LSTM梳理,理解,和keras实现
Posted yuki_lee
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LSTM梳理,理解,和keras实现 相关的知识,希望对你有一定的参考价值。
注:本文主要是在http://colah.github.io/posts/2015-08-Understanding-LSTMs/ 这篇文章的基础上理解写成,姑且也可以称作 The understanding of understanding LSTM network. 感谢此篇作者的无私分享和通俗精确的讲解。
一. RNN
说到LSTM,无可避免的首先要提到最简单最原始的RNN。在这一部分,我的目标只是理解“循环神经网络”中的‘循环’二字,不打算扔出任何公式,顺便一提曾经困惑过我的keras中的输入数据格式。
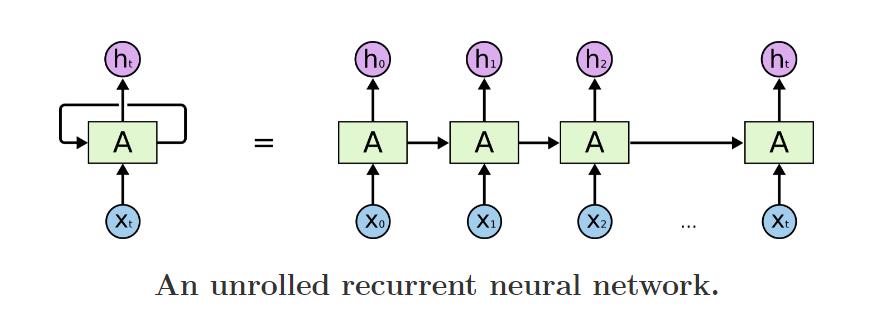
我们经常可以看到有人说,LSTM适合时序序列,变长序列,尤其适合自然语言处理。那么是什么赋予它可以处理变长序列的能力呢? 其实,只要仔细研究上图,相信每个人都能有一个直观的答案。
从图片左边来看,RNN有两个输入,一个是当前t时刻的输入Xt, 另一个是一个看似“本身“的输入。
这样看还不甚明了,再看图片右边: 实际上右图是左图的一个在时间序列上的展开,上一个时刻输出是这一个时刻的输入。值得注意的是,实际上,右图上的所有神经元是同一个神经元,也就是左图,它们共享同样的权值,只不过在每一个时刻接受不同的输入,再把输出给下一个时刻作为输入。这就是存储的过去的信息。
理解到“循环”的含义即达到本章的目的了,公式和细节将在LSTM中详细叙述。
keras中文文档: http://keras-cn.readthedocs.io/en/latest/layers/recurrent_layer/ (中文文档真的做的很赞,除了翻译的内容,还加了额外的内容,例如tensor, batch size的概念帮助DL新手理解)
在所有的RNN中,包括simpleRNN, LSTM, GRU等等,输入输出数据格式如下:

输入是一个三维向量。samples即为数据的条数。难以理解的是timesteps 和input_dim. Input_dim是数据的表示形式的维度,timestep则为总的时间步数。例如这样一个数据,总共100条句子,每个句子20个词,每个词都由一个80维的向量表示。在RNN中,每一个timestep的输入是一个词(当然这不一定,你也可以调成两个词或者其他),从第一张RNN的图来看,t0时刻是第一个时间步,x0则为代表一条句子中第一个词的80维向量,t1是第二个时间步,x1表示句子中第二个词的80维向量。。。所以,输入数据的大小应当是(100, 20, 80)
注:实际中句子长度不会一模一样,但从RNN的工作流程来看,它可以处理变长序列。在kera中,可以首先将句子设为最大长度,不足这个长度的句子补足0,然后在RNN层前加embedding层或者Mask层过滤掉补足的字符。具体在我的博文中
http://www.cnblogs.com/leeshum/p/6089286.html
未完待续。。(搬砖去了)
以上是关于LSTM梳理,理解,和keras实现 的主要内容,如果未能解决你的问题,请参考以下文章