记一次企业级爬虫系统升级改造:基于AngleSharp实现的抓取服务
Posted 彩色铅笔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记一次企业级爬虫系统升级改造:基于AngleSharp实现的抓取服务相关的知识,希望对你有一定的参考价值。
爬虫系统升级改造正式启动:
在第一篇文章,博主主要介绍了本次改造的爬虫系统的业务背景与全局规划构思:
未来Support云系统,不仅仅是爬虫系统,是集爬取数据、数据建模处理统计分析、支持全文检索资源库、其他业务部门和公司资讯系统重要数据来源、辅助决策等功能于一身的企业级Support系统。
介于好多园友对博主的任务排期表感兴趣,便介绍一下博主当时针对这个系统做的工作任务排期概要(排期表就是更加详细细分外加估算工时的一份excel表格,就不贴出来了):
1.总分四大阶段,逐步上线,最终达到预期规划
2.第一阶段实现一个新的采集系统,自动实时化爬取数据、初步规则引擎实现数据规则化、统计邮件自动推送、开放数据检索,并上线替换原有爬虫系统
3.第二阶段实现规则化引擎升级,扩展成长式规则引擎,并开放采集源提交、管理、规则配置、基础数据服务等基本系统操作
4.第三阶段引入全文检索,针对规则化数据创建索引,提供数据全文搜索功能,开放工单申请,可定制数据报告
5.第四阶段引入数据报表功能,开放统计分析结果,并向舆情监控与决策支持方向扩展
当然,在博主未争取到更多资源的情况下,第一阶段的排期要求了一个月,后面各阶段只做了功能规划,并未做时间排期。
这也算是一个小手段吧,毕竟第一阶段上线,boss们是可能提很多其他意见,或者遇到其他任务安排的,不能一开始就把时间节点写死,不然最终受伤的可能是程序员自己。
你比他好一点,他不会承认你,反而会嫉妒你,只有你比他好很多,他才会承认你,然后还会很崇拜你,所以要做,就一定要比别人做得好很多。
代码框架搭建:
虽然大家都对我的“SupportYun”命名颇有异议,但是我依然我行我素,哈哈~~~总感觉读起来很和谐
先上一张截止今天,项目结构的整体图:
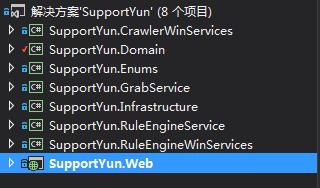
博主一直很喜爱DDD的设计模式,也在很多项目中引用了一些经典DDD模式的框架,但是明显这次的任务是不适合做DDD的。
引入了EF Code First做数据持久化,未引入相关的各种操作扩展,这次打算纯拉姆达表达式来写,毕竟吃多了荤的,偶尔也想尝几口素,调剂调剂口味~
两个WinServices分别是爬虫服务与规则化引擎服务。全文检索相关由于近期不会涉及,故暂未引入,相信其他的类库大家看命名就明白是干什么的了。
一匹真正的好马,即使没有伯乐赏识,也能飞奔千里。
爬虫服务剖析:
1.先来看Support.Domain,sorrry,原谅我对DDD爱得深沉,总是喜欢用Domain这个命名。
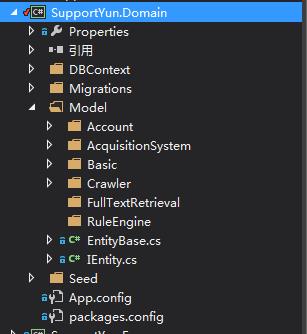
Basic和Account是一些常规表模型,就不一一介绍了。
顺带给大家共享一份一直在用的全国省市县数据sql,下载地址(不要积分,放心下载):http://download.csdn.net/detail/cb511612371/9700143
Migrations熟悉EF的都应该知道,是DB迁移文件夹,每次模型有所改变,直接命令行执行,生成迁移文件,update数据库就OK了。命令行如下:
a)Enable-Migrations -ProjectName EFModel命名空间
-- 开启数据迁移(开启后,该类库下会生成Migrations文件夹,无需多次开启)
b)Add-Migration Name -ProjectName EFModel命名空间
-- 添加数据迁移方案(指定一个名称,添加后会在Migrations文件夹下生成对应迁移方案代码)
c)Update-Database -ProjectName EFModel命名空间
-- 执行数据迁移方案(匹配数据库迁移方案,修改数据库)
再来看爬虫服务的模型:

博主设计了四张表来处理爬虫服务,分别存储采集源<-1:n->采集规则<-1:n->初始采集数据,规则分组(主要用于将执行间隔相同的规则分为一组,以便后期抓取任务量大时,拆分服务部署)
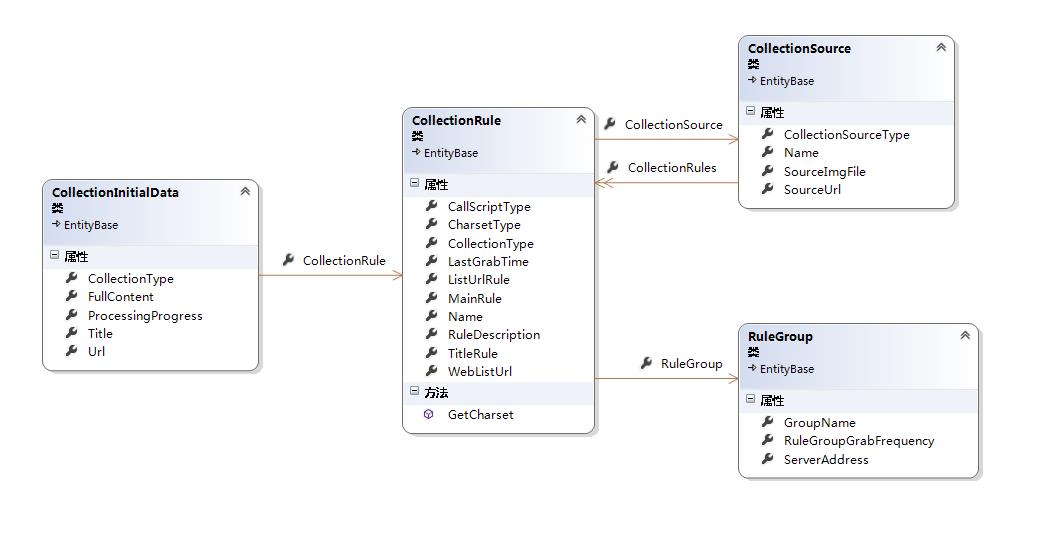
2.再来看SupportYun.GrabService,顾名思义,这就是我们爬虫抓取服务的核心逻辑所在。
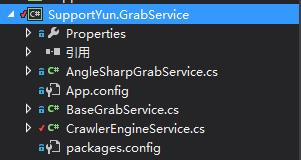
由于时间紧急,博主当前只做了使用AngleSharp来抓取的服务,以后会逐步扩充基于正则表达式以及其他第三方组件的抓取服务。
CrawlerEngineService 是爬虫服务的对外引擎,所有爬取任务都应该是启动它来执行爬取。
其实,爬取别人网页服务的本质很简单,就是一个获取html页面,然后解析的过程。那么我们来看看针对博主的模型设计,具体又该是怎样一个流程:
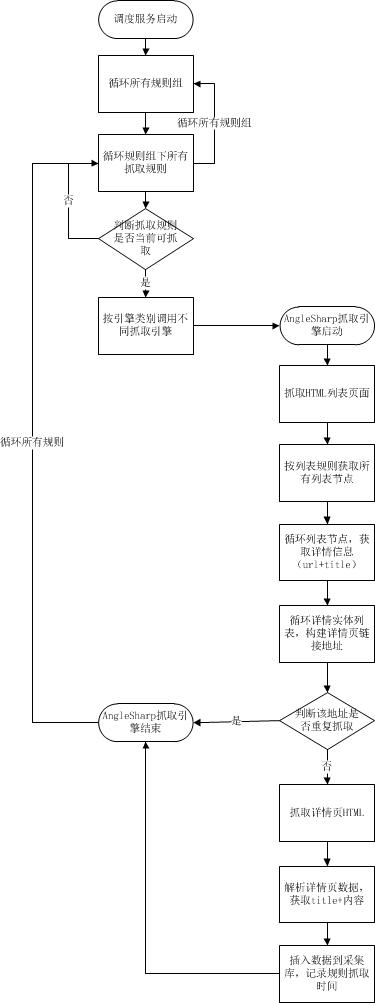
可以看到,博主目前是在爬虫引擎里面循环所有的规则分组,当以后规则扩张,抓取频率多样化后,可以分布式部署多套任务框架,指定各自的任务规则组来启动引擎,即可达到面向服务的任务分流效果。
3.最后,我们需要创建一个Windows服务来做任务调度(博主当前使用的比较简单,引入其他任务调度框架来做也是可以的哈~),它就是:SupportYun.CrawlerWinServices
windows服务里面的逻辑就比较简单啦,就是起到一个定时循环执行任务的效果,直接上核心代码:
1 public partial class Service1 : ServiceBase 2 { 3 private CrawlerEngineService crawlerService=new CrawlerEngineService(); 4 5 public Service1() 6 { 7 InitializeComponent(); 8 } 9 10 protected override void OnStart(string[] args) 11 { 12 try 13 { 14 EventLog.WriteEntry("【Support云爬虫服务启动】"); 15 CommonTools.WriteLog("【Support云爬虫服务启动】"); 16 17 Timer timer = new Timer(); 18 // 循环间隔时间(默认5分钟) 19 timer.Interval = StringHelper.StrToInt(ConfigurationManager.AppSettings["TimerInterval"].ToString(), 300) * 1000; 20 // 允许Timer执行 21 timer.Enabled = true; 22 // 定义回调 23 timer.Elapsed += new ElapsedEventHandler(TimedTask); 24 // 定义多次循环 25 timer.AutoReset = true; 26 } 27 catch (Exception ex) 28 { 29 CommonTools.WriteLog("【服务运行 OnStart:Error" + ex + "】"); 30 } 31 } 32 33 private void TimedTask(object source, System.Timers.ElapsedEventArgs e) 34 { 35 System.Threading.ThreadPool.QueueUserWorkItem(delegate 36 { 37 crawlerService.Main(); 38 }); 39 } 40 41 protected override void OnStop() 42 { 43 CommonTools.WriteLog(("【Support云爬虫服务停止】")); 44 EventLog.WriteEntry("【Support云爬虫服务停止】"); 45 } 46 }
第35行是启用了线程池,放进队列的是爬虫抓取引擎服务的启动方法。
windows服务的具体部署,相信大家都会,园子里也有很多园友写过相关文章,就不详细解释了。
4.那么我们再来梳理一下当前博主整个爬虫服务的整体流程:

不论对错,只要你敢思考,并付诸行动,你就可以被称为“软件工程师”,而不再是“码农”。
爬取服务核心代码:
上面说的都是博主针对整个系统爬虫服务的梳理与设计。最核心的当然还是我们最终实现的代码。
一切不以最终实践为目的的构思设计,都是耍流氓。
我们首先从看看抓取服务引擎的启动方法:
1 public void Main() 2 { 3 using (var context = new SupportYunDBContext()) 4 { 5 var groups = context.RuleGroup.Where(t => !t.IsDelete).ToList(); 6 foreach (var group in groups) 7 { 8 try 9 { 10 var rules = 11 context.CollectionRule.Where(r => !r.IsDelete && r.RuleGroup.Id == group.Id).ToList(); 12 if (rules.Any()) 13 { 14 foreach (var rule in rules) 15 { 16 if (CheckIsAllowGrab(rule)) 17 { 18 // 目前只开放AngleSharp方式抓取 19 if (rule.CallScriptType == CallScriptType.AngleSharp) 20 { 21 angleSharpGrabService.OprGrab(rule.Id); 22 } 23 } 24 } 25 } 26 } 27 catch (Exception ex) 28 { 29 // TODO:记录日志 30 continue; 31 } 32 } 33 } 34 }
上面说了,当前只考虑一个爬虫服务,故在这儿循环了所有规则组。
第16行主要是校验规则是否允许抓取(根据记录的上次抓取时间和所在规则组的抓取频率做计算)。
我们看到,引擎服务只起到一个调度具体抓取服务的作用。那么我们来看看具体的AngleSharpGrabService,基于AngleSharp的抓取服务:

IsRepeatedGrab 这个方法应该是抽象类方法,博主就不换图了哈。
它对外暴露的是一个OprGrab抓取方法:
1 /// <summary> 2 /// 抓取操作 3 /// </summary> 4 /// <param name="ruleId">规则ID</param> 5 public void OprGrab(Guid ruleId) 6 { 7 using (var context = new SupportYunDBContext()) 8 { 9 var ruleInfo = context.CollectionRule.Find(ruleId); 10 if (ruleInfo == null) 11 { 12 throw new Exception("抓取规则已不存在!"); 13 } 14 15 // 获取列表页 16 string activityListHtml = this.GetHtml(ruleInfo.WebListUrl, ruleInfo.GetCharset()); 17 18 // 加载HTML 19 var parser = new HtmlParser(); 20 var document = parser.Parse(activityListHtml); 21 22 // 获取列表 23 var itemList = this.GetItemList(document, ruleInfo.ListUrlRule); 24 25 // 读取详情页信息 26 foreach (var element in itemList) 27 { 28 List<UrlModel> urlList = GetUrlList(element.InnerHtml); 29 foreach (UrlModel urlModel in urlList) 30 { 31 try 32 { 33 var realUrl = ""; 34 if (urlModel.Url.Contains("http")) 35 { 36 realUrl = urlModel.Url; 37 } 38 else 39 { 40 string url = urlModel.Url.Replace(ruleInfo.CollectionSource.SourceUrl.Trim(), ""); 41 realUrl = ruleInfo.CollectionSource.SourceUrl.Trim() + url; 42 } 43 44 if (!IsRepeatedGrab(realUrl, ruleInfo.Id)) 45 { 46 string contentDetail = GetHtml(realUrl, ruleInfo.GetCharset()); 47 var detailModel = DetailAnalyse(contentDetail, urlModel.Title, ruleInfo); 48 49 if (!string.IsNullOrEmpty(detailModel.FullContent)) 50 { 51 var ruleModel = context.CollectionRule.Find(ruleInfo.Id); 52 ruleModel.LastGrabTime = DateTime.Now; 53 var newData = new CollectionInitialData() 54 { 55 CollectionRule = ruleModel, 56 CollectionType = ruleModel.CollectionType, 57 Title = detailModel.Title, 58 FullContent = detailModel.FullContent, 59 Url = realUrl, 60 ProcessingProgress = ProcessingProgress.未处理 61 }; 62 context.CollectionInitialData.Add(newData); 63 context.SaveChanges(); 64 } 65 } 66 67 } 68 catch 69 { 70 // TODO:记录日志 71 continue; 72 } 73 } 74 } 75 } 76 }
第16行用到的GetHtml()方法,来自于它所继承的抓取基类BaseGrabService:
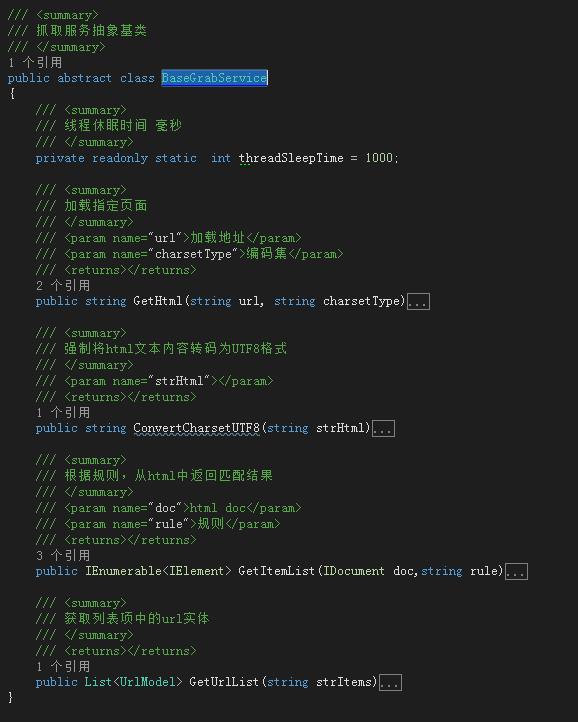
具体代码如下:


1 /// <summary> 2 /// 抓取服务抽象基类 3 /// </summary> 4 public abstract class BaseGrabService 5 { 6 /// <summary> 7 /// 线程休眠时间 毫秒 8 /// </summary> 9 private readonly static int threadSleepTime = 1000; 10 11 /// <summary> 12 /// 加载指定页面 13 /// </summary> 14 /// <param name="url">加载地址</param> 15 /// <param name="charsetType">编码集</param> 16 /// <returns></returns> 17 public string GetHtml(string url, string charsetType) 18 { 19 string result = null; 20 HttpHelper httpHelper = new HttpHelper(); 21 result = httpHelper.RequestResult(url, "GET", charsetType); 22 result = ConvertCharsetUTF8(result); 23 24 // 简单的休眠,防止IP被封 25 // TODO:后期视情况做更进一步设计 26 Thread.Sleep(threadSleepTime); 27 return result; 28 } 29 30 /// <summary> 31 /// 强制将html文本内容转码为UTF8格式 32 /// </summary> 33 /// <param name="strHtml"></param> 34 /// <returns></returns> 35 public string ConvertCharsetUTF8(string strHtml) 36 { 37 if (!strHtml.Contains("Content-Type") && !strHtml.Contains("gb2312")) 38 { 39 if (strHtml.Contains("<title>")) 40 { 41 strHtml = strHtml.Insert(strHtml.IndexOf("<title>", StringComparison.Ordinal), "<meta http-equiv=\\"Content-Type\\" content=\\"text/html; charset=utf-8\\">"); 42 } 43 } 44 else 45 { 46 strHtml = strHtml.Replace("gb2312", "utf-8").Replace("gbk", "utf-8"); 47 } 48 return strHtml; 49 } 50 51 /// <summary> 52 /// 根据规则,从html中返回匹配结果 53 /// </summary> 54 /// <param name="doc">html doc</param> 55 /// <param name="rule">规则</param> 56 /// <returns></returns> 57 public IEnumerable<IElement> GetItemList(IDocument doc,string rule) 58 { 59 var itemList = doc.All.Where(m => m.Id == rule.Trim()); 60 if (!itemList.Any()) 61 { 62 itemList = doc.All.Where(m => m.ClassName == rule.Trim()); 63 } 64 return itemList; 65 } 66 67 /// <summary> 68 /// 获取列表项中的url实体 69 /// </summary> 70 /// <returns></returns> 71 public List<UrlModel> GetUrlList(string strItems) 72 { 73 List<UrlModel> itemList = new List<UrlModel>(); 74 Regex reg = new Regex(@"(?is)<a[^>]*?href=([\'""]?)(?<url>[^\'""\\s>]+)\\1[^>]*>(?<text>(?:(?!</?a\\b).)*)</a>"); 75 MatchCollection mc = reg.Matches(strItems); 76 foreach (Match m in mc) 77 { 78 UrlModel urlModel = new UrlModel(); 79 urlModel.Url = m.Groups["url"].Value.Trim().Replace("amp;", ""); 80 urlModel.Title = m.Groups["text"].Value.Trim(); 81 itemList.Add(urlModel); 82 } 83 84 return itemList; 85 } 86 } 87 88 /// <summary> 89 /// URL对象 90 /// </summary> 91 public class UrlModel 92 { 93 /// <summary> 94 /// 连接地址 95 /// </summary> 96 public string Url { get; set; } 97 98 /// <summary> 99 /// 连接Title 100 /// </summary> 101 public string Title { get; set; } 102 } 103 104 /// <summary> 105 /// 详情内容对象 106 /// </summary> 107 public class DetailModel 108 { 109 /// <summary> 110 /// title 111 /// </summary> 112 public string Title { get; set; } 113 114 /// <summary> 115 /// 内容 116 /// </summary> 117 public string FullContent { get; set; } 118 }
注意AngleSharpGrabService的OprGrab方法第33行至42行,在做url的构建。因为我们抓取到的a标签的href属性很可能是相对地址,在这里我们需要做判断替换成绝对地址。
具体逻辑大家可以参考上面的爬取流程图。
OprGrab方法的第47行即从抓取的具体详情页html中获取详情数据(目前主要获取title和带html标签的内容,具体清理与分析由规则化引擎来完成)。
具体实现代码并无太多营养,和抓取列表页几乎一致:构建document对象,通过规则匹配出含有title的html片段和含有内容的html片段,再对title进行html标签清洗。
具体清洗一个html文本html标签的方法已经属于规则化引擎的范畴,容博主下一篇写规则化引擎服务的时候再来贴出并给大家作分析。
这时候,我们部署在服务器上的windows服务就能按我们配好的规则进行初始数据抓取入库了。
贴一张博主当前测试抓取的数据截图:
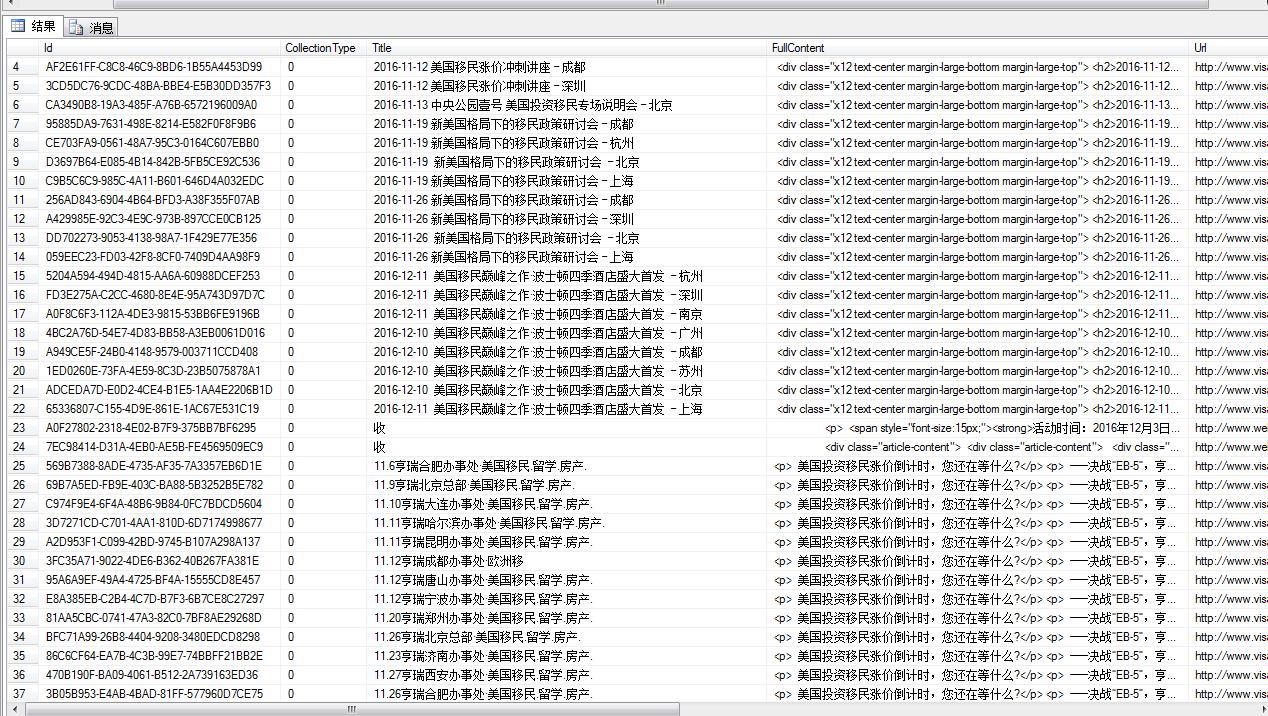
博主终于算是完成了系统的第一步,接下来就是规则化引擎分析FullContent里面的数据了。
博主争取本周写完规则化引擎相关的代码,下周再来分享给大家哈!
可是答应了一个月时间要做好第一阶段的所有内容并上线呢,哎~~~敲代码去
硬的怕横的,横的怕不要命的,疯子都是不要命的,所以疯子力量大,程序员只有一种,疯狂的程序员。
共勉!!!
原创文章,代码都是从自己项目里贴出来的。转载请注明出处哦,亲~~~
以上是关于记一次企业级爬虫系统升级改造:基于AngleSharp实现的抓取服务的主要内容,如果未能解决你的问题,请参考以下文章
项目实践记一次对后端服务进行跨域改造和HTTPS升级的探究和实践
项目实践记一次对后端服务进行跨域改造和HTTPS升级的探究和实践