tomcat集群实现源码级别剖析
Posted 超人汪小建(seaboat)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了tomcat集群实现源码级别剖析相关的知识,希望对你有一定的参考价值。
随着互联网快速发展,各种各样供外部访问的系统越来越多且访问量越来越大,以前Web容器可以包揽接收-逻辑处理-响应整个请求生命周期的工作,现在为了构建让更多用户访问更强大的系统,人们通过不断地业务解耦、架构解耦将web容器的逻辑处理抽离交由其他中间件处理,例如缓存中间件、消息队列中间件、数据存储中间件等等。Web容器负责的工作可能越来越少,但是它确实必不可少的部分,它负责接收用户请求并分别调用各个服务最后响应。可以说目前最受欢迎的web容器是用Java写的tomcat小猫,由于生产上的tomcat考虑负载均衡及高可用性,它一般以集群模式运行,所以这篇文章主要探讨的是tomcat的集群功能如何实现且生产部署如何选型。
如果说一个web应用不涉及会话的话,那么做集群是相当简单的,因为节点都是无状态的,集群内各个节点无需互相通信,只需要将各个请求均匀分配到集群节点即可。但基本所有web应用都会使用会话机制,所以做web应用集群时整个难点在于会话数据的同步,当然你可以通过一些策略规避复杂的额数据同步操作,例如把会话信息保存在分布式缓存或数据库中统一集中管理,避免了tomcat集群之间的通信。但这种方式也有不足,要额外引入数据库或缓存服务,同时也要保证它们的高可用性,增加了机器和维护成本。本文假设不使用统一管理会话的模式而是将会话交由tomcat自身集群管理。
集群增量会话管理器——DeltaManager
tomcat集群节点自身完成各自的数据同步,不管访问到哪个节点都能找到对应的会话,如下图,客户端第一次访问生成会话,tomcat自身会将会话增量信息同步到其他节点上,而且是每次请求完成都会同步此次请求过程中对session的所有操作,这样一来下一次请求到集群中任意节点都能找到响应的会话信息,且能保证信息的及时性。

这就是tomcat默认的集群会话管理器——DeltaManager。它主要用于集群中各个节点之间会话状态的同步维护。DeltaManager的职责是将某节点的会话该变同步到集群内其他成员节点上,它属于全节点复制模式,所谓全节点复制是指集群中某个节点的状态变化后需要同步到集群中剩余的节点,非全节点方式可能只是同步到其中某个或若干节点。在集群中全节点会话复制的一个大致步骤如下图所示,客户端发起一个请求,假设通过一定的负载均衡设备分发策略分到其中一个结点node1,如果还未存在session对象的话web容器将会创建一个会话对象,接着执行一些逻辑处理,在对客户端响应之前有个重要的事情是要把session对象同步到集群中其他节点上,最后再响应客户端。当客户端第二次发起请求时,假如分发到node3节点上,由于同步了node1的session会话,所以在执行逻辑时并不会取不到session的值。如果删除某个会话对象则要同时通知其他节点把相应会话删除,如果修改了某个会话的某些属性也同样要更新到其他节点的会话中。
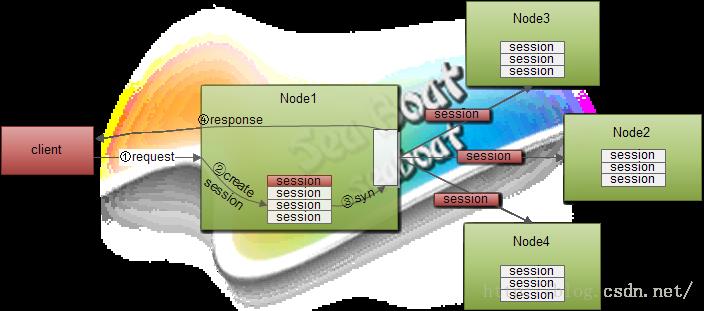
DeltaManager其实就是一个会话同步通信解决方案,除了具备上面提到的全节点复制外,它还有具有只复制会话增量的特性,增量是以一个完整请求为周期,即会将一个请求过程中所有会话修改量在响应前进行集群同步。往下看Tomcat具体实现方案。
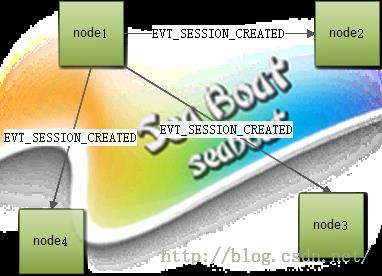
为区分不同的动作必须要先定义好各种事件,例如会话创建事件、会话访问事件、会话失效事件、获取所有会话事件、会话增量事件、会话ID改变事件等等,实际上tomcat集群会有9种事件,集群根据这些不同的事件就可以彼此进行通信,接收方对不同事件做不同的操作。如下图,例如node1节点创建完一个会话后,即向其他三个节点发送EVT_SESSION_CREATED事件,其他三个节点接收到此事件后则各自在自己本地创建一个会话,会话包含了两个很重要的属性——会话ID和创建时间,这两个属性都必须由node1节点跟着EVT_SESSION_CREATED一起发送出去,本地会话创建成功后即完成了会话创建同步工作,此时你通过会话ID查找集群中任意一个节点都可以找到对应的会话。同样对于会话访问事件,node1向其他节点发送EVT_SESSION_ACCESSED事件及会话ID,其他节点根据会话ID找到对应会话并更新会话最后访问时间,以免被认为是过期会话而被清理。类似的还有会话失效事件(同步集群销毁某会话)、会话ID改变事件(同步集群更改会话ID)等等操作。
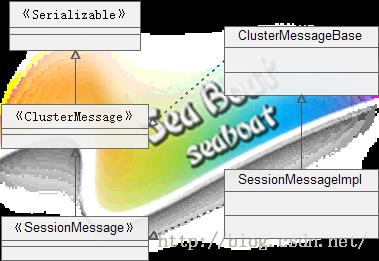
Tomcat使用SessionMessageImpl类定义了各种集群通信事件及操作方法,在整个集群通信过程中就是按照此类定义好的事件进行通信,SessionMessageImpl包含的事件如下{ EVT_SESSION_CREATED、EVT_SESSION_EXPIRED、EVT_SESSION_ACCESSED、EVT_GET_ALL_SESSIONS、EVT_SESSION_DELTA、EVT_ALL_SESSION_DATA、EVT_ALL_SESSION_TRANSFERCOMPLETE、EVT_CHANGE_SESSION_ID、EVT_ALL_SESSION_NOCONTEXTMANAGER },除此之外它继承了序列化接口(方便序列化)、集群消息接口(集群的操作)、会话消息接口(事件定义及会话操作)。
集群增量会话管理器DeltaManager可以说是通过SessionMessageImpl消息来管理DeltaSession,即根据SessionMessageImpl里面的事件响应不同的操作。DeltaManager存在一个messageDataReceived(ClusterMessage cmsg)方法,此方法会在本节点接收到其他节点发送过来的消息后被调用,且传入的参数为ClusterMessage类型,可转化为SessionMessage类型,然后根据SessionMessage定义的9种事件做不同处理。其中有一个事件需要关注的是EVT_SESSION_DELTA,它是对会话增量同步处理的事件,某个节点在一个完整的请求过程中对某会话相关属性的所有操作被抽象到了DeltaRequest对象中,而DeltaRequest被序列化后会放到SessionMessage中,所以EVT_SESSION_DELTA事件处理逻辑就是从SessionMessage获取并反序列化出DeltaRequest对象,再将DeltaRequest包含的对某个会话的所有操作同步到本地该会话中,至此完成会话增量同步。
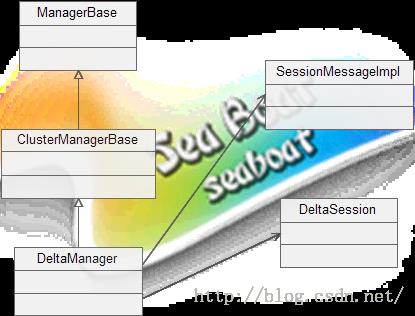
总的来说DeltaManager就是DeltaSession的管理器,它提供了会话增量的同步方式而不是全量同步,极大提高了同步效率。
集群备份会话管理器——BackupManager
全节点复制的网络流量随节点数量增加呈平方趋势增长,也正是因为这个因素导致无法构建较大规模的集群,为了使集群节点能更加大,首要解决的就是数据复制时流量增长的问题,于是tomcat提出了另外一种会话管理方式,每个会话只会有一个备份,它使会话备份的网络流量随节点数量的增加呈线性趋势增长,大大减少了网络流量和逻辑操作,可构建较大的集群。
下面看看这种方式具体的工作机制,集群一般是通过负载均衡对外提供整体服务,所有节点被隐藏在后端组成一个整体。前面各种模式的实现都无需负载均衡协助,所以图中都把负载均衡省略了。最常见的负载方式是前面用apache拖所有节点,它支持将类似“326257DA6DB76F8D2E38F2C4540D1DEA.tomcat1”的会话id进行分解,定位到tomcat集群中以tomcat1命名的节点上(这种方式称为Session Stick,由apache jk模块实现)。每个会话存在一个原件和一个备份,且备份与原件不会保存在同一个节点上,如下图,例如当客户端发起请求后通过负载均衡被分发到tomcat1实例节点上,生成一个包含.tomcat1后缀的会话标识,并且tomcat1节点根据一定策略选出此次会话对象备份的节点,然后将包含了{会话id,备份ip}的信息发送给tomcat2、tomcat3、tomcat4,如图中虚线所示,这样每个节点都有一个会话id、备份ip列表,即每个节点都有每个会话的备份ip地址。
完成上面一步后就是将会话内容备份到备份节点上,假如tomcat1的s1、s2两个会话的备份地址为tomcat2,则把会话对象备份到tomcat2中,类似的有tomcat2把s3会话备份到tomcat4,tomcat4把s4、s5两个对话备份到tomcat3,这样集群中所有的会话都已经有了一份备份。当tomcat1一直不出故障,由于Session Stick技术客户端将一直访问到tomcat1节点上,保证一直能获取到会话。而当tomcat1出故障了,这时tomcat也提供了一个failover机制,apache感知到后端集群tomcat1节点被移除了,这时它会把请求随机分配到其他任意节点上,接下去会有两种情况:
①刚好分到了备份节点tomcat2上,此时仍能获取到s1会话,除此之外,tomcat2还要另外做的事是将这个s1会话标记为原件且继续选取一个备份地址备份s1会话,这样一来又有了备份。
②假如分到了非备份节点tomcat3,此时肯定找不到s1会话,于是它将向集群所有节点发问,“请问谁有s1会话的备份ip地址信息?”,因为只有tomcat2有s1的备份地址信息,它接收到询问后应答告知tomcat3节点s1会话的备份在tomcat2,根据这个信息就能查到s1会话了,并且tomcat3在自己本地生成s1会话并标为原件,tomcat2上的副本不变,这样一来同样能找到s1会话,正常完整整个请求处理。
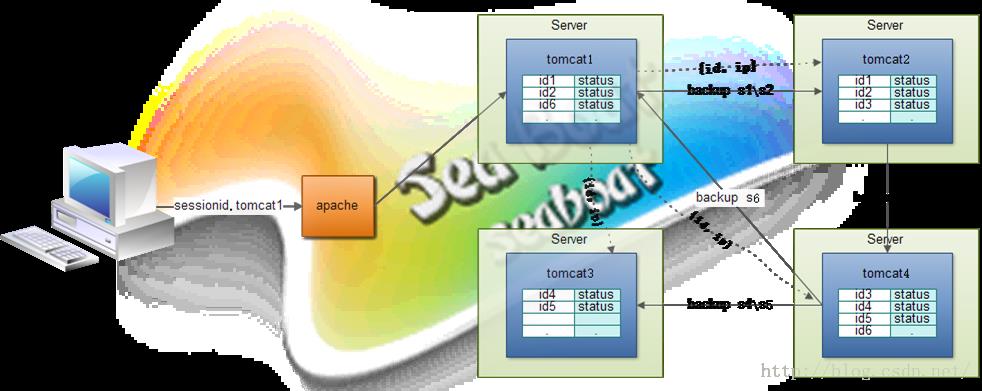
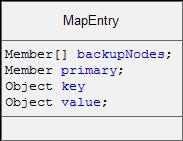
接着分析Tomcat对上面机制详细的实现,正常情况下为了支持高效的并发操作,tomcat的所有会话集使用ConcurrentHashMap<String, MapEntry>结构保存,String类型是指SessionId,MapEntry则是对session、源节点成员及备份节点等的封装(详细的类结构如下图所示,备份节点虽然为数组类型,但实际情况我们只会设置一个备份节点),一般session对象由哪个节点生成则哪个节点为源节点,备份节点则为集群中其他任意一节点,所以MapEntry可以看成是包含了源节点和备份节点信息的会话对象。会话管理器其实就是对会话集操作的封装,从设计角度看,为了改变会话集的操作行为,只需继承ConcurrentHashMap类并重写其中一些方法即可实现,例如put、get、remove等等操作实现跨节点操作。于是tomcat的BackupManager对整个会话集的跨节点操作被封装到一个继承ConcurrentHashMap类的LazyReplicatedMap子类中,而要实现跨节点的操作要做的事很多,例如备份节点列表的维护、备份节点选择、通信协议、序列化&反序列化及复杂的IO操作等等,弄清楚了LazyReplicatedMap的工作原理也就基本清楚BackupManager如何工作。
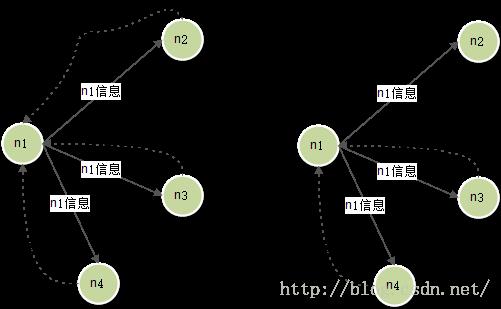
每个节点都要维护一份集群节点信息列表供会话备份路由选择,信息列表的维护主要通过启动时向所有节点广播节点信息及心跳去维护,如下图左,n1启动时向其他节点广播自己的信息,其他节点收到信息后把n1添加到自己的列表,而n1则把n2、n3、n4添加到自己的列表,接着按某一时间间隔继续向其他节点发心跳,如下图右,假如n2未给n1响应信息,n1则把n2从自己的列表中删除。BackupManager使用经典的Round robin算法用于备份节点的选择,它属于平均分配算法,按顺序依次选择节点,例如集群一共有node1、node2、node3三个节点,node1将session1备份到node2,而session2则备份到node3。对于节点信息列表BackupManager是使用HashMap<Member, Long>结构保存,Member是包含了节点信息属性的节点抽象,Long是指节点最新的存活时间,在做心跳时就是根据最新的存活时间和超时阀值判断节点是否失效。
通信的协议及信息载体由MapMessage类定义,通信协议其实就是通信双方约定好的语义,定义的常量包括{ MSG_BACKUP、MSG_RETRIEVE_BACKUP、MSG_PROXY、MSG_REMOVE、MSG_STATE、MSG_START、MSG_STOP、MSG_INIT、MSG_COPY、MSG_STATE_COPY、MSG_ACCESS},这里每个值都代表一个语义,例如MSG_BACKUP表示让接收方把接收到的会话对象进行备份、MSG_REMOVE则表示让接收方按照接收到的会话id把对应的会话删除等等。除此之外MapMessage类还包含valuedata(byte[])、keydata(byte[])、nodes(Member[])、primary(Member),分别表示会话对象字节流、会话id字节流、备份节点、源节点。这样一来所有要素都有了,在备份操作中MapMessage对象就像组成一个句子:“本人会话id为keydata,会话值为valuedata,我的源节点为primary,我现在需要做备份操作”。
另外,序列化&反序列化工作交由jdk的ObjectInputStream、ObjectOutputStream去完成,而复杂的网络IO则交由tribes通信框架完成。
关于源节点、备份节点、代理节点分别代表什么意思,每个集群每个会话只有一个源节点,一个备份节点,若干个代理节点。如下图,node1为源节点,表示会话对象由它创建,保存的是会话对象的原件;node3为备份节点,保存的是会话对象的备份件;node2和node4为代理节点,它们保存的仅仅是会话位置信息,例如备份节点node3的机器的ip。这样分类是为了提供failover能力,①假如刚好源节点宕掉,请求落到备份节点则能获取到会话对象,此时备份节点变为源节点,再从node2、node4中选一个作为备份节点,并且把会话对象拷贝到新备份节点上;②假如备份节点宕掉了,请求一样能从源节点获取到会话对象,但此时会从node2、node4中选一个新备份节点,并把会话对象拷贝到新备份节点上;③假如代理节点宕掉了,一切没影响,正常工作。
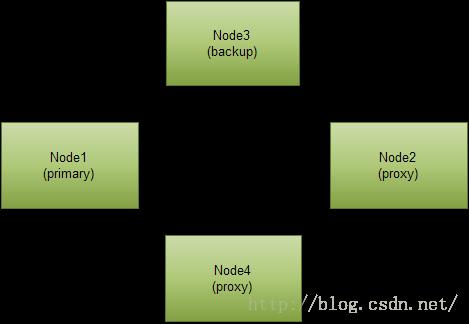
搞清楚上面介绍的基本原理后再看看LazyReplicatedMap具体是如何实现将会话对象既在本地存储又跨节点备份。
首先看下如何它是如何通过调用put方法实现保存,第一步,先实例化用于保存会话相关信息的MapEntry对象,传入的参数key为会话id,value为会话对象,设置当前结点为源节点;第二步,判断会话集中是否已经包含了此会话,如已存在则要删除本地及备份节点上的会话;第三步,使用Round robin算法选出一个备份节点,并赋值到MapEntry对象的备份节点属性;第四步,组装包含MSG_BACKUP标识的MapMessage对象发到备份节点告诉备份节点要备份我传过来的这个会话信息;第五步,组装包含MSG_PROXY标识的MapMessage对象发送到除备份节点外的其他节点,告诉他们“你们是代理,请把此会话的id、源节点、备份节点等信息记录下”;第六步,把MapEntry对象放入本地缓存;
public Object put(Object key, Object value) {
①实例化MapEntry,将key和value传入,并设置源节点为目前节点。
②判断本地内存是否已包含key,如是则不仅要本地remove掉,还要跨节点remove。
③通过Round robin算法从MapMember中选择一个作为备份节点。
④实例化一个包含MSG_BACKUP标识的MapMessage对象并发送给备份节点。
⑤实例化一个包含MSG_PROXY标识的MapMessage对象并发送给除了备份节点外的其他(代理)节点。
⑥put进本地缓存。
}
其次,再看看它如何通过get实现获取会话对象操作:
public Object get(Object key) {
①获取本地的MapEntry对象,它或许直接包含了会话对象,或许包含了会话对象的存放位置信息。
②判断本节点是否属于源节点,如为源节点则直接获取MapEntry对象里面的会话对象并返回。
③判断本节点是否属于备份节点,若为备份节点则直接获取MapEntry对象里面的会话对象作为返回对象,并且还要将本节点升为源节点、重新选取一个新备份节点,把MapEntry对象拷贝到新备份节点。
④判断本节点是否属于代理节点,若为代理节点则向其他节点发送会话对象拷贝请求,“集群中谁有此会话对象请发送给我”,把接收到的会话对象放到本节点并作为返回对象,最后将本节点升为源节点。
}
最后,看看删除会话对象remove操作的实现:
public Object remove(Object key) {
①删除本地此MapEntry对象。
②广播其他节点删除此MapEntry对象。
}
通过上面三个方法已经很清晰描述了新的Map是如何进行跨节点的增删改查的,BackupManager会话管理器就是通过这个新的Map进行会话管理。
以上即是tomcat集群机制源码基本的剖析,两种都有各自的优缺点,全节点模式是两两互相复制的,一旦集群节点数量及访问量大起来,将导致大量的会话信息需要互相复制同步,很容易导致网络阻塞,而且这些同步操作很可能会成为整体性能的瓶颈,根据经验,此种方案在实际生产上推荐的集群节点个数为3-6个,无法组建更大的集群,而且冗余了大量的数据,利用率不高。而会话备份模式则大大减少了网络流量和逻辑操作,可构建较大的集群,生产上可以组成十个以上的节点,虽然这种模式支持更大的集群,但它也有自己的缺点,例如它只有一个数据备份,假如刚好源数据和备份数据所在的机器同时宕掉了,则没办法恢复数据,不过刚好同时宕机的机率很小很小。
以上是关于tomcat集群实现源码级别剖析的主要内容,如果未能解决你的问题,请参考以下文章