Hive Streaming 追加 ORC 文件
Posted 哥不是小萝莉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive Streaming 追加 ORC 文件相关的知识,希望对你有一定的参考价值。
1.概述
在存储业务数据的时候,随着业务的增长,Hive 表存储在 HDFS 的上的数据会随时间的增加而增加,而以 Text 文本格式存储在 HDFS 上,所消耗的容量资源巨大。那么,我们需要有一种方式来减少容量的成本。而在 Hive 中,有一种 ORC 文件格式可以极大的减少存储的容量成本。今天,笔者就为大家分享如何实现流式数据追加到 Hive ORC 表中。
2.内容
2.1 ORC
这里,我们首先需要知道 Hive 的 ORC 是什么。在此之前,Hive 中存在一种 RC 文件,而 ORC 的出现,对 RC 这种文件做了许多优化,这种文件格式可以提供一种高效的方式来存储 Hive 数据,使用 ORC 文件可以提供 Hive 的读写以及性能。其优点如下:
- 减少 NameNode 的负载
- 支持复杂数据类型(如 list,map,struct 等等)
- 文件中包含索引
- 块压缩
- ...
结构图(来源于 Apache ORC 官网)如下所示:
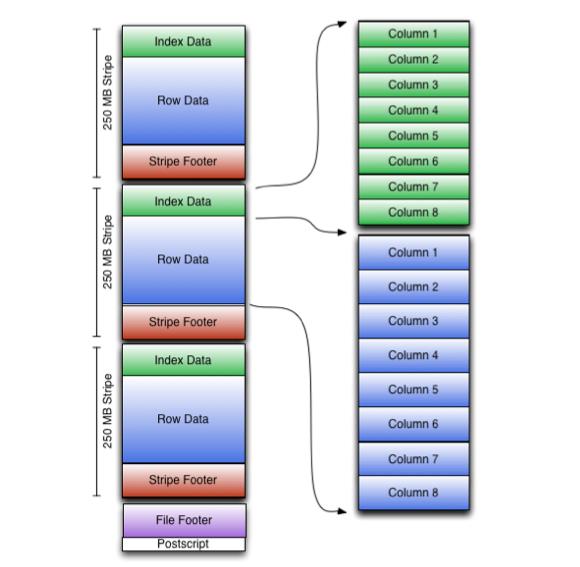
这里笔者就不一一列举了,更多详情,可以阅读官网介绍:[入口地址]
2.2 使用
知道了 ORC 文件的结构,以及相关作用,我们如何去使用 ORC 表,下面我们以创建一个处理 Stream 记录的表为例,其创建示例 SQL 如下所示:
create table alerts ( id int , msg string ) partitioned by (continent string, country string) clustered by (id) into 5 buckets stored as orc tblproperties("transactional"="true"); // currently ORC is required for streaming
需要注意的是,在使用 Streaming 的时候,创建 ORC 表,需要使用分区分桶。
下面,我们尝试插入一下数据,来模拟 Streaming 的流程,代码如下所示:
String dbName = "testing"; String tblName = "alerts"; ArrayList<String> partitionVals = new ArrayList<String>(2); partitionVals.add("Asia"); partitionVals.add("India"); String serdeClass = "org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe"; HiveEndPoint hiveEP = new HiveEndPoint("thrift://x.y.com:9083", dbName, tblName, partitionVals);
如果,有多个分区,我们这里可以将分区存放在分区集合中,进行加载。这里,需要开启 metastore 服务来确保 Hive 的 Thrift 服务可用。
//------- Thread 1 -------// StreamingConnection connection = hiveEP.newConnection(true); DelimitedInputWriter writer = new DelimitedInputWriter(fieldNames,",", endPt); TransactionBatch txnBatch = connection.fetchTransactionBatch(10, writer); ///// Batch 1 - First TXN txnBatch.beginNextTransaction(); txnBatch.write("1,Hello streaming".getBytes()); txnBatch.write("2,Welcome to streaming".getBytes()); txnBatch.commit(); if(txnBatch.remainingTransactions() > 0) { ///// Batch 1 - Second TXN txnBatch.beginNextTransaction(); txnBatch.write("3,Roshan Naik".getBytes()); txnBatch.write("4,Alan Gates".getBytes()); txnBatch.write("5,Owen O’Malley".getBytes()); txnBatch.commit(); txnBatch.close(); connection.close(); } txnBatch = connection.fetchTransactionBatch(10, writer); ///// Batch 2 - First TXN txnBatch.beginNextTransaction(); txnBatch.write("6,David Schorow".getBytes()); txnBatch.write("7,Sushant Sowmyan".getBytes()); txnBatch.commit(); if(txnBatch.remainingTransactions() > 0) { ///// Batch 2 - Second TXN txnBatch.beginNextTransaction(); txnBatch.write("8,Ashutosh Chauhan".getBytes()); txnBatch.write("9,Thejas Nair" getBytes()); txnBatch.commit(); txnBatch.close(); } connection.close();
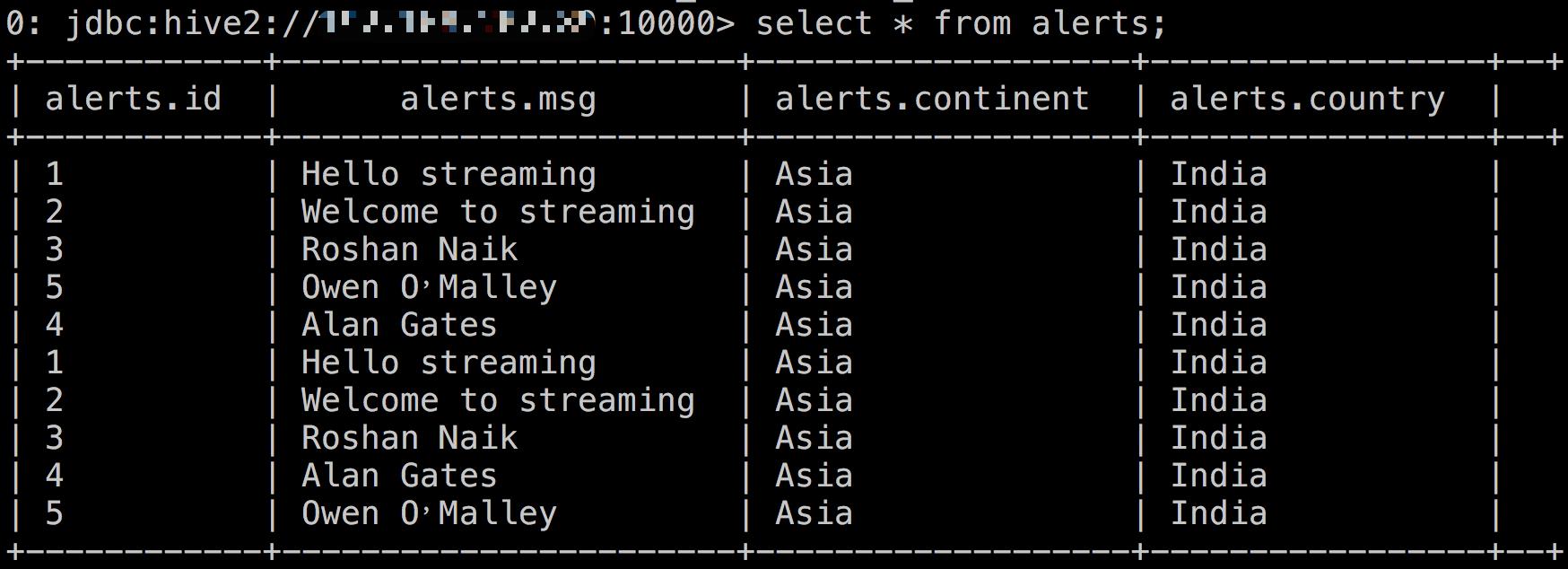
接下来,我们对 Streaming 数据进行写入到 ORC 表进行存储。实现结果如下图所示:
3.案例
下面,我们来完成一个完整的案例,有这样一个场景,每天有许多业务数据上报到指定服务器,然后有中转服务将各个业务数据按业务拆分后转发到各自的日志节点,再由 ETL 服务将数据入库到 Hive 表。这里,我们只说说入库 Hive 表的流程,拿到数据,处理后,入库到 Hive 的 ORC 表中。具体实现代码如下所示:
/** * @Date Nov 24, 2016 * * @Author smartloli * * @Email smartdengjie@gmail.com * * @Note TODO */ public class IPLoginStreaming extends Thread { private static final Logger LOG = LoggerFactory.getLogger(IPLoginStreaming.class); private String path = ""; public static void main(String[] args) throws Exception { String[] paths = SystemConfigUtils.getPropertyArray("hive.orc.path", ","); for (String str : paths) { IPLoginStreaming ipLogin = new IPLoginStreaming(); ipLogin.path = str; ipLogin.start(); } } @Override public void run() { List<String> list = FileUtils.read(this.path); long start = System.currentTimeMillis(); try { write(list); } catch (Exception e) { LOG.error("Write PATH[" + this.path + "] ORC has error,msg is " + e.getMessage()); } System.out.println("Path[" + this.path + "] spent [" + (System.currentTimeMillis() - start) / 1000.0 + "s]"); } public static void write(List<String> list) throws ConnectionError, InvalidPartition, InvalidTable, PartitionCreationFailed, ImpersonationFailed, InterruptedException, ClassNotFoundException, SerializationError, InvalidColumn, StreamingException { String dbName = "default"; String tblName = "ip_login_orc"; ArrayList<String> partitionVals = new ArrayList<String>(1); partitionVals.add(CalendarUtils.getDay()); String[] fieldNames = new String[] { "_bpid", "_gid", "_plat", "_tm", "_uid", "ip", "latitude", "longitude", "reg", "tname" }; StreamingConnection connection = null; TransactionBatch txnBatch = null; try { HiveEndPoint hiveEP = new HiveEndPoint("thrift://master:9083", dbName, tblName, partitionVals); HiveConf hiveConf = new HiveConf(); hiveConf.setBoolVar(HiveConf.ConfVars.HIVE_HADOOP_SUPPORTS_SUBDIRECTORIES, true); hiveConf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem"); connection = hiveEP.newConnection(true, hiveConf); DelimitedInputWriter writer = new DelimitedInputWriter(fieldNames, ",", hiveEP); txnBatch = connection.fetchTransactionBatch(10, writer); // Batch 1 txnBatch.beginNextTransaction(); for (String json : list) { String ret = ""; JSONObject object = JSON.parseObject(json); for (int i = 0; i < fieldNames.length; i++) { if (i == (fieldNames.length - 1)) { ret += object.getString(fieldNames[i]); } else { ret += object.getString(fieldNames[i]) + ","; } } txnBatch.write(ret.getBytes()); } txnBatch.commit(); } finally { if (txnBatch != null) { txnBatch.close(); } if (connection != null) { connection.close(); } } } }
PS:建议使用多线程来处理数据。
4.预览
实现结果如下所示:
- 分区详情

- 该分区下记录数

5.总结
在使用 Hive Streaming 来实现 ORC 追加的时候,除了表本身需要分区分桶以外,工程本身的依赖也是复杂,会设计 Hadoop Hive 等项目的依赖包,推荐使用 Maven 工程来实现,由 Maven 工程去帮我们解决各个 JAR 包之间的依赖问题。
6.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
以上是关于Hive Streaming 追加 ORC 文件的主要内容,如果未能解决你的问题,请参考以下文章