Kafka日志清除策略
Posted 异想天开
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka日志清除策略相关的知识,希望对你有一定的参考价值。
一、更改日志输出级别
config/log4j.properties中日志的级别设置的是TRACE,在长时间运行过程中产生的日志大小吓人,所以如果没有特殊需求,强烈建议将其更改成INFO级别。具体修改方法如下所示,将config/log4j.properties文件中最后的几行中的TRACE改成INFO,修改前如下所示:
log4j.logger.kafka.network.RequestChannel$=TRACE, requestAppender log4j.additivity.kafka.network.RequestChannel$=false #log4j.logger.kafka.network.Processor=TRACE, requestAppender #log4j.logger.kafka.server.KafkaApis=TRACE, requestAppender #log4j.additivity.kafka.server.KafkaApis=false log4j.logger.kafka.request.logger=TRACE, requestAppender log4j.additivity.kafka.request.logger=false log4j.logger.kafka.controller=TRACE, controllerAppender log4j.additivity.kafka.controller=false log4j.logger.state.change.logger=TRACE, stateChangeAppender log4j.additivity.state.change.logger=false
修改后如下所示:
log4j.logger.kafka.network.RequestChannel$=INFO, requestAppender log4j.additivity.kafka.network.RequestChannel$=false #log4j.logger.kafka.network.Processor=INFO, requestAppender #log4j.logger.kafka.server.KafkaApis=INFO, requestAppender #log4j.additivity.kafka.server.KafkaApis=false log4j.logger.kafka.request.logger=INFO, requestAppender log4j.additivity.kafka.request.logger=false log4j.logger.kafka.controller=INFO, controllerAppender log4j.additivity.kafka.controller=false log4j.logger.state.change.logger=INFO, stateChangeAppender log4j.additivity.state.change.logger=false
二、利用Kafka日志管理器
Kafka日志管理器允许定制删除策略。目前的策略是删除修改时间在N天之前的日志(按时间删除),也可以使用另外一个策略:保留最后的N GB数据的策略(按大小删除)。为了避免在删除时阻塞读操作,采用了copy-on-write形式的实现,删除操作进行时,读取操作的二分查找功能实际是在一个静态的快照副本上进行的,这类似于Java的CopyOnWriteArrayList。
Kafka消费日志删除思想:Kafka把topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用
log.cleanup.policy=delete启用删除策略 直接删除,删除后的消息不可恢复。可配置以下两个策略: 清理超过指定时间清理: log.retention.hours=16 超过指定大小后,删除旧的消息: log.retention.bytes=1073741824
三、压缩策略
将数据压缩,只保留每个key最后一个版本的数据。首先在broker的配置中设置log.cleaner.enable=true启用cleaner,这个默认是关闭的。在Topic的配置中设置log.cleanup.policy=compact启用压缩策略。
压缩策略的细节如下:
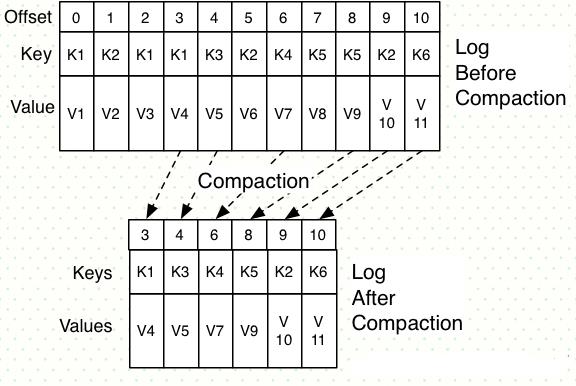
如上图,在整个数据流中,每个Key都有可能出现多次,压缩时将根据Key将消息聚合,只保留最后一次出现时的数据。这样,无论什么时候消费消息,都能拿到每个Key的最新版本的数据。
压缩后的offset可能是不连续的,比如上图中没有5和7,因为这些offset的消息被merge了,当从这些offset消费消息时,将会拿到比这个offset大的offset对应的消息,比如,当试图获取offset为5的消息时,实际上会拿到offset为6的消息,并从这个位置开始消费。
这种策略只适合特俗场景,比如消息的key是用户ID,消息体是用户的资料,通过这种压缩策略,整个消息集里就保存了所有用户最新的资料。
压缩策略支持删除,当某个Key的最新版本的消息没有内容时,这个Key将被删除,这也符合以上逻辑。
以上是关于Kafka日志清除策略的主要内容,如果未能解决你的问题,请参考以下文章