发现公司里的大数据开发挣得很多,想转行,
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了发现公司里的大数据开发挣得很多,想转行,相关的知识,希望对你有一定的参考价值。
最近试听了八斗学院的Hadoop大数据视频,感觉比较好,有过来人给个建议吗?
转行这个词汇,一直是职场上此起彼伏的一个热门话题,相信很多朋友都想过或已经经历过转行。工作可谓是我们生存乃至生活的主要收入来源,谁都希望拥有一份高薪又稳定的工作,以此来改善自己的生活和实现自己的大大小小的梦想!但又担心转行后的工作待遇达不到自己的预期,顾虑重重……
不少想进入大数据分析行业的零基础学员经常会有这样一些疑问:大数据分析零基础应该怎么学习?自己适合学习大数据分析吗?人生,就是在不断地做选择,然后在这个选择过程中成长,让自己从一棵小树苗变成参天大树。就是我们每个对大数据充满幻想终于下定决心行动的学员的选择,我们给了自己4个月的时间,想要在大数据分析这个领域汲取养分,让自己壮大成长。
【明确方向】
通过国家的战略规划,看到BAT的大牛们都在大数据行业布局,新闻媒体追捧这大数据分析行业的项目和热点,我想如果我还没有能力独立判断的时候,跟着国家政策和互联网大佬们的步调走,这应该是错不了的。
【付诸行动】
明确了方向之后,我就整装待发,刚开始是在网络上购买了很多的视频教程,也买了很多书籍,但是最大的问题就在于,我不知道怎么入手,没关系,有信心有耐心肯定能战胜困难,我坚持了一个月,学习的节奏越来越乱,陆陆续续出现了很多的问题,没人指导,请教了几个业内的朋友,但对方工作繁忙,问了几次之后就不好意思了,自学陷入了死循环。
意识到我学习效率的低下,以及无人指导的问题想想未来的康庄大道,咬咬牙告诉自己,一定好好好学,不然就浪费太多时间最后还会是一无所获。最后找到组织(AAA教育)一起学习进步!
大数据分析零基础学习路线,有信心能坚持学习的话,那就当下开始行动吧!
一、大数据技术基础
1、linux操作基础
linux系统简介与安装
linux常用命令–文件操作
linux常用命令–用户管理与权限
linux常用命令–系统管理
linux常用命令–免密登陆配置与网络管理
linux上常用软件安装
linux本地yum源配置及yum软件安装
linux防火墙配置
linux高级文本处理命令cut、sed、awk
linux定时任务crontab
2、shell编程
shell编程–基本语法
shell编程–流程控制
shell编程–函数
shell编程–综合案例–自动化部署脚本
3、内存数据库redis
redis和nosql简介
redis客户端连接
redis的string类型数据结构操作及应用-对象缓存
redis的list类型数据结构操作及应用案例-任务调度队列
redis的hash及set数据结构操作及应用案例-购物车
redis的sortedset数据结构操作及应用案例-排行榜
4、布式协调服务zookeeper
zookeeper简介及应用场景
zookeeper集群安装部署
zookeeper的数据节点与命令行操作
zookeeper的java客户端基本操作及事件监听
zookeeper核心机制及数据节点
zookeeper应用案例–分布式共享资源锁
zookeeper应用案例–服务器上下线动态感知
zookeeper的数据一致性原理及leader选举机制
5、java高级特性增强
Java多线程基本知识
Java同步关键词详解
java并发包线程池及在开源软件中的应用
Java并发包消息队里及在开源软件中的应用
Java JMS技术
Java动态代理反射
6、轻量级RPC框架开发
RPC原理学习
Nio原理学习
Netty常用API学习
轻量级RPC框架需求分析及原理分析
轻量级RPC框架开发
二、离线计算系统
1、hadoop快速入门
hadoop背景介绍
分布式系统概述
离线数据分析流程介绍
集群搭建
集群使用初步
2、HDFS增强
HDFS的概念和特性
HDFS的shell(命令行客户端)操作
HDFS的工作机制
NAMENODE的工作机制
java的api操作
案例1:开发shell采集脚本
3、MAPREDUCE详解
自定义hadoop的RPC框架
Mapreduce编程规范及示例编写
Mapreduce程序运行模式及debug方法
mapreduce程序运行模式的内在机理
mapreduce运算框架的主体工作流程
自定义对象的序列化方法
MapReduce编程案例
4、MAPREDUCE增强
Mapreduce排序
自定义partitioner
Mapreduce的combiner
mapreduce工作机制详解
5、MAPREDUCE实战
maptask并行度机制-文件切片
maptask并行度设置
倒排索引
共同好友
6、federation介绍和hive使用
Hadoop的HA机制
HA集群的安装部署
集群运维测试之Datanode动态上下线
集群运维测试之Namenode状态切换管理
集群运维测试之数据块的balance
HA下HDFS-API变化
hive简介
hive架构
hive安装部署
hvie初使用
7、hive增强和flume介绍
HQL-DDL基本语法
HQL-DML基本语法
HIVE的join
HIVE 参数配置
HIVE 自定义函数和Transform
HIVE 执行HQL的实例分析
HIVE最佳实践注意点
HIVE优化策略
HIVE实战案例
Flume介绍
Flume的安装部署
案例:采集目录到HDFS
案例:采集文件到HDFS
三、流式计算
1、Storm从入门到精通
Storm是什么
Storm架构分析
Storm架构分析
Storm编程模型、Tuple源码、并发度分析
Storm WordCount案例及常用Api分析
Storm集群部署实战
Storm+Kafka+Redis业务指标计算
Storm源码下载编译
Strom集群启动及源码分析
Storm任务提交及源码分析
Storm数据发送流程分析
Storm通信机制分析
Storm消息容错机制及源码分析
Storm多stream项目分析
编写自己的流式任务执行框架
2、Storm上下游及架构集成
消息队列是什么
Kakfa核心组件
Kafka集群部署实战及常用命令
Kafka配置文件梳理
Kakfa JavaApi学习
Kafka文件存储机制分析
Redis基础及单机环境部署
Redis数据结构及典型案例
Flume快速入门
Flume+Kafka+Storm+Redis整合
四、内存计算体系Spark
1、scala编程
scala编程介绍
scala相关软件安装
scala基础语法
scala方法和函数
scala函数式编程特点
scala数组和集合
scala编程练习(单机版WordCount)
scala面向对象
scala模式匹配
actor编程介绍
option和偏函数
实战:actor的并发WordCount
柯里化
隐式转换
2、AKKA与RPC
Akka并发编程框架
实战:RPC编程实战
3、Spark快速入门
spark介绍
spark环境搭建
RDD简介
RDD的转换和动作
实战:RDD综合练习
RDD高级算子
自定义Partitioner
实战:网站访问次数
广播变量
实战:根据IP计算归属地
自定义排序
利用JDBC RDD实现数据导入导出
WorldCount执行流程详解
4、RDD详解
RDD依赖关系
RDD缓存机制
RDD的Checkpoint检查点机制
Spark任务执行过程分析
RDD的Stage划分
5、Spark-Sql应用
Spark-SQL
Spark结合Hive
DataFrame
实战:Spark-SQL和DataFrame案例
6、SparkStreaming应用实战
Spark-Streaming简介
Spark-Streaming编程
实战:StageFulWordCount
Flume结合Spark Streaming
Kafka结合Spark Streaming
窗口函数
ELK技术栈介绍
ElasticSearch安装和使用
Storm架构分析
Storm编程模型、Tuple源码、并发度分析
Storm WordCount案例及常用Api分析
7、Spark核心源码解析
Spark源码编译
Spark远程debug
Spark任务提交行流程源码分析
Spark通信流程源码分析
SparkContext创建过程源码分析
DriverActor和ClientActor通信过程源码分析
Worker启动Executor过程源码分析
Executor向DriverActor注册过程源码分析
Executor向Driver注册过程源码分析
DAGScheduler和TaskScheduler源码分析
Shuffle过程源码分析
Task执行过程源码分析
五、机器学习算法
1、python及numpy库
机器学习简介
机器学习与python
python语言–快速入门
python语言–数据类型详解
python语言–流程控制语句
python语言–函数使用
python语言–模块和包
phthon语言–面向对象
python机器学习算法库–numpy
机器学习必备数学知识–概率论
2、常用算法实现
knn分类算法–算法原理
knn分类算法–代码实现
knn分类算法–手写字识别案例
lineage回归分类算法–算法原理
lineage回归分类算法–算法实现及demo
朴素贝叶斯分类算法–算法原理
朴素贝叶斯分类算法–算法实现
朴素贝叶斯分类算法–垃圾邮件识别应用案例
kmeans聚类算法–算法原理
kmeans聚类算法–算法实现
kmeans聚类算法–地理位置聚类应用
决策树分类算法–算法原理
决策树分类算法–算法实现
时下的大数据分析时代与人工智能热潮,相信有许多对大数据分析师非常感兴趣、跃跃欲试想着转行的朋友,但面向整个社会,最不缺的其实就是人才,对于是否转行大数据分析行列,对于能否勇敢一次跳出自己的舒适圈,不少人还是踌躇满志啊!毕竟好多决定,一旦做出了就很难再回头了。不过如果你已经转行到大数据分析领域,就不要后悔,做到如何脱颖而出才是关键。因此本文给出一些建议,针对想要转行大数据分析行列且是零基础转行的小伙伴们,希望对你们有所裨益,也希望你们将来学有所成,不后悔,更不灰心!
相关推荐:
《转行大数据分析师后悔了》、《ui设计培训四个月骗局大爆料》、《零基础学大数据分析现实吗》、《大数据分析十八般工具》
参考技术A 您好:大数据技术前景我们是毋庸置疑的,而对于学习更是争先恐后。在这些人中,不乏有已经在IT圈混迹好几年的程序员,自然也有初出茅庐的零基础小白。说实话,大数据不比编程学习,还是需要一定的基础的,时间起码需要半年左右。
想要成为一个优秀的大数据人才并不容易,你不仅需要系统的学习理论知识,熟练掌握技能技巧,还需要具备一定的开发经验,而这些仅靠自学是远远不够的,比较好的方式就是参加专业学习。希望可以帮到你。 参考技术B 理工程师是职称,不需要考试,只要工作年限到了就可以评,大专要两年吧。 这两个都有用啊,最好是都弄上。 参考技术C 大数据的开发也是需要一定基础的,你可以试试。 参考技术D 建议就是如果决定要学Hadoop开发一定要坚持下去,不能半途而废。大数据人才现在确实很缺,我们公司就有2个空缺一直招不到人。八斗学院的课程设置还不错,公司的招聘要求里提到的技术他们都讲到了,挺适合学习转型的。本回答被提问者采纳
为什么很多Java程序员都转行做大数据了?
如今大数据发展的越来越成熟。各大企业纷纷成立大数据部门。尤其BAT等一线互联网公司每天处理的数据量都是TB级别。大数据部门已成为这些企业的核心部门,数据已成为企业最核心的资产。
但是大数据人才缺口巨大,据统计目前全国的大数据人才仅46万,未来3-5年内大数据人才的缺口将高达150万。
因此大数据工程师薪资也比其他职位高出不少。以北京为例。1-3年的大数据工程师平均年薪30-50万,3-5年经验的大数据工程师年薪在50-80万。想学习的同学欢迎加入大数据学习扣群:458345782,有大量干货(零基础以及进阶的经典实战)分享给大家
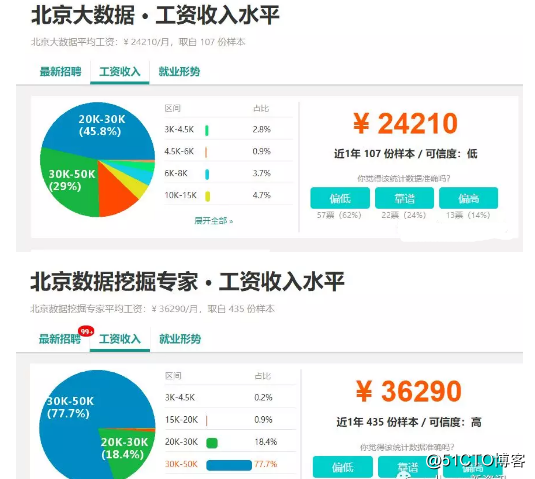
因此很多java程序员也想转入大数据行业,但是很多java程序员有一个共同困惑不知道掌握java那些知识才能很好的转型大数据。
鉴于此问题在这和大家交流交流。
Java程序员想转型大数据其实只需会以下两大知识点即可。
1、Linux。Linux知识是一个后端开发程序员必备的知识。在大数据领域,服务器环境往往是集群形式,多台服务器。通常会在多台服务器上部署大数据分布式开发环境。因此对Linux基本命令、软件安装以及会写shell脚本来提交大数据作业等知识有一定要求。
2、javase。大数据很多技术都是用java语言编写的。如hadoop。一些大型的大数据项目主要开发语言也是java。懂java知识学习大数据很有优势
Java程序员转型大数据是一个非常好的选择方向。大数据发展方向众多。有大数据开发工程师、数据挖掘分析工程师、大数据运维工程师等。
为回馈粉丝,两位老师有多年一线互联网TB级别数据处理经验,实战丰富。
林夕,百度大数据高级工程师,在百度从0开始构建60台大数据集群,每日处理数据TB级别,保障业务稳定运行,有丰富的大数据实战经验。中国科大硕士毕业,发表论文4篇,发明专利4项,华为杯比赛全国一等奖。对hadoop、spark、hive、 storm等大数据技术有深刻研究。熟悉机器学习各大算法及推荐系统原理架构及实现方法。
李金泽,清华大学硕士研究生,发明专利一项,实用新型两项,在大数据和机器学习领域具有多年一线实战经验。参与过多个军工单位和国家级课题的研究,曾主导工业级大数据容器云平台解决方案的部署与研发。热爱各项开源技术,擅长把复杂的问题简单表达。对hadoop生态、hive、storm、spark及各大机器学习算法均有深入研究。
徐威,拥有8年上市互联网公司软件研发经验。曾任职猎豹移动担任大数据Team Leader。带领团队开发海外舆情监控系统、数据采集平台、olap数据分析平台、数据仓库、PB级数据检索系统等。
colleage新资讯 1周前
如今大数据发展的越来越成熟。各大企业纷纷成立大数据部门。尤其BAT等一线互联网公司每天处理的数据量都是TB级别。大数据部门已成为这些企业的核心部门,数据已成为企业最核心的资产。
但是大数据人才缺口巨大,据统计目前全国的大数据人才仅46万,未来3-5年内大数据人才的缺口将高达150万。
因此大数据工程师薪资也比其他职位高出不少。以北京为例。1-3年的大数据工程师平均年薪30-50万,3-5年经验的大数据工程师年薪在50-80万。
因此很多java程序员也想转入大数据行业,但是很多java程序员有一个共同困惑不知道掌握java那些知识才能很好的转型大数据。
鉴于此问题在这和大家交流交流。
Java程序员想转型大数据其实只需会以下两大知识点即可。
1、Linux。Linux知识是一个后端开发程序员必备的知识。在大数据领域,服务器环境往往是集群形式,多台服务器。通常会在多台服务器上部署大数据分布式开发环境。因此对Linux基本命令、软件安装以及会写shell脚本来提交大数据作业等知识有一定要求。
2、javase。大数据很多技术都是用java语言编写的。如hadoop。一些大型的大数据项目主要开发语言也是java。懂java知识学习大数据很有优势
Java程序员转型大数据是一个非常好的选择方向。大数据发展方向众多。有大数据开发工程师、数据挖掘分析工程师、大数据运维工程师等。
为回馈粉丝,两位老师有多年一线互联网TB级别数据处理经验,实战丰富。
林夕,百度大数据高级工程师,在百度从0开始构建60台大数据集群,每日处理数据TB级别,保障业务稳定运行,有丰富的大数据实战经验。中国科大硕士毕业,发表论文4篇,发明专利4项,华为杯比赛全国一等奖。对hadoop、spark、hive、 storm等大数据技术有深刻研究。熟悉机器学习各大算法及推荐系统原理架构及实现方法。
李金泽,清华大学硕士研究生,发明专利一项,实用新型两项,在大数据和机器学习领域具有多年一线实战经验。参与过多个军工单位和国家级课题的研究,曾主导工业级大数据容器云平台解决方案的部署与研发。热爱各项开源技术,擅长把复杂的问题简单表达。对hadoop生态、hive、storm、spark及各大机器学习算法均有深入研究。
徐威,拥有8年上市互联网公司软件研发经验。曾任职猎豹移动担任大数据Team Leader。带领团队开发海外舆情监控系统、数据采集平台、olap数据分析平台、数据仓库、PB级数据检索系统等。
想学习的同学欢迎加入大数据学习扣群:458345782,有大量干货(零基础以及进阶的经典实战)分享给大家
以上是关于发现公司里的大数据开发挣得很多,想转行,的主要内容,如果未能解决你的问题,请参考以下文章