关联规则
Posted dataAlpha
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关联规则相关的知识,希望对你有一定的参考价值。
关联规则:评定规则的标准
支持度:规则前项LHS和规则后项RHS所包括的商品都同时出现的概率,LHS和RHS商品的交易次数/总交易次数。
置信度:在所有的购买了左边商品的交易中,同时又购买了右边商品的交易机率,包含规则两边商品的交易次数/包括规则左边商品的交易次数。
提升度(有这个规则和没有这个规则是否概率会提升,规则是否有价值):无任何约束的情况下买后项的交易次数/置信度。提升度必须大于1才有意义。
一、Aprioir(利用以前的频繁集产生候选集,从长度为1到2到3...)
利用性质的关键:一个itemsets要想频繁,它所有子集必须频繁,反过来如果有子集不频繁,它的超集也就不可能频繁。所有就可以先找短的,长度为1的都不频繁,包含这个的长的item就不可能频繁,如果长度为1的频繁,就可以继续通过这个找潜在的候选集。
多遍数据库扫描是昂贵的,挖掘长模式需要很多遍扫描,并产生大量候选。Aprioir具有的性质:频繁项集的所有非空子集也必须是频繁的。向下闭包性,利用已满足支持度的频繁,进行组合,生成候选集,只有这些候选集才有可能
首先找频繁一项集(满足最小支持度要求的项集),在频繁一项集的基础上寻找频繁二项集,再依次寻找频繁三、四等等,直到没有满足最小支持度的项集。
(1)怎样寻找候选集呢?selfjoining+pruning
假设L3={abc, abd, acd, ace, bcd} 将频繁集的字母排序
Selfjoining: 共享前缀的abc,abd合并成abcd; ace,acd合并成acde
Pruning: acde可以去掉,因为其中的ade不在频繁项集中
这样L4={abcd}
(2)找到候选集以后怎么去给候选集数数?support counting 候选集--->频繁集
跑到数据库里找,哪些是真正的频繁集,哪些不是?这里需要建立hash tree
如何计算呢?如果把所有频繁项集的非空子集放到一个list中,再通过扫描数据集来统计,每个规则出现的次数,损耗的资源会较大,效率太低(比如频繁项包含10个项,那么就需要扫描完整数据库10次)
更快的方法计数呢,是hash-tree按照一定的规则,将频繁项存储到子节点,然后对每个tranction通过搜索树来计数。复杂度o(log(n)),每个transction都要在这个树结构里面周游。(根据hash function将这些数很有效的分离开,比如hashfunction是1,4,7往左子树走,2,5,8往中间树走,3,6,9往右边走,然后<1,3,6>这个itemset就是左子树,右子树,把左右的candidate按照这个规则塞到一棵树里面,这时候要想去查找每个itemset在一个transaction中是否出现,只需要大约走Log(n),如果找到然后给他的次数+1)
电脑读取过程 CPU-MEMORY-DISK

改进方式有三个角度:
1. 减少扫描数据库的次数(Partition算法、FP-growth算法)
2. 减少候选集(Aprior已经减少了一部分candidates,但还有没有更快的方法)
3. 怎样数这个candiates出现次数数的更快
再根据频繁项集产生关联规则。频繁项集的非空子集(这个数量会很大可能,怎样减少ccandidates也是个巨大的问题)计算置信度,在一定置信度的情况下保留下来相应有用的规则。
Aprioir算法本来orange2.7算法可以实现,不知道为什么orange3给取消了这个算法
伪代码

怎样实现并行?
(1)share memory
整个大机器就是一个大内存的情况,无非两种思路,一种是data parallize一种是task parallize。先说data paralize,肯定是横着划分(由于item数据都不等长,不可能竖着划分),每个process里面有一部分数据,现在是一个大的global memory,所有不需要做任何的数据传输,每个process只要看它们自己的数据(有index),这就是data partition,不存在数据通信,如果我给了它一个hashtree(在global memory里面,把所有的变量声明为全局变量,main function的外面,这样就必然是全局的树),那些candidates,process1就把所有的item都放到树里面找一遍,该加1加1,几个process同时做这一个事情,当两个process对同一个节点加1的时候,我们需要用一个加锁机制loce,一个先加一个后加保证他们不冲突,当三个process做完的时候,就是所有的数据被扫描了一遍,没有任何的重复工作。这就实现了p/n倍的时间了。
知道这些正真的频繁的之后,我们就需要建比这个长度再加1的candidates,这步也可以让多个process并行generate,每个process负责一部分,即上面L3里面的一部分,然后同时去join,完了之后做pruning。这样就有了新的candidates,就要built新的tree了,删除原来的tree。每个process掌握一批candidates,同时建树,按照同样的规则在global memory里面建树,当两个process跑到同一个节点时,就用加锁防止冲突,每个叶节点有个lock,谁拿到这个lock就可以对它分裂,没拿到的就先等着。这个算法就是CCPD common count partition data。
(task paralize也可以,可以让每个task负责一些candidates,相当于每个process负责一部分工作,负责一部分candidates的counting,对整个数据库扫描,等每个process都完成了后,再合起来,就找到了所有candidates的counting了,相比于data paralize就差一点了。)

(2)clusters集群的情况
share nothing的体系结构。每个process都有自己的内存,而不存在共享内存。
data parallize。这种算法叫count distribution。就得通过明确的信息传输,使得每个process上得到n/p个records,数据并行,每个process上有完整的hash tree(这点还是不怎么理想,hash tree有些很大,如果每个节点就是一个pc机的话,有点超过它的能力),扫描在自己那部分数据上,给所有candidates统计一个数,candidates在这部分数据上出来的频率怎么样,当所有的process完成了工作以后,只需要做一次全局的comunication,要把那些counts和candidates通过MPI传来传去,加和sum那些counts,所有的candidates在全体的数据中频率就求出来。process0拥有这个数以后,就很容易知道谁是正真的频繁集,Lk就出来了。紧接着,产生Lk+1的候选集,通常Lk也不会太大,所以这步不用并行计算,直接就由process0产生。再由process0把candidatesLk+1广播出去,使得每个process上又都拥有完整的hash tree,长度为K+1的candiates。下一个循环又开始了,周而复始。
(task parallize。每个process负责一部分candidates,每个process有全体的数据,找到自己负责的candidates是不是真正频繁项,然后通过MPI conmunition产生K+1,再进行通信,再找candidates。还是不如data paralize)
二、FP-Growth
FP-growth算法不同于Apriori算法生成候选项集再检查是否频繁的“产生-测试” 方法,而是使用一种称为频繁模式树(FP-Tree,PF代表频繁模式,Frequent Pattern)菜单紧凑数据结构组织数据,并直接从该结构中提取频繁项集,不需要产生候选集。每个事务被映射到FP-tree的一条路径上,不同的事务会有相同的路径,因此重叠的越多,压缩效果越好。
FP-growth算法分为两个过程,一是根据原始数据构造FP-Tree,(保存原来数据库中元素的关系,又将数据进行了压缩,使得能够在内存中存放)
1.首先扫描一遍数据集,找出频繁项的列表L,并且按照支持度排序,根据此排序调整原数据中事务的排序。
Budget
{f, a, c, d, j, l, m, p}
{f, a, c, h, j}
……….
比如f:4 c:4 a:3 b:3 p:3 l:2 h:2 j:2 假设support=3频率低于3的都淘汰,所以只留下f, c, a, b, p.
Budget就变成
{f, a, c, p}
{f, a, c}
2.然后扫描上面的频繁budget,开始构造FP-tree,根节点为空,处理每个事物时按照L中的顺序将事物中出现的频繁项添加到中的一个分支。每次出现的字母,计数+1,从这颗树中,我们就能找到频繁子集,而不用去扫描完整数据库了。(其实是一边按照上面1排序一边建树的)

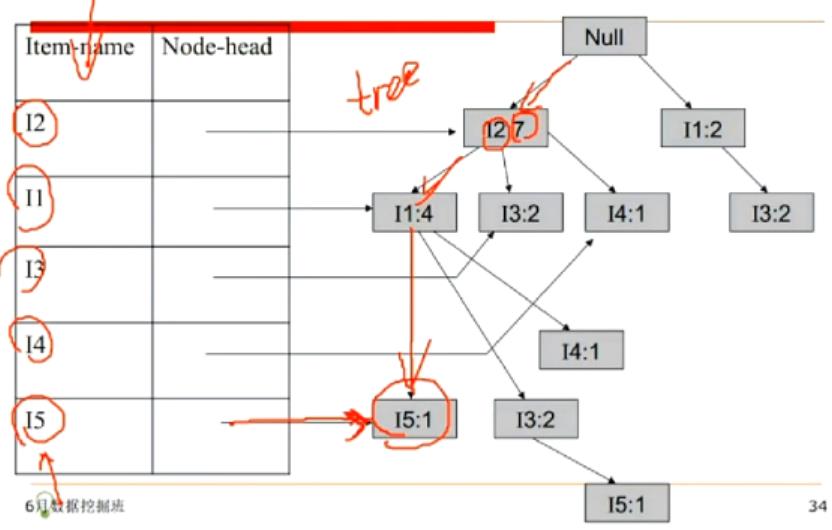
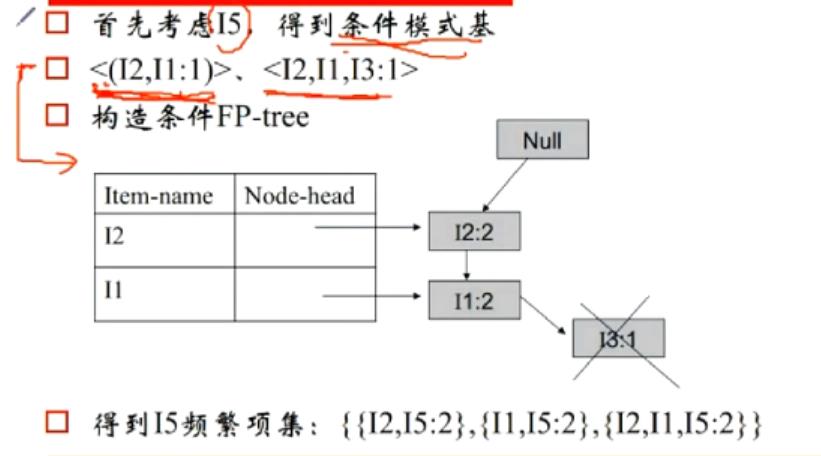
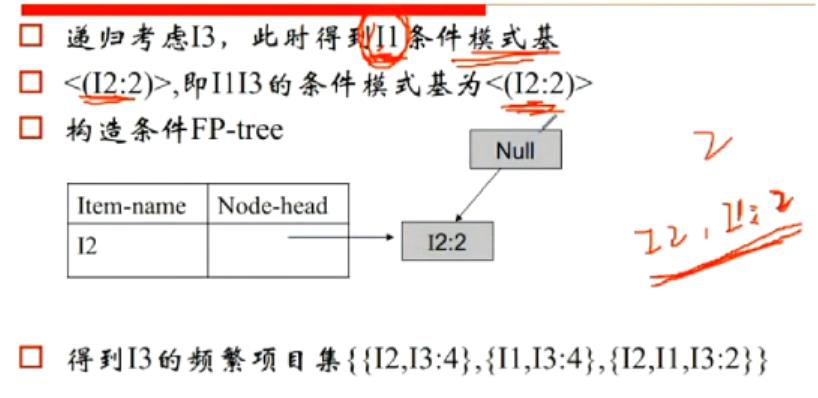
3.构造完成FP-Tree后,选定叶节点(就是满足最小支持度的那些字母,频繁1项),收集所有包含叶节点的前缀路径(条件模式基),从支持度最小的I5开始,比如下图中I5前缀路径有I2 I1和I2 I1 I3,根据I5的支持度,修正其前缀路径的支持度<I2,I1:1>,<I2,I1,I3:1>,得到两个条件模式基,接着再用这些条件模式基去建树。把每一个产生的条件模式基再看成一个database,再为新的database建fp-tree,删除不满足支持度的元素。对于不满足单一路径的树,略微负杂,需要递归的调用fp_tree。又要重新对树中的每一个节点建立条件模式基。

还有其他算法,比如Eclat
http://www.docin.com/p-1457838635.html
http://www.docin.com/p-1473280690.html
https://wenku.baidu.com/view/3a5cd6a17f1922791688e8c5.html
以上是关于关联规则的主要内容,如果未能解决你的问题,请参考以下文章