深度揭秘乱码问题背后的原因及解决方式
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度揭秘乱码问题背后的原因及解决方式相关的知识,希望对你有一定的参考价值。

做Web开发的IT人,如果工作中没遇到过几次乱码的问题,估计都不好意思说自己是开发工程师。 :)
而乱码问题也是各种各样,有保存到数据库中是乱码的,有在服务端接收到参数是乱码的,有在后台返回到客户端时候出现乱码的……
这形形色色的乱码问题,如果处理起来不得要领,着实会让开发人员费不少工夫。
本文,将从乱码的产生原因,应用服务器内部对参数的处理各方面详解原理及解决方案。
1
编码
在开发中,只要有IO的地方,都会涉及到编码。例如下面的代码:
System.out.println( "Hello 中国" );
你猜这个会输出什么呢?
这个其实是和你的文件编码有很大关系的,可能会输出
Hello 中国
也有可能会输出成下面这个样子
Hello ???
你可以改动IDE中的文件编码重复试几次。那为什么会产生这个原因呢?
我们来看这行代码执行过程中的调用栈:
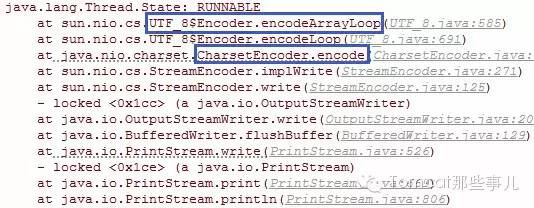
我们看到,简单的一句输出,也是有编码的。
看看CharsetEncoder,实现类真多啊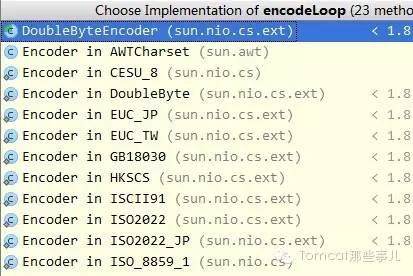
再比如我们都无比熟悉的equals方法,先声明常量STR如下:
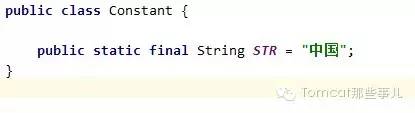
之后,代码中有如下的逻辑

你认为,这个时候会有输出吗?
答案是看情况!
当我把Constant类以UTF-8为编码保存后,把包含if逻辑的代码以GBK保存之后,equals执行时比较的两个参数就变成了下面的样子:
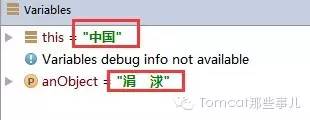
所以这一定是不会为true的。
这也是乱码产生的原因,
原因即解码时采用的encoding与编码时用的encoding不一致所造成的。
2
应用服务器内的乱码
在Web应用中,乱码的成因和上述分析是一致的。
我们向应用服务器发送一个这样的请求:
http://localhost:8080/test/servlet?abc=你好
服务器用request.getParameter("abc")来获取,这个时候有乱码问题吗?
答案依然是It depends.
这次的看情况是要看哪些情况呢?有以下这些。
-
Tomcat的版本
-
是否单独设置通道的编码
-
是否有使用统一的编码Filter
Tomcat默认对于不同的通道(Connector),都可以独立设置相关的编码属性,例如默认是下面这样的配置:
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
而我们可以增加自定义的编码配置:
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" URIEncoding="UTF-8"/>
红色的URIEncoding即为添加的属性,这个参数是和Tomcat的版本有关系的。
在Tomcat8中,其对应的官方文档是这样说明的:
This specifies the character encoding used to decode the URI bytes, after %xx decoding the URL. If not specified, UTF-8 will be used unless the
org.apache.catalina.STRICT_SERVLET_COMPLIANCEsystem property is set to
truein which case ISO-8859-1 will be used.
也就是不设置
-Dorg.apache.catalina.STRICT_SERVLET_COMPLIANCE=true
那默认的编码会采用UTF-8。
但是在Tomcat的8.0之前版本官方文档里是这样写的说明:
This specifies the character encoding used to decode the URI bytes, after %xx decoding the URL. If not specified, ISO-8859-1 will be used.
也就是不特殊指定,默认将使用ISO-8859-1进行编码。
看Connector的构造方法中,也是明确按此进行配置的
public Connector(String protocol) {
setProtocol(protocol);
...
//注意下面的代码
if (!Globals.STRICT_SERVLET_COMPLIANCE) {
URIEncoding = "UTF-8";
URIEncodingLower = URIEncoding.toLowerCase(Locale.ENGLISH);
}
}
这个配置又是如何作用于参数解析的呢?看下面
public void service(org.apache.coyote.Request req,
org.apache.coyote.Response res)
throws Exception {
// Set query string encoding
req.getParameters().setQueryStringEncoding
(connector.getURIEncoding()); //注意这里,具体去设置的是Parameters类的queryStringEncoding,这个属性会在后面解析URL中包含的参数时用到。}
public void setQueryStringEncoding( String s ) {
queryStringEncoding=s;}
而具体参数处理时,传进去的就是这个queryStringEncoding
processParameters( decodedQuery, queryStringEncoding );
这种情况,在Tomcat8中就不需要再显示的配置URIEncoding了,而之前的版本则需要配置。有上面的代码参照,我们看到,对于URL中传入的参数,除了设置URIEncoding这个配置之外,是没有办法保证的。因为其解析参数时使用的是queryStringEncoding这个参数,因此只有才保证传到Tomcat的参数编码和解码正确了。
而如果配置了统一的编码过滤器,则过滤器内设置request的编码一定要在解析参数前,即调用getParameter前设置,否则并不生效。这是因为parameter只会解析一次,之后就放到一个List中直接根据key返回了。
那是不是设置一个统一的编码Filter,一切就万事大吉了呢?
答案还是看情况吧?
恭喜,你会抢答啦!
3
JSP乱码问题
我们都知道在jsp中,可以设置这样一个jsp头
<%@ page contentType="text/html;charset=iso-8859-1" language="java" %>
那这个时候如果你的页面中要输出一些返回的中文数据,这个时候,页面妥妥的出现了乱码。原因自然是iso-859-1不支持中文有关。注意这里charset不写依然是按iso-8859-1为默认值。
这时,你想到了Filter。在Filter中你大胆的设置了
resp.setCharacterEncoding(encoding);
这个时候,页面展示却依然华丽的乱码了。擦,这是啥原因?
那这个时候,在jsp中显示数据的时候,依然还是会出现乱码的,此时注意观察下响应头:
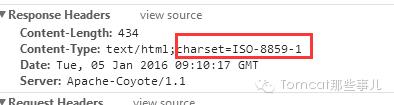
看下面的代码,由于response在输出的时候。会获取设置的encoding
/**
* Return the writer associated with this Response.
*
* @exception IllegalStateException if <code>getOutputStream</code> has
* already been called for this response
* @exception IOException if an input/output error occurs
*/
@Override
public PrintWriter getWriter()
throws IOException {
if (usingOutputStream) {
throw new IllegalStateException
(sm.getString("coyoteResponse.getWriter.ise"));
}
if (ENFORCE_ENCODING_IN_GET_WRITER) {
/*
* If the response‘s character encoding has not been specified as
* described in <code>getCharacterEncoding</code> (i.e., the method
* just returns the default value <code>ISO-8859-1</code>),
* <code>getWriter</code> updates it to <code>ISO-8859-1</code>
* (with the effect that a subsequent call to getContentType() will
* include a charset=ISO-8859-1 component which will also be
* reflected in the Content-Type response header, thereby satisfying
* the Servlet spec requirement that containers must communicate the
* character encoding used for the servlet response‘s writer to the
* client).
*/
setCharacterEncoding(getCharacterEncoding());
}
usingWriter = true;
outputBuffer.checkConverter();
if (writer == null) {
writer = new CoyoteWriter(outputBuffer);
}
return writer;
}
而这个encoding是什么设置的呢?
public void setContentType(String type) {
if (isCommitted()) {
return;
}
if (SecurityUtil.isPackageProtectionEnabled()){
AccessController.doPrivileged(new SetContentTypePrivilegedAction(type));
} else {
response.setContentType(type); //这里在设置contentType,由于配置中同时包含charset
}
}
String[] m = MEDIA_TYPE_CACHE.parse(type); //这个是在解析contentType参数
if (m == null) {
// Invalid - Assume no charset and just pass through whatever
// the user provided.
coyoteResponse.setContentTypeNoCharset(type);
return;
}
coyoteResponse.setContentTypeNoCharset(m[0]);
if (m[1] != null) {
// Ignore charset if getWriter() has already been called
if (!usingWriter) {
coyoteResponse.setCharacterEncoding(m[1]); //这里就用解析出来的参数设置。
isCharacterEncodingSet = true;
}
}
而我们一般为了处理这种乱码问题统一写的filter,在请求处理前就先把request和response的encoding都设置好。
而这里默认提供的charset为ISO-8859-1,就出了乱码问题了。另外一个在处理JSP时容易出的问题,就是contentType中指定的charset和filter中已经设置的encoding,两者不一致,比如你的jsp中忘记改了,使用的是默认的ISO-8859-1.此时,先通过filter设置的encoding会先于contentType的设置执行,因此,依然会出现乱码问题。
4
总结
在本文中,深入分析了乱码背后产生的原因:编码和解码时采用的encoding不一致。而解决问题的最朴素的道理就是保持多种数据来源编码的一致性,无论是数据库的,文件的,还是输入输出的,都采用一致的编码,可以简少很多问题。另外,许多文件中有一些默认编码,开发中可能不太注意,此处也是容易出现问题的地方。
以上是关于深度揭秘乱码问题背后的原因及解决方式的主要内容,如果未能解决你的问题,请参考以下文章
深度技术揭秘 | 大促狂欢背后,如何有效评估并规划数据库计算资源?