萌新笔记——用KMP算法与词典实现屏蔽敏感词(UTF-8编码)
Posted 曾经时光
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了萌新笔记——用KMP算法与词典实现屏蔽敏感词(UTF-8编码)相关的知识,希望对你有一定的参考价值。
前几天写好了字典,又刚好重温了KMP算法,恰逢遇到朋友吐槽最近被和谐的词越来越多了,于是突发奇想,想要自己实现一下敏感词屏蔽。
基本敏感词的屏蔽说起来很简单,只要把字符串中的敏感词替换成“***”就可以了。对于子串的查找,就KMP算法就可以了。但是敏感词这么多,总不能一个一个地遍历看看里面有没有相应的词吧!
于是我想到了前几天写的字典树。如果把它改造一下,并KMP算法结合,似乎可以节约不少时间。
首先说明一下思路:
对于KMP算法,这里不过多阐述。对于敏感词库,如果把它存进字典树,并在每个节点存上它的next值。在进行匹配的时候,遍历主串,提取出单个字(对于UTF-8编码,可以是任何国家的字),然后去字典树的根结点的unordered_map中进行查找是否存在。如果不存在,则对下一个字进行相同处理;如果存在,则进入该子节点,然后继续查找。字典树结构如下图:
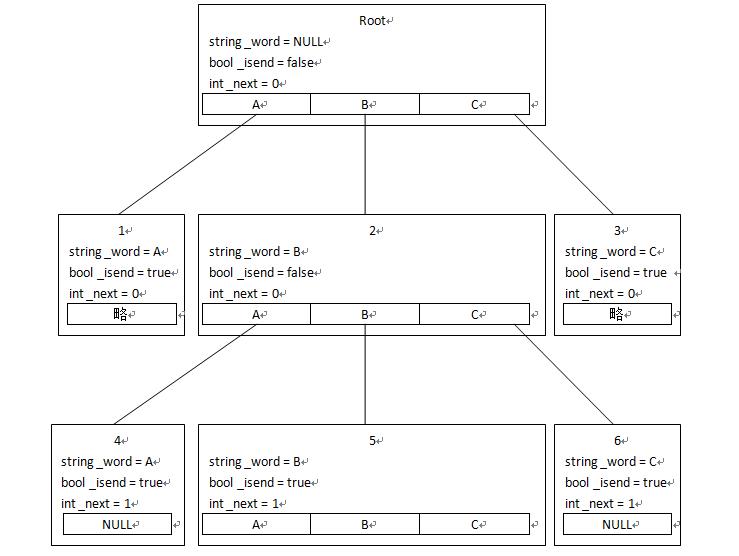
1~6是编号,后面说明一些东西的时候用到。
Root节点里不存任何数据,只是提供一个词典的起始位置。那个表格用的是unordered_map。
对于一个树型结构,如果直接用KMP算法中的next值来确定下一个应该在哪个节点进行查找似乎会有点问题。比如,对于5号节点,next值为1,但是要怎么用这个"1"进入要查找的节点呢?
由于每个节点只需要知道自己如果匹配失败应该跳到哪个节点,我想了以下两种方案:
1、把next改成存着节点的地址,类似线索二叉树,这样可以很方便地进行节点转换。
2、用栈,每次进入子节点,就对原节点的地址进行压栈,next中存的值是要从栈中弹出几个元素。
由于之前的字典树在遍历的时候采用list实现的栈来确定下一个词是哪个,于是我选择用第二种方案。
方案有了,就是如何实现的事了。
我先对字典树的数据结构进行修改:
DictionaryData.h
1 #ifndef __DICTIONARYDATA_H__ 2 #define __DICTIONARYDATA_H__ 3 4 #include <string> 5 #include <unordered_map> 6 #include <memory> 7 8 namespace ccx{ 9 10 using std::string; 11 using std::unordered_map; 12 using std::shared_ptr; 13 14 struct DictElem 15 { 16 string _word; 17 bool _isend;//是否到词尾 18 int _next;//KMP next值 此处有修改,存的是弹栈数量 19 unordered_map<string, shared_ptr<DictElem> > _words; 20 }; 21 22 typedef shared_ptr<DictElem> pDictElem; 23 24 } 25 26 #endif
相应地,字典树的成员函数也要进行修改。
Dictionary.h


1 #ifndef __DICTIONARY_H__ 2 #define __DICTIONARY_H__ 3 4 #include "DictionaryData.h" 5 #include "DictionaryConf.h" 6 7 #include <memory> 8 #include <vector> 9 #include <list> 10 11 namespace ccx{ 12 13 using std::shared_ptr; 14 using std::vector; 15 using std::list; 16 using std::pair; 17 18 class Dictionary 19 { 20 typedef pair<int, int> Loc; 21 typedef unordered_map<string, pDictElem>::iterator WordIt; 22 public: 23 Dictionary(); 24 void push(const string & word);//插入 25 void push(vector<string> & words);//插入 26 bool search(const string & word);//查找 27 bool associate(const string & word, vector<string> & data);//联想 28 string Kmp(const string & word); 29 30 private: 31 bool Kmp(vector<string> & word, vector<Loc> & loc); 32 void getKmpNext(const vector<string> & characters, vector<int> & next); 33 void AddWord(const string & word); 34 void splitWord(const string & word, vector<string> & characters);//把词拆成字 35 int search(vector<string> & data, pDictElem & pcur); 36 pDictElem _dictionary; 37 DictionaryConf _conf; 38 39 //遍历 40 public: 41 string getCurChar(); 42 string getCurWord(); 43 bool isEnd(); 44 void resetIt(); 45 void next(); 46 private: 47 void resetPoint(pDictElem pcur); 48 void next(pDictElem & pcur, list<WordIt> & stackWord, list<pDictElem> & stackDict); 49 void nextWord(pDictElem & pcur, list<WordIt> & stackWord, list<pDictElem> & stackDict); 50 string getCurWord(list<WordIt> & stackWord); 51 52 pDictElem _pcur; 53 WordIt _itcur; 54 55 //用list实现栈,遍历时方便 56 list<WordIt> _stackWord; 57 list<pDictElem> _stackDict; 58 59 //导入导出 60 public: 61 void leading_in(); 62 void leading_out(); 63 }; 64 65 } 66 67 #endif
首先是对插入新词进行修改:
1 void Dictionary::AddWord(const string & word) 2 { 3 vector<string> characters; 4 splitWord(word, characters); 5 vector<int> kmpnext; 6 getKmpNext(characters, kmpnext); 7 8 vector<int>::iterator it_int; 9 it_int = kmpnext.begin(); 10 vector<string>::iterator it_char; 11 it_char = characters.begin(); 12 pDictElem root; 13 root = _dictionary; 14 for(; it_char != characters.end(); ++it_char, ++it_int) 15 { 16 WordIt it_word; 17 it_word = root->_words.find(*it_char); 18 19 if(it_word == root->_words.end()) 20 { 21 pair<string, pDictElem> temp; 22 temp.first = *it_char; 23 pDictElem dictemp(new DictElem); 24 dictemp->_word = *it_char; 25 dictemp->_next = *it_int; 26 dictemp->_isend = false; 27 temp.second = dictemp; 28 root->_words.insert(temp); 29 root = dictemp; 30 }else{ 31 root = it_word->second; 32 } 33 } 34 if(!root->_isend) 35 { 36 root->_isend = true; 37 } 38 }
这里的getKmpNext方法是新加入的,用来求next值:
1 void Dictionary::getKmpNext(const vector<string> & characters, vector<int> & kmpnext) 2 { 3 int size = characters.size(); 4 for(int i = 0; i < size; ++i) 5 { 6 kmpnext.push_back(0); 7 } 8 9 int i = -1; 10 int j = 0; 11 kmpnext[0] = -1; 12 while(j < size) 13 { 14 if(i == -1 || kmpnext[i] == kmpnext[j]) 15 { 16 ++i; 17 ++j; 18 kmpnext[j] = i; 19 }else{ 20 i = kmpnext[i]; 21 } 22 } 23 for(i = 0; i < size; ++i) 24 { 25 kmpnext[i] = i - kmpnext[i]; 26 } 27 }
第4~7行可以用vector 的resize方法,直接修改它的容量。
22行之前就是用来求KMP算法的next数组的,后几行是求弹栈数量的。
举个例子:
对于模式串“编程软件”,next数组为:-1 0 0 0,弹栈数量为1 1 2 3。如:
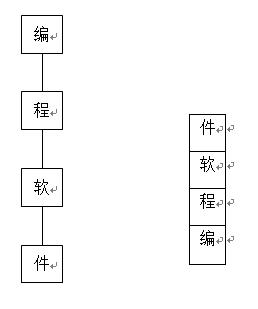 字典树 栈
字典树 栈
此时若匹配不成功,则要把“件”、“软”、“程”全弹出来。当“编”也不匹配时,弹出,重新在root中的unordered_map中查找。
进行匹配的代码如下:
1 bool Dictionary::Kmp(vector<string> & word, vector<Loc> & loc) 2 { 3 pDictElem root = _dictionary; 4 list<pDictElem> stackDict; 5 6 int start = 0; 7 int size = word.size(); 8 int i = 0; 9 while(i < size) 10 { 11 WordIt it_word; 12 it_word = root->_words.find(word[i]); 13 if(it_word == root->_words.end()) 14 { 15 if(stackDict.size()) 16 { 17 int num = root->_next; 18 for(int j = 0; j < num - 1; ++j) 19 { 20 stackDict.pop_back(); 21 } 22 root = stackDict.back(); 23 stackDict.pop_back(); 24 start += num; 25 }else{ 26 ++i; 27 start = i; 28 } 29 continue; 30 }else{ 31 stackDict.push_back(root); 32 root = it_word->second; 33 if(root->_isend) 34 { 35 Loc loctemp; 36 loctemp.first = start; 37 loctemp.second = i; 38 loc.push_back(loctemp); 39 start = i + 1; 40 } 41 } 42 ++i; 43 } 44 return loc.size(); 45 }
形参中,word是把主串拆成字后的集合,loc是要传出的参数,参数内容为所有的敏感词的起始位置与结束位置。外层还有一层封装:
1 string Dictionary::Kmp(const string & word) 2 { 3 vector<string> temp; 4 splitWord(word, temp); 5 vector<Loc> loc; 6 7 if(!Kmp(temp, loc)) 8 { 9 return word; 10 } 11 int size = loc.size(); 12 for(int i = 0; i < size; ++i) 13 { 14 for(int j = loc[i].first; j <= loc[i].second; ++j) 15 { 16 temp[j] = "*"; 17 } 18 } 19 string ret; 20 for(auto & elem : temp) 21 { 22 ret += elem; 23 } 24 return ret; 25 }
在这里,调用之前写的splitWord方法对主串进行分字操作,并且把敏感词替换成“*”,然后把结果传出。
这些写完差不多就可以用了。以下是测试内容:
敏感词设定为“好好玩耍”、“编程软件”、“编程学习”、“编程学习网站”、“编程训练”、“编程入门”六个词。
主串设定为“我不要好好玩耍好好进行编程学习然后建一个编程编程编程学习网站给编程纩编程软件者使用进行编程训练与编程学习”。
测试结果如下:
我不要好好玩耍好好进行编程学习然后建一个编程编程编程学习网站给编程纩编程软件者使用进行编程训练与编程学习
我不要****好好进行****然后建一个编程编程******给编程纩****者使用进行****与****
那么,如果机智的小伙伴在敏感词中间加了空格要怎么办呢?
我又想到两种方案:
方案一,在分字之后删除空格。
空格只占一个字节,但是在splitWord中也会被当成字存进vector,此时用erase+remore_if删除即可:
1 bool deleterule(string & word) 2 { 3 return word == " "; 4 } 5 6 string Dictionary::Kmp(const string & word) 7 { 8 vector<string> temp; 9 splitWord(word, temp); 10 11 temp.erase(std::remove_if(temp.begin(), temp.end(), deleterule)); 12 13 vector<Loc> loc; 14 15 if(!Kmp(temp, loc)) 16 { 17 return word; 18 } 19 int size = loc.size(); 20 for(int i = 0; i < size; ++i) 21 { 22 for(int j = loc[i].first; j <= loc[i].second; ++j) 23 { 24 temp[j] = "*"; 25 } 26 } 27 string ret; 28 for(auto & elem : temp) 29 { 30 ret += elem; 31 } 32 return ret; 33 }
测试如下:
我不要好好 玩耍好好进行编程学习然后建一个编程编程编程学 习网站给编程纩编程软件者使用进行编程训练与编程学习
我不要****好好进行****然后建一个编程编程******给编程纩****者使用进行****与****
方案二,在匹配的时候读到空格就跳过:
1 bool Dictionary::Kmp(vector<string> & word, vector<Loc> & loc) 2 { 3 pDictElem root = _dictionary; 4 list<pDictElem> stackDict; 5 6 int start = 0; 7 int size = word.size(); 8 int i = 0; 9 while(i < size) 10 { 11 if(word[i] == " ") 12 { 13 ++i; 14 if(!stackDict.size()) 15 { 16 ++start; 17 } 18 continue; 19 } 20 WordIt it_word; 21 it_word = root->_words.find(word[i]); 22 if(it_word == root->_words.end()) 23 { 24 if(stackDict.size()) 25 { 26 int num = root->_next; 27 for(int j = 0; j < num - 1; ++j) 28 { 29 stackDict.pop_back(); 30 } 31 root = stackDict.back(); 32 stackDict.pop_back(); 33 start += num; 34 }else{ 35 ++i; 36 start = i; 37 } 38 continue; 39 }else{ 40 stackDict.push_back(root); 41 root = it_word->second; 42 if(root->_isend) 43 { 44 Loc loctemp; 45 loctemp.first = start; 46 loctemp.second = i; 47 loc.push_back(loctemp); 48 start = i + 1; 49 } 50 } 51 ++i; 52 } 53 return loc.size(); 54 }
测试:
我不要好好 玩耍好好进行编程学习然后建一个编程编程编程学 习网站给编程纩编程软件者使用进行编程训练与编程学习
我不要*****好好进行****然后建一个编程编程**********给编程纩****者使用进行****与****
一开始的时候的BUG:
1、“编程编程编程学习”无法提取出“编程学习”
2、敏感词起始位置乱七八糟
3、弹栈时机乱七八糟
4、敏感词中同时存在“编程学习”与“编程学习网站”时会发生段错误
5、4解决了之后,会出现只匹配“编程学习”,而“网站”二字没有替换
1~4 BUG调整一下就可以了,至于5嘛,莫明其妙就可以了,我也不知道怎么回事。
Dictionary.cc
1 #include "Dictionary.h" 2 #include <json/json.h> 3 #include <iostream> 4 #include <fstream> 5 #include <string> 6 #include <algorithm> 7 8 #define PLAN1 9 10 namespace ccx{ 11 12 using std::endl; 13 using std::cout; 14 using std::pair; 15 using std::ofstream; 16 using std::ifstream; 17 18 Dictionary::Dictionary() 19 : _dictionary(new DictElem) 20 , _conf() 21 { 22 _dictionary->_isend = false; 23 _dictionary->_next = 0; 24 _pcur = _dictionary; 25 } 26 27 void Dictionary::splitWord(const string & word, vector<string> & characters) 28 { 29 int num = word.size(); 30 int i = 0; 31 while(i < num) 32 { 33 int size = 1; 34 if(word[i] & 0x80) 35 { 36 char temp = word[i]; 37 temp <<= 1; 38 do{ 39 temp <<= 1; 40 ++size; 41 }while(temp & 0x80); 42 } 43 string subWord; 44 subWord = word.substr(i, size); 45 characters.push_back(subWord); 46 i += size; 47 } 48 } 49 50 void Dictionary::getKmpNext(const vector<string> & characters, vector<int> & kmpnext) 51 { 52 int size = characters.size(); 53 for(int i = 0; i < size; ++i) 54 { 55 kmpnext.push_back(0); 56 } 57 58 int i = -1; 59 int j = 0; 60 kmpnext[0] = -1; 61 while(j < size) 62 { 63 if(i == -1 || kmpnext[i] == kmpnext[j]) 64 { 65 ++i; 66 ++j; 67 kmpnext[j] = i; 68 }else{ 69 i = kmpnext[i]; 70 } 71 } 72 for(i = 0; i < size; ++i) 73 { 74 kmpnext[i] = i - kmpnext[i]; 75 } 76 } 77 78