达式,比很多 [0-9a-z] 等简单得多 我在我的正则表达式解释器中发现我需要将整个字符串包装在括号中,以便第一个匹配是整个字符串,而不仅仅是第一个空格之后的单词。那是^- (\w+( \w+)*)$ 为我工作。【参考方案3】:
这个对我有用
([\w ]+)
【讨论】:
这个答案缺乏解释。【参考方案4】:尝试:
^(\w+ ?)*$
解释:
\w - alias for [a-zA-Z_0-9]
"whitespace"? - allow whitespace after word, set is as optional
【讨论】:
这会导致回溯地狱。 例如,给定一个不匹配的字符串ggggggggggggggggggggggggggggggggggggg;,由于过度回溯,您的正则表达式将需要很长时间才能达到结果。
好的,那你有什么建议?【参考方案5】:
我假设您不想要前导/尾随空格。这意味着您必须将正则表达式拆分为“第一个字符”、“中间的东西”和“最后一个字符”:
^[a-zA-Z0-9_][a-zA-Z0-9_ ]*[a-zA-Z0-9_]$
或者如果你使用类似 perl 的语法:
^\w[\w ]*\w$
另外:如果你故意将你的正则表达式写成它也允许空字符串,你必须让整个事情成为可选的:
^(\w[\w ]*\w)?$
如果您只想允许单个空格字符,它看起来有点不同:
^((\w+ )*\w+)?$
这匹配 0..n 个单词,后跟一个空格,再加上一个不带空格的单词。并使整个事情成为可选的以允许空字符串。
【讨论】:
空格和\s 不等价。 \s 不仅仅匹配空格。
@nhahtdh:感谢您的评论。我猜我太习惯于匹配空白了。答案是固定的。
第一个表达式中是否有可能缺少右括号)?我不确定我没有尝试过。
@ssinfod:很好。实际上,在该示例中,左括号是多余的。谢谢。
请注意,此答案不会匹配单个字符串(它将匹配至少两个字符)。要解决此问题,您可以为单个字符添加测试:^\w$|^\w[\w ]*\w$【参考方案6】:
这个正则表达式
^\w+(\s\w+)*$
单词之间只允许一个空格,并且没有前导或尾随空格。
下面是正则表达式的解释:
^ 在字符串的开头断言位置
\w+ 匹配任意单词字符 [a-zA-Z0-9_]
- 量词:
+ 一次到无限次,尽可能多次,按需回馈[贪婪](\s\w+)*
-
量词:
* 介于零和无限次之间,尽可能多次,按需回馈[贪婪]
\s 匹配任意空白字符 [\r\n\t\f ]
\w+ 匹配任意单词字符[a-zA-Z0-9_]- 量词:
+ 一次到无限次,尽可能多次,按需回馈[贪心]$ 在字符串末尾断言位置
【讨论】:
【参考方案7】:这不允许开头的空间。但允许单词之间有空格。还允许在单词之间使用特殊字符。 FirstName 和 LastName 字段的良好正则表达式。
\w+.*$
【讨论】:
这个答案不正确/不准确。此模式匹配一个或多个字母数字、下划线,然后是零个或多个任何非换行符。对 OP 没有好处。【参考方案8】:仅适用于字母:
^([a-zA-Z])+(\s)+[a-zA-Z]+$
对于字母数字值和_:
^(\w)+(\s)+\w+$
【讨论】:
这不是一个好例子,因为 (something)+ 与 (something+) 不同。在第一个示例中,只有单个字符将被捕获为 $1 。【参考方案9】:只需在正则表达式模式的末尾添加一个空格,如下所示:
[a-zA-Z0-9_ ]
【讨论】:
这与accepted answer 有何不同?【参考方案10】:如果您使用的是 JavaScript,那么您可以使用这个正则表达式:
/^[a-z0-9_.-\s]+$/i
例如:
/^[a-z0-9_.-\s]+$/i.test("") //false
/^[a-z0-9_.-\s]+$/i.test("helloworld") //true
/^[a-z0-9_.-\s]+$/i.test("hello world") //true
/^[a-z0-9_.-\s]+$/i.test("none alpha: ɹqɯ") //false
这个正则表达式的唯一缺点是一个完全由空格组成的字符串。 “ ”也会显示为真。
【讨论】:
【参考方案11】:这是我的正则表达式:@"^(?=.3,15$)(?:(?:\pL|\pN)[._()\[\]-]?)*$"
我刚刚在我的正则表达式末尾添加了([\w ]+) *
@"^(?=.3,15$)(?:(?:\pL|\pN)[._()\[\]-]?)([\w ]+)*$"
现在允许字符串有空格。
【讨论】:
【参考方案12】:试试这个:
result = re.search(r"\w+( )\w+", text)
【讨论】:
以上是关于正则表达式如何换行且有空格提取的主要内容,如果未能解决你的问题,请参考以下文章