storm的acker机制理解。
Posted sanmutongzi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了storm的acker机制理解。相关的知识,希望对你有一定的参考价值。
转载请注明原创地址http://www.cnblogs.com/dongxiao-yang/p/6142356.html
Storm 的拓扑有一些特殊的称为“acker”的任务,这些任务负责跟踪每个 Spout 发出的 tuple 的 DAG。开启storm tracker机制的前提有三个:
1. 在spout emit tuple的时候,要加上第3个参数messageid
2. 在配置中acker数目至少为1
3. 在bolt emit的时候,要加上第二个参数anchor tuple,以保持tracker链路。
当一个 tuple 在拓扑中被创建出来的时候, 不管是在 Spout 中还是在 Bolt 中创建的 , 这个 tuple 都会被配置一个随机的 64 位 id。acker 就是使用这些 id 来跟踪每个 spout tuple 的 tuple DAG。这里贴一下storm源码分析里一个ack机制的例子。
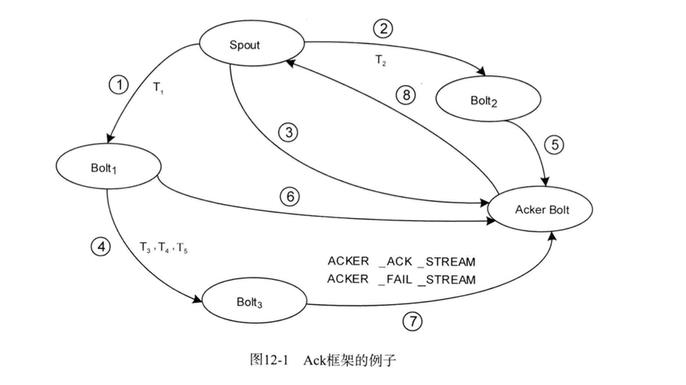
理解下整个大体节奏分为几部分
步骤1和2 spout把一条信息同时发送给了bolt1和bolt2,步骤3表示spout emit成功后去 acker bolt里注册本次根消息,ack值设定为本次发送的消息对应的64位id的异或运算值,上图对应的是T1^T2。
步骤4表示bolt1收到T1后,单条tuple被拆成了三条消息T3T4T5发送给bolt3。步骤6 bolt1在ack()方法调用时会向acker bolt提交T1^T3^T4^T5的ack值。
步骤5和7的bolt都没有产生新消息,所以ack()的时候分别向acker bolt提交了T2 和T3^T4^T5的ack值。
综上所述,本次spout产生的tuple树对应的ack值经过的运算为 T1^T2^T1^T3^T4^T5^T2^T3^T4^T5按照异或运算的规则,ack值最终正好归零。
步骤8为acker bolt发现根spout最终对应的的ack是0以后认为所有衍生出来的数据都已经处理成功,它会通知对应的spout,spout会调用相应的ack方法。
storm这个机制的实现方式保证了无论一个tuple树有多少个节点,一个根消息对应的追踪ack值所占用的空间大小是固定的,极大地节约了内存空间。
参考文档
3 《strom源码分析》 第12章
以上是关于storm的acker机制理解。的主要内容,如果未能解决你的问题,请参考以下文章