cassandra在pom.xml里面怎么设置library
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了cassandra在pom.xml里面怎么设置library相关的知识,希望对你有一定的参考价值。
参考技术A 1.执行代码//CassandraTest.scalaimportorg.apache.spark.Logging,SparkContext,SparkConfimportcom.datastax.spark.connector.cql.CassandraConnectorobjectCassandraTestAppdefmain(args:Array[String])#配置spark,cassandra的ip,这里都是本机valSparkMasterHost="127.0.0.1"valCassandraHost="127.0.0.1"//TellSparktheaddressofoneCassandranode:valconf=newSparkConf(true).set("spark.cassandra.connection.host",CassandraHost).set("spark.cleaner.ttl","3600").setMaster("local[12]").setAppName("CassandraTestApp")//ConnecttotheSparkcluster:lazyvalsc=newSparkContext(conf)//预处理脚本,连接的时候就执行这些CassandraConnector(conf).withSessionDosession=>session.execute("CREATEKEYSPACEIFNOTEXISTStestWITHREPLICATION='class':'SimpleStrategy','replication_factor':1")session.execute("CREATETABLEIFNOTEXISTStest.key_value(keyINTPRIMARYKEY,valueVARCHAR)")session.execute("TRUNCATEtest.key_value")session.execute("INSERTINTOtest.key_value(key,value)VALUES(1,'firstrow')")session.execute("INSERTINTOtest.key_value(key,value)VALUES(2,'secondrow')")session.execute("INSERTINTOtest.key_value(key,value)VALUES(3,'thirdrow')")//加载connectorimportcom.datastax.spark.connector._//Readtabletest.kvandprintitscontents:valrdd=sc.cassandraTable("test","key_value").select("key","value")rdd.collect().foreach(row=>println(s"ExistingData:$row"))//Writetwonewrowstothetest.kvtable:valcol=sc.parallelize(Seq((4,"fourthrow"),(5,"fifthrow")))col.saveToCassandra("test","key_value",SomeColumns("key","value"))//Assertthetwonewrowswerestoredintest.kvtable:assert(col.collect().length==2)col.collect().foreach(row=>println(s"NewData:$row"))println(s"Workcompleted,stoppingtheSparkcontext.")sc.stop()2.目录结构由于构建工具是用sbt,所以目录结构也必须遵循sbt规范,主要是build.sbt和src目录,其它目录会自动生成。qpzhang@qpzhangdeMac-mini:~/scala_code/CassandraTest$lltotal8drwxr-xr-x6qpzhangstaff204112612:14./drwxr-xr-x10qpzhangstaff340112517:30../-rw-r--r--1qpzhangstaff460112610:11build.sbtdrwxr-xr-x3qpzhangstaff102112517:42project/drwxr-xr-x3qpzhangstaff102112517:32src/drwxr-xr-x6qpzhangstaff204112517:55target/qpzhang@qpzhangdeMac-mini:~/scala_code/CassandraTest$treesrc/src/└──main└──scala└──CassandraTest.scalaqpzhang@qpzhangdeMac-mini:~/scala_code/CassandraTest$catbuild.sbtname:="CassandraTest"version:="1.0"scalaVersion:="2.10.4"libraryDependencies+="org.apache.spark"%%"spark-core"%"1.5.2"%"provided"libraryDependencies+="com.datastax.spark"%%"spark-cassandra-connector"%"1.5.0-M2"assemblyMergeStrategyinassembly:=casePathList(ps@_*)ifps.lastendsWith".properties"=>MergeStrategy.firstcasex=>valoldStrategy=(assemblyMergeStrategyinassembly).valueoldStrategy(x)这里需要注意的是,sbt安装的是当时最新版本0.13,并且安装了assembly插件(这里要吐槽一下sbt,下载一坨坨的jar包,最好有FQ代理,否则下载等待时间很长)。qpzhang@qpzhangdeMac-mini:~/scala_code/CassandraTest$cat~/.sbt/0.13/plugins/plugins.sbtaddSbtPlugin("com.typesafe.sbteclipse"%"sbteclipse-plugin"%"2.5.0")addSbtPlugin("com.eed3si9n"%"sbt-assembly"%"0.14.1")3.sbt编译打包在build.sbt目录下,使用sbt命令启动。然后使用compile命令进行编译,使用assembly进行打包。在次期间,遇到了sbt-assembly-deduplicate-error的问题,参考这里。>compile[success]Totaltime:0s,completed2015-11-2610:11:50>>assembly[info]Includingfromcache:slf4j-api-1.7.5.jar[info]Includingfromcache:metrics-core-3.0.2.jar[info]Includingfromcache:netty-codec-4.0.27.Final.jar[info]Includingfromcache:netty-handler-4.0.27.Final.jar[info]Includingfromcache:netty-common-4.0.27.Final.jar[info]Includingfromcache:joda-time-2.3.jar[info]Includingfromcache:netty-buffer-4.0.27.Final.jar[info]Includingfromcache:commons-lang3-3.3.2.jar[info]Includingfromcache:jsr166e-1.1.0.jar[info]Includingfromcache:cassandra-clientutil-2.1.5.jar[info]Includingfromcache:joda-convert-1.2.jar[info]Includingfromcache:netty-transport-4.0.27.Final.jar[info]Includingfromcache:guava-16.0.1.jar[info]Includingfromcache:spark-cassandra-connector_2.10-1.5.0-M2.jar[info]Includingfromcache:cassandra-driver-core-2.2.0-rc3.jar[info]Includingfromcache:scala-reflect-2.10.5.jar[info]Includingfromcache:scala-library-2.10.5.jar[info]Checkingevery*.class/*.jarfile'sSHA-1.[info]Mergingfiles[warn]Merging'META-INF/INDEX.LIST'withstrategy'discard'[warn]Merging'META-INF/MANIFEST.MF'withstrategy'discard'[warn]Merging'META-INF/io.netty.versions.properties'withstrategy'first'[warn]Merging'META-INF/maven/com.codahale.metrics/metrics-core/pom.xml'withstrategy'discard'[warn]Merging'META-INF/maven/com.datastax.cassandra/cassandra-driver-core/pom.xml'withstrategy'discard'[warn]Merging'META-INF/maven/com.google.guava/guava/pom.xml'withstrategy'discard'[warn]Merging'META-INF/maven/com.twitter/jsr166e/pom.xml'withstrategy'discard'[warn]Merging'META-INF/maven/io.netty/netty-buffer/pom.xml'withstrategy'discard'[warn]Merging'META-INF/maven/io.netty/netty-codec/pom.xml'withstrategy'discard'[warn]Merging'META-INF/maven/io.netty/netty-common/pom.xml'withstrategy'discard'[warn]Merging'META-INF/maven/io.netty/netty-handler/pom.xml'withstrategy'discard'[warn]Merging'META-INF/maven/io.netty/netty-transport/pom.xml'withstrategy'discard'[warn]Merging'META-INF/maven/joda-time/joda-time/pom.xml'withstrategy'discard'[warn]Merging'META-INF/maven/org.apache.commons/commons-lang3/pom.xml'withstrategy'discard'[warn]Merging'META-INF/maven/org.joda/joda-convert/pom.xml'withstrategy'discard'[warn]Merging'META-INF/maven/org.slf4j/slf4j-api/pom.xml'withstrategy'discard'[warn]Strategy'discard'wasappliedto15files[warn]Strategy'first'wasappliedtoafile[info]SHA-1:d2cb403e090e6a3ae36b08c860b258c79120fc90[info]Packaging/Users/qpzhang/scala_code/CassandraTest/target/scala-2.10/CassandraTest-assembly-1.0.jar[info]Donepackaging.[success]Totaltime:19s,completed2015-11-2610:12:224.提交到spark,执行结果qpzhang@qpzhangdeMac-mini:~/project/spark-1.5.2-bin-hadoop2.6$./bin/spark-submit--class"CassandraTestApp"--masterlocal[4]~/scala_code/CassandraTest/target/scala-2.10/CassandraTest-assembly-1.0.jar//5/11/2611:40:23INFOTaskSetManager:Startingtask0.0instage0.0(TID0,localhost,NODE_LOCAL,26660bytes)15/11/2611:40:23INFOExecutor:Runningtask0.0instage0.0(TID0)15/11/2611:40:23INFOExecutor:Fetchinghttp://10.60.215.42:57683/jars/CassandraTest-assembly-1.0.jarwithtimestamp144850922116015/11/2611:40:23INFOCassandraConnector:DisconnectedfromCassandracluster:TestCluster15/11/2611:40:23INFOUtils:Fetchinghttp://10.60.215.42:57683/jars/CassandraTest-assembly-1.0.jarto/private/var/folders/2l/195zcc1n0sn2wjfjwf9hl9d80000gn/T/spark-4030cadf-8489-4540-976e-e98eedf50412/userFiles-63085bda-aa04-4906-9621-c1cedd98c163/fetchFileTemp7487594894647111926.tmp15/11/2611:40:23INFOExecutor:Addingfile:/private/var/folders/2l/195zcc1n0sn2wjfjwf9hl9d80000gn/T/spark-4030cadf-8489-4540-976e-e98eedf50412/userFiles-63085bda-aa04-4906-9621-c1cedd98c163/CassandraTest-assembly-1.0.jartoclassloader15/11/2611:40:24INFOCluster:NewCassandrahostlocalhost/127.0.0.1:9042added15/11/2611:40:24INFOCassandraConnector:ConnectedtoCassandracluster:TestCluster15/11/2611:40:25INFOExecutor:Finishedtask0.0instage0.0(TID0).2676bytesresultsenttodriver15/11/2611:40:25INFOTaskSetManager:Finishedtask0.0instage0.0(TID0)in2462msonlocalhost(1/1)15/11/2611:40:25INFOTaskSchedulerImpl:RemovedTaskSet0.0,whosetaskshaveallcompleted,frompool15/11/2611:40:25INFODAGScheduler:ResultStage0(collectatCassandraTest.scala:32)finishedin2.481s15/11/2611:40:25INFODAGScheduler:Job0finished:collectatCassandraTest.scala:32,took2.940601sExistingData:CassandraRowkey:1,value:firstrowExistingData:CassandraRowkey:2,value:secondrowExistingData:CassandraRowkey:3,value:thirdrow//..5/11/2611:40:27INFOTaskSchedulerImpl:RemovedTaskSet3.0,whosetaskshaveallcompleted,frompool15/11/2611:40:27INFODAGScheduler:ResultStage3(collectatCassandraTest.scala:41)finishedin0.032s15/11/2611:40:27INFODAGScheduler:Job3finished:collectatCassandraTest.scala:41,took0.046502sNewData:(4,fourthrow)NewData:(5,fifthrow)Workcompleted,stoppingtheSparkcontext.cassandra中的数据cqlsh:test>select*fromkey_value;key|value-----+------------5|fifthrow1|firstrow2|secondrow4|fourthrow3|thirdrow(5rows)到此位置,还算顺利,除了assembly重复文件的问题,都还算ok。 参考技术B 1.执行代码//CassandraTest.scalaimportorg.apache.spark.Logging,SparkContext,SparkConfimportcom.datastax.spark.connector.cql.CassandraConnectorobjectCassandraTestAppdefmain(args:Array[String])#配置spark,cassandra的ip,这里都是本机valSparkMasterHost="127.0.0.1"valCassandraHost="127.0.0.1"//TellSparktheaddressofoneCassandranode:valconf=newSparkConf(true).set("spark.cassandra.connection.host",CassandraHost).set("spark.cleaner.ttl","3600").setMaster("local[12]").setAppName("CassandraTestApp")//ConnecttotheSparkcluster:lazyvalsc=newSparkContext(conf)//预处理脚本,连接的时候就执行这些CassandraConnector(conf).withSessionDosession=>session.execute("CREATEKEYSPACEIFNOTEXISTStestWITHREPLICATION='class':'SimpleStrategy','replication_factor':1")session.execute("CREATETABLEIFNOTEXISTStest.key_value(keyINTPRIMARYKEY,valueVARCHAR)")session.execute("TRUNCATEtest.key_value")session.execute("INSERTINTOtest.key_value(key,value)VALUES(1,'firstrow')")session.execute("INSERTINTOtest.key_value(key,value)VALUES(2,'secondrow')")session.execute("INSERTINTOtest.key_value(key,value)VALUES(3,'thirdrow')")//加载connectorimportcom.datastax.spark.connector._//Readtabletest.kvandprintitscontents:valrdd=sc.cassandraTable("test","key_value").select("key","value")rdd.collect().foreach(row=>println(s"ExistingData:$row"))//Writetwonewrowstothetest.kvtable:valcol=sc.parallelize(Seq((4,"fourthrow"),(5,"fifthrow")))col.saveToCassandra("test","key_value",SomeColumns("key","value"))//Assertthetwonewrowswerestoredintest.kvtable:assert(col.collect().length==2)col.collect().foreach(row=>println(s"NewData:$row"))println(s"Workcompleted,stoppingtheSparkcontext.")sc.stop()2.目录结构由于构建工具是用sbt,所以目录结构也必须遵循sbt规范,主要是build.sbt和src目录,其它目录会自动生成。qpzhang@qpzhangdeMac-mini:~/scala_code/CassandraTest$lltotal8drwxr-xr-x6qpzhangstaff204112612:14./drwxr-xr-x10qpzhangstaff340112517:30../-rw-r--r--1qpzhangstaff460112610:11build.sbtdrwxr-xr-x3qpzhangstaff102112517:42project/drwxr-xr-x3qpzhangstaff102112517:32src/drwxr-xr-x6qpzhangstaff204112517:55target/qpzhang@qpzhangdeMac-mini:~/scala_code/CassandraTest$treesrc/src/└──main└──scala└──CassandraTest.scalaqpzhang@qpzhangdeMac-mini:~/scala_code/CassandraTest$catbuild.sbtname:="CassandraTest"version:="1.0"scalaVersion:="2.10.4"libraryDependencies+="org.apache.spark"%%"spark-core"%"1.5.2"%"provided"libraryDependencies+="com.datastax.spark"%%"spark-cassandra-connector"%"1.5.0-M2"assemblyMergeStrategyinassembly:=casePathList(ps@_*)ifps.lastendsWith".properties"=>MergeStrategy.firstcasex=>valoldStrategy=(assemblyMergeStrategyinassembly).valueoldStrategy(x)这里需要注意的是,sbt安装的是当时最新版本0.13,并且安装了assembly插件(这里要吐槽一下sbt,下载一坨坨的jar包,最好有FQ代理,否则下载等待时间很长)。qpzhang@qpzhangdeMac-mini:~/scala_code/CassandraTest$cat~/.sbt/0.13/plugins/plugins.sbtaddSbtPlugin("com.typesafe.sbteclipse"%"sbteclipse-plugin"%"2.5.0")addSbtPlugin("com.eed3si9n"%"sbt-assembly"%"0.14.1")3.sbt编译打包在build.sbt目录下,使用sbt命令启动。然后使用compile命令进行编译,使用assembly进行打包。在次期间,遇到了sbt-assembly-deduplicate-error的问题,参考这里。>compile[success]Totaltime:0s,completed2015-11-2610:11:50>>assembly[info]Includingfromcache:slf4j-api-1.7.5.jar[info]Includingfromcache:metrics-core-3.0.2.jar[info]Includingfromcache:netty-codec-4.0.27.Final.jar[info]Includingfromcache:netty-handler-4.0.27.Final.jar[info]Includingfromcache:netty-common-4.0.27.Final.jar[info]Includingfromcache:joda-time-2.3.jar[info]Includingfromcache:netty-buffer-4.0.27.Final.jar[info]Includingfromcache:commons-lang3-3.3.2.jar[info]Includingfromcache:jsr166e-1.1.0.jar[info]Includingfromcache:cassandra-clientutil-2.1.5.jar[info]Includingfromcache:joda-convert-1.2.jar[info]Includingfromcache:netty-transport-4.0.27.Final.jar[info]Includingfromcache:guava-16.0.1.jar[info]Includingfromcache:spark-cassandra-connector_2.10-1.5.0-M2.jar[info]Includingfromcache:cassandra-driver-core-2.2.0-rc3.jar[info]Includingfromcache:scala-reflect-2.10.5.jar[info]Includingfromcache:scala-library-2.10.5.jar[info]Checkingevery*.class/*.jarfile'sSHA-1.[info]Mergingfiles[warn]Merging'META-INF/INDEX.LIST'withstrategy'discard'[warn]Merging'META-INF/MANIFEST.MF'withstrategy'discard'[warn]Merging'META-INF/io.netty.versions.properties'withstrategy'first'[warn]Merging'META-INF/maven/com.codahale.metrics/metrics-core/pom.xml'withstrategy'discard'[warn]Merging'META-INF/maven/com.datastax.cassandra/cassandra-driver-core/pom.xml'withstrategy'discard'[warn]Merging'META-INF/maven/com.google.guava/guava/pom.xml'withstrategy'discard'[warn]Merging'META-INF/maven/com.twitter/jsr166e/pom.xml'withstrategy'discard'[warn]Merging'META-INF/maven/io.netty/netty-buffer/pom.xml'withstrategy'discard'[warn]Merging'META-INF/maven/io.netty/netty-codec/pom.xml'withstrategy'discard'[warn]Merging'META-INF/maven/io.netty/netty-common/pom.xml'withstrategy'discard'[warn]Merging'META-INF/maven/io.netty/netty-handler/pom.xml'withstrategy'discard'[warn]Merging'META-INF/maven/io.netty/netty-transport/pom.xml'withstrategy'discard'[warn]Merging'META-INF/maven/joda-time/joda-time/pom.xml'withstrategy'discard'[warn]Merging'META-INF/maven/org.apache.commons/commons-lang3/pom.xml'withstrategy'discard'[warn]Merging'META-INF/maven/org.joda/joda-convert/pom.xml'withstrategy'discard'[warn]Merging'META-INF/maven/org.slf4j/slf4j-api/pom.xml'withstrategy'discard'[warn]Strategy'discard'wasappliedto15files[warn]Strategy'first'wasappliedtoafile[info]SHA-1:d2cb403e090e6a3ae36b08c860b258c79120fc90[info]Packaging/Users/qpzhang/scala_code/CassandraTest/target/scala-2.10/CassandraTest-assembly-1.0.jar[info]Donepackaging.[success]Totaltime:19s,completed2015-11-2610:12:224.提交到spark,执行结果qpzhang@qpzhangdeMac-mini:~/project/spark-1.5.2-bin-hadoop2.6$./bin/spark-submit--class"CassandraTestApp"--masterlocal[4]~/scala_code/CassandraTest/target/scala-2.10/CassandraTest-assembly-1.0.jar//5/11/2611:40:23INFOTaskSetManager:Startingtask0.0instage0.0(TID0,localhost,NODE_LOCAL,26660bytes)15/11/2611:40:23INFOExecutor:Runningtask0.0instage0.0(TID0)15/11/2611:40:23INFOExecutor:Fetchinghttp://10.60.215.42:57683/jars/CassandraTest-assembly-1.0.jarwithtimestamp144850922116015/11/2611:40:23INFOCassandraConnector:DisconnectedfromCassandracluster:TestCluster15/11/2611:40:23INFOUtils:Fetchinghttp://10.60.215.42:57683/jars/CassandraTest-assembly-1.0.jarto/private/var/folders/2l/195zcc1n0sn2wjfjwf9hl9d80000gn/T/spark-4030cadf-8489-4540-976e-e98eedf50412/userFiles-63085bda-aa04-4906-9621-c1cedd98c163/fetchFileTemp7487594894647111926.tmp15/11/2611:40:23INFOExecutor:Addingfile:/private/var/folders/2l/195zcc1n0sn2wjfjwf9hl9d80000gn/T/spark-4030cadf-8489-4540-976e-e98eedf50412/userFiles-63085bda-aa04-4906-9621-c1cedd98c163/CassandraTest-assembly-1.0.jartoclassloader15/11/2611:40:24INFOCluster:NewCassandrahostlocalhost/127.0.0.1:9042added15/11/2611:40:24INFOCassandraConnector:ConnectedtoCassandracluster:TestCluster15/11/2611:40:25INFOExecutor:Finishedtask0.0instage0.0(TID0).2676bytesresultsenttodriver15/11/2611:40:25INFOTaskSetManager:Finishedtask0.0instage0.0(TID0)in2462msonlocalhost(1/1)15/11/2611:40:25INFOTaskSchedulerImpl:RemovedTaskSet0.0,whosetaskshaveallcompleted,frompool15/11/2611:40:25INFODAGScheduler:ResultStage0(collectatCassandraTest.scala:32)finishedin2.481s15/11/2611:40:25INFODAGScheduler:Job0finished:collectatCassandraTest.scala:32,took2.940601sExistingData:CassandraRowkey:1,value:firstrowExistingData:CassandraRowkey:2,value:secondrowExistingData:CassandraRowkey:3,value:thirdrow//..5/11/2611:40:27INFOTaskSchedulerImpl:RemovedTaskSet3.0,whosetaskshaveallcompleted,frompool15/11/2611:40:27INFODAGScheduler:ResultStage3(collectatCassandraTest.scala:41)finishedin0.032s15/11/2611:40:27INFODAGScheduler:Job3finished:collectatCassandraTest.scala:41,took0.046502sNewData:(4,fourthrow)NewData:(5,fifthrow)Workcompleted,stoppingtheSparkcontext.cassandra中的数据cqlsh:test>select*fromkey_value;key|value-----+------------5|fifthrow1|firstrow2|secondrow4|fourthrow3|thirdrow(5rows)到此位置,还算顺利,除了assembly重复文件的问题,都还算ok。 参考技术C 1、基本配置首先需要准备3台或以上的计算机。下面假定有3台运行Linux操作系统的计算机,IP地址分别为192.168.0.100,192.168.0.101和192.168.0.102。系统需要安装好Java运行时环境,然后到这里下载0.7版本的Cassandra二进制发行包。挑选其中的一台机开始配置,先cassandra发行包:$tar-zxvfapache-cassandra-$VERSION.tar.gz$cdapache-cassandra-$VERSION其中的conf/cassandra.yaml文件为主要配置文件,0.7版以后不再采用XML格式配置文件了,如果对YAML格式不熟悉的话最好先到这里了解一下。Cassandra在配置文件里默认设定了几个目录:data_file_directories:/var/lib/cassandra/datacommitlog_directory:/var/lib/cassandra/commitlogsaved_caches_directory:/var/lib/cassandra/saved_cachesdata_file_directories可以一次同时设置几个不同目录,cassandra会自动同步所有目录的数据。另外在日志配置文件log4j-server.properties也有一个默认设定日志文件的目录:log4j.appender.R.File=/var/log/cassandra/system.log一般情况下采用默认的配置即可,除非你有特殊的储存要求,所以现在有两种方案:一是按照默认配置创建相关的目录,二是修改配置文件采用自己指定的目录。下面为了简单起见采用第一种方案:$sudomkdir-p/var/log/cassandra$sudochown-R`whoami`/var/log/cassandra$sudomkdir-p/var/lib/cassandra$sudochown-R`whoami`/var/lib/cassandra上面的`whoami`是Linux指令用于获取当前登录的用户名,如果你不准备用当前登录用户运行Cassandra,那么需要把`whoami`替换成具体的用户名。2、有关集群的配置由于Cassandra采用去中心化结构,所以当集群里的一台机器(节点)启动之后需要一个途径通知当前集群(有新节点加入啦),Cassandra的配置文件里有一个seeds的设置项,所谓的seeds就是能够联系集群中所有节点的一台计算机,假如集群中所有的节点位于同一个机房同一个子网,那么只要随意挑选几台比较稳定的计算机即可。在当前的例子中因为只有3台机器,所以我挑选第一台作为种子节点,配置如下:seeds:-192.168.0.100然后配置节点之前通信的IP地址:listen_address:192.168.0.100需要注意的是这里必须使用具体的IP地址,而不能使用0.0.0.0这样的地址。配置CassandraThrift客户端(应用程序)访问的IP地址:rpc_address:192.168.0.100这项可以使用0.0.0.0监听一台机器所有的网络接口。Cassandra的Keyspaces和ColumnFamilies不再需要配置了,他们将在运行时创建和维护。把配置好的Cassandra复制到第2和第3台机器,同时创建相关的目录,还需要修改listen_address和rpc_address为实际机器的IP地址。至此所有的配置完成了。3、启动Cassandra各个节点以及集群管理启动顺序没什么所谓,只要保证种子节点启动就可以了:$bin/cassandra-f参数-f的作用是让Cassandra以前端程序方式运行,这样有利于调试和观察日志信息,而在实际生产环境中这个参数是不需要的(即Cassandra会以daemon方式运行)。所有节点启动后可以通过bin/nodetool工具管理集群,比如查看所有节点运行情况:$bin/nodetool-host192.168.0.101ring运行结果类似如下:AddressStatusStateLoadOwnsToken159559192.168.0.100UpNormal49.27KB39.32%563215192.168.0.101UpNormal54.42KB16.81%849292192.168.0.102UpNormal73.14KB43.86%159559命令中-host参数用于指定nodetool跟哪一个节点通信,对于nodetoolring命令来说,跟哪个节点通信都没有区别,所以可以随意指定其中一个节点。从上面结果列表可以看到运行中的节点是否在线、State、数据负载量以及节点Token(可以理解为节点名称,这个是节点第一次启动时自动产生的)。我们可以使用nodetool组合token对具体节点进行管理,比如查看指定节点的详细信息:$bin/nodetool-host192.168.0.101info运行的结果大致如下:84929280487220726989221251643883950871Load:54.42KBGenerationNo:1302057702Uptime(seconds):591HeapMemory(MB):212.14/1877.63查看指定节点的数据结构信息:$bin/nodetool-host192.168.0.101cfstats运行结果:Keyspace:Keyspace1ReadCount:0WriteCount:0PendingTasks:0ColumnFamily:CF1SSTablecount:1使用下面命令可以移除一个已经下线的节点(比如第2台机器关机了或者坏掉了)$bin/nodetool-host192.168.0.101removetoken84929280487220726989221251643883950871下了线的节点如何重新上线呢?什么都不用做,只需启动Cassandra程序它就会自动加入集群了。在实际运作中我们可能会需要隔一段时间备份一次数据(创建一个快照),这个操作在Cassandra里非常简单:$bin/nodetool-host192.168.0.101snapshot4、测试数据的读写使用客户端组件加单元测试是首选的,如果仅想知道集群是否正常读写数据,可以用cassandra-cli作一个简单测试:$bin/cassandra-cli-host192.168.0.101接着输入如下语句:createkeyspaceKeyspace1;useKeyspace1;createcolumnfamilyUserswithcomparator=UTF8Typeanddefault_validation_class=UTF8Type;setUsers[jsmith][first]='John';setUsers[jsmith][last]='Smith';getUsers[jsmith];上面语句创建了一个名为“Keyspace1”的keyspace,还创建了一个名为“Users”的ColumnFamily,最后向Users添加了一个item。正常的话应该看到类似下面的结果:=>(column=first,value=John,timestamp=1302059332540000)=>(column=last,value=Smith,timestamp=1300874233834000)Returned2results.怎么直接在html修改li里面的超链接的字体颜色
是不通过css直接在html修改的。比如
<li><a href="#">xxxx</a></li>
怎么直接修改xxxx的字体颜色
需要准备的材料分别有:电脑、浏览器、html编辑器。
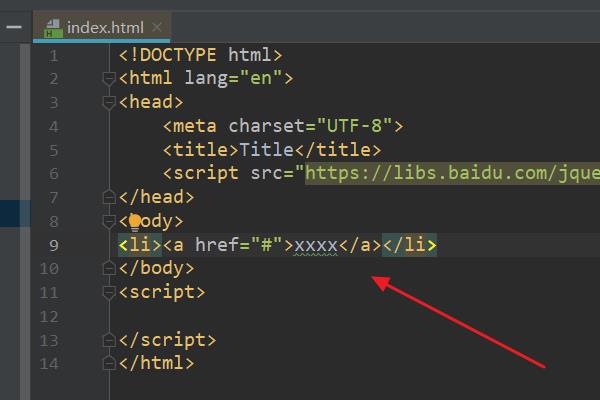
1、首先,打开html编辑器,新建html文件,例如:index.html,编写问题基础代码。
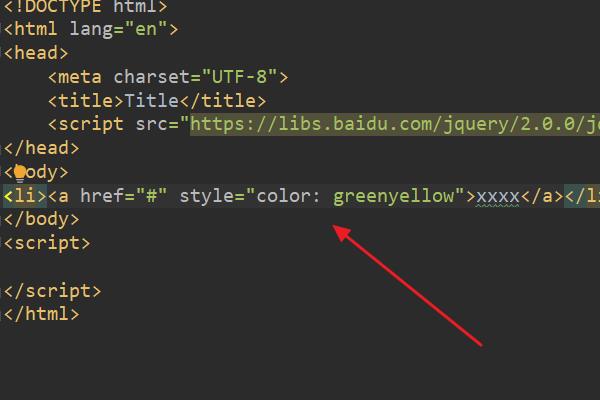
2、在index.html中的<a>标签中,输入样式代码:style="color: greenyellow"。
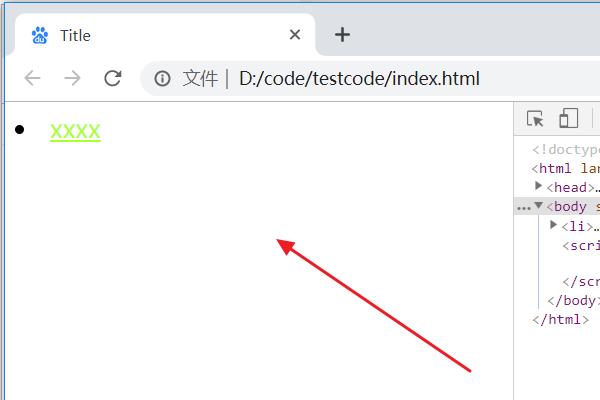
3、浏览器运行index.html页面,此时li里面超链接的字体颜色被成功修改。
可以直接使用HTML中的font标签或者使用CSS样式:
1、使用font标签实现:
<a href="http://www.baidu.com"><font color="red">百度</font></a>2、使用CSS样式表改变其颜色
两者均可实现效果。
<ul>
<li><a href="#"><span style="color:red;">红色</span></a></li>
</ul> 参考技术C 可以在改写body标签 <body link="#66FF00"> 参考技术D 设置a的CSS样式。
以上是关于cassandra在pom.xml里面怎么设置library的主要内容,如果未能解决你的问题,请参考以下文章