超标量技术
Posted _9_8
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了超标量技术相关的知识,希望对你有一定的参考价值。
超标量技术:核心,为了最大化指令的吞吐率,必须减少分支指令,ALU指令,load/store指令的开销。
超标量处理器可以是只并行化EX段的流水段。
可以具体细分为:1)指令流; 2)寄存器数据流; 3)存储器数据流;
指令流:一般用在超标量流水线的前端,即取指段和译码段。流水线机器只有在流水模式下才能达到最大的吞吐率,
对于无条件分支指令,分支地址确定后,下一条指令就能取出;
对于条件分支,只有在分支部件执行结束,条件和分支地址都确定后,取指段才能读取下一条指令。
可以具体细分为:生成目标地址的开销和条件判断引起的开销。超标量处理器的总开销等于停顿周期数和流水线宽度的乘积。
生成目标地址的开销还取决于分支指令的寻址模式,
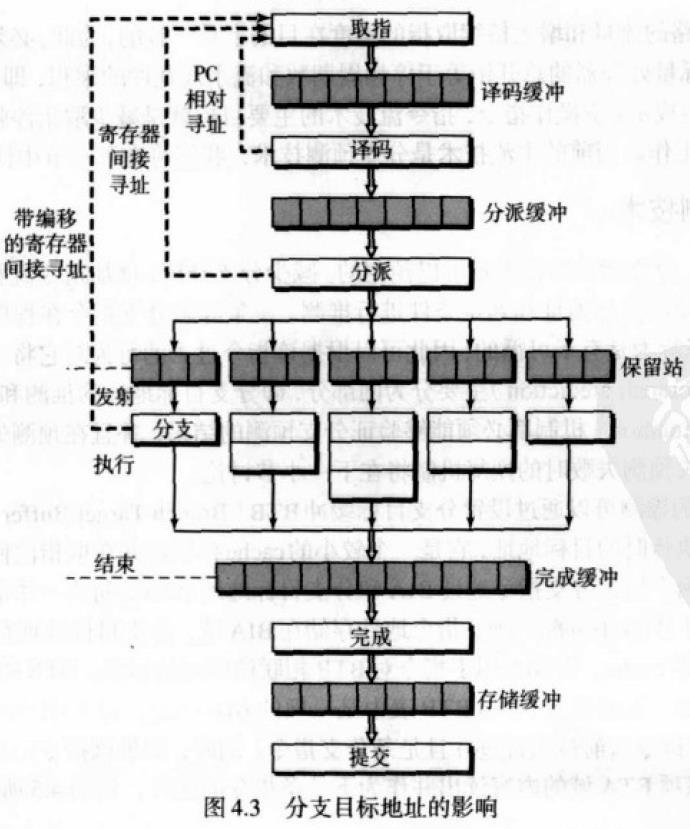
分支预测技术:对分支指令的目标地址和判定条件进行推测,任意一种推测机制都必须能够验证分支预测的结果,并且在预测失败时恢复正确的执行方式。
分支目标地址的推测通过设置分支目标缓冲BTB(Branch target Buffer)来实现,BTB用来保存前几次分支执行时的目标地址。包括两个域:
分支指令地址和分支目标地址
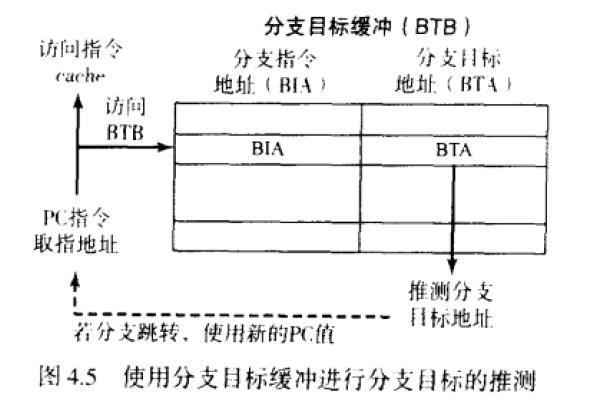
使用分支指令的地址访问BTB以及检索分支目标地址的工作都是在取指段执行的,若预测分支结果为跳转,则目标地址在下一个周期就被取指段使用。
虽然有了分支预测部件,分支指令还是要取出并送往流水线进行执行,以便确定预测是否正确,如果预测失败,恢复执行,需要更新BTB表中BTA的内容。
分支方向的预测中,最简单的方法是,总是预测为不跳转。对for循环不友好。
编译器优化,对不同的指令,设置静态的软件预测技术。不尽合理。
基于分支目标地址偏移的预测,相对偏移为正值,预测不跳转,相对偏移为负值,预测跳转。
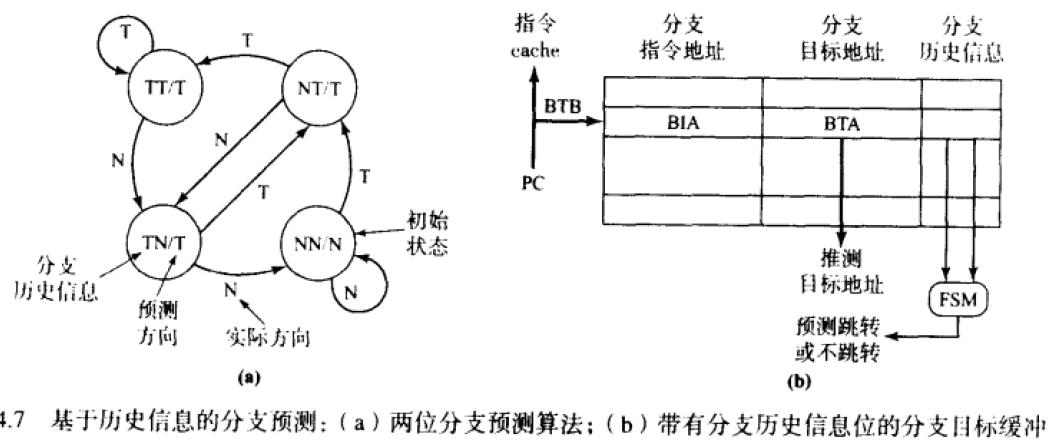
普遍采用的是基于历史信息的分支预测技术
采用基于历史信息的分支预测策略对分支方向进行预测时,跳转还是不跳转取决于先前已经发生的分支方向。BTB在每条记录中增加一个历史信息位。
历史信息位作为FSM的状态变量,FSM的输出逻辑即分支预测方向。
预测算法有很多,如只要最近分支有一次以上的跳转,就执行跳转,除非最近两次都没有跳转,才不跳转。这些的设计策略都需要进行评估。
分支预测失败的恢复:
分支验证在分支指令执行完毕,正确方向已经确定后进行,前端预测结果的正确与否在此时判定。
如果结果证明预测正确,释放推测标识,所有的相关指令都变为非推测的,继续执行。
如果预测失败,结束当前指令流并从新的地址取指。指令流的改变通过修改PC来实现。
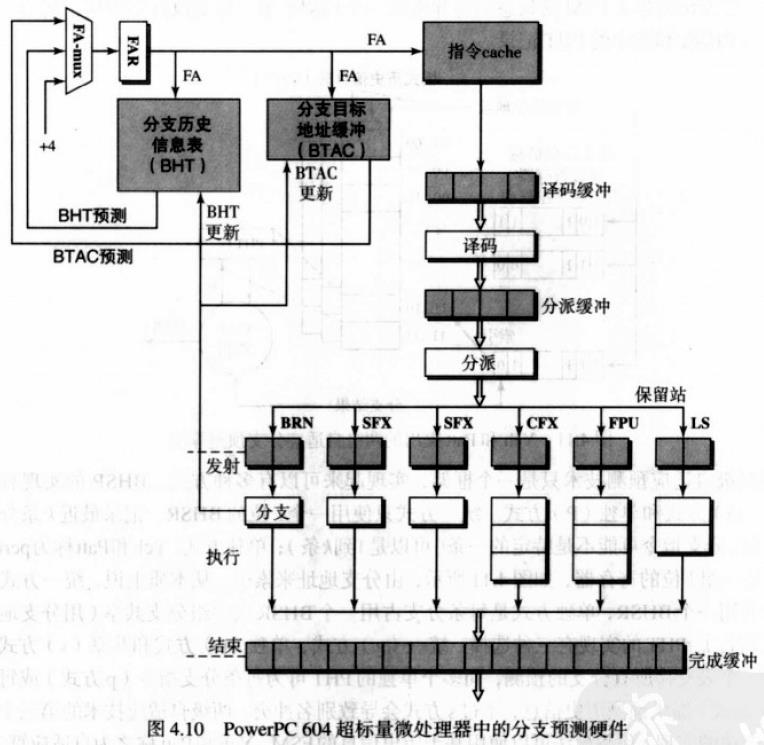
先进的分支预测技术
更精确的分支预测算法应该考虑其他关联分支指令的历史行为,从而动态的调整分支策略。之前的预测仅仅是静态方法。
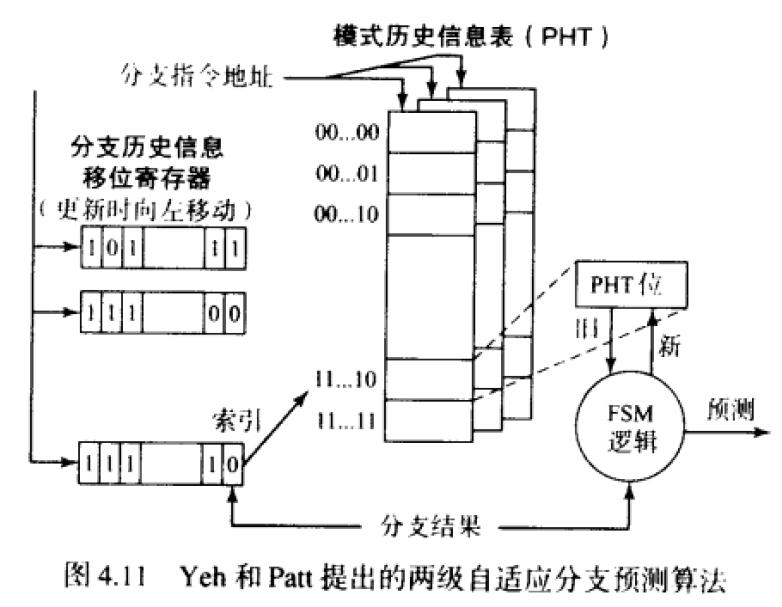
Yeh和Patt提出的两级自适应分支预测技术,分支地址索引一个分支历史信息集合,称为模式历史信息表(PHT)。
然后通过预测算法FSM,来输出预测结果。以及之后的关联分支预测器。
对于那些没有很强的倾向性的分支和分支序列,预测是十分困难的。
寄存器数据流技术:
寄存器数据流主要是指ALU指令的执行,涉及到的问题主要是数据相关性,正相关,反相关,输出相关。
数据的相关性主要是由于寄存器重用引起的,静态的寄存器重用是一种编译器的优化,
编译主要是代码生成和寄存器分配。代码生成,值机器代码的生成,寄存器分配,尽可能的保证中间数据驻留在寄存器中,
同时避免存储器和寄存器之间频繁的数据移动。
在超标量机器中,由于指令是可以乱序执行的,所以寄存器的读写操作,并不按照程序的原始顺序,为了保证语义的正确性,
所有的反相关和输出相关必须被检测并消除。
寄存器重命名,同一体系结构寄存器中的多个定义动态分配不同的名字,寄存器重命名需要硬件的支持,在执行时可以撤销寄存器重用,来恢复
所有当前命令的值与寄存器之间的一一对应的关系。
主要作用是可以用来消除假相关,使得本来可以假相关的指令可以并行的执行了。
寄存器数据流技术的特点在Tomasulo算法中,得到了很大的应用。
存储器数据流技术:
存储器数据流指令执行的三个步骤:生成存储器地址,存储器地址转换,数据访问,
存储器地址一般由一个寄存器和一个偏移量通过计算生成,因此地址生成包括寄存器访问和偏移量的计算。
load指令,地址寄存器就绪,就可发射,store指令,地址寄存器和数据寄存器都就绪后,发射。
虚拟地址到物理地址的转换,查表操作,一般通过访问快表TLB来完成,TLB是硬件控制的表结构,保存着虚拟地址到物理地址的
映射,本质上是存储器中页表的cache,
load指令,数据从数据存储器中检索出来并写入重命名寄存器或者再定序缓冲,
store命令,在地址转换结束后,要存储的寄存器数据保存在再定序缓冲中,store命令再提交时,再将数据写入存储器,
就CPU状态而言,在数据保存到存储缓冲之后,就已经完成,就存储器状态而言,在store提交之后,得到更新。
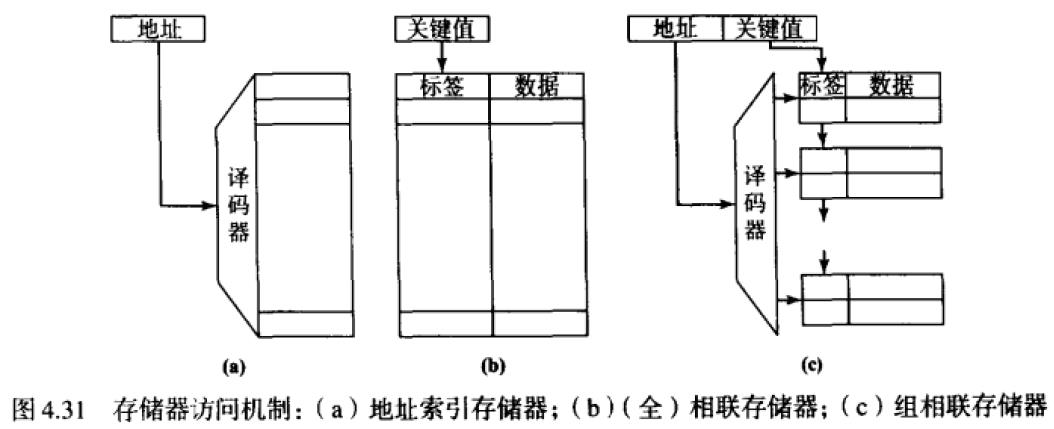
访问多端口存储器的两种基本方法:地址索引和标签相联查找。地址索引---不灵活但是实现简单,全相连---灵活但是实现复杂。
折中方案:组相连方案。
存储器的层次组织,为了使得整个存储系统达到高容量,地延时的目的。cache属于那种小而快的存储器。
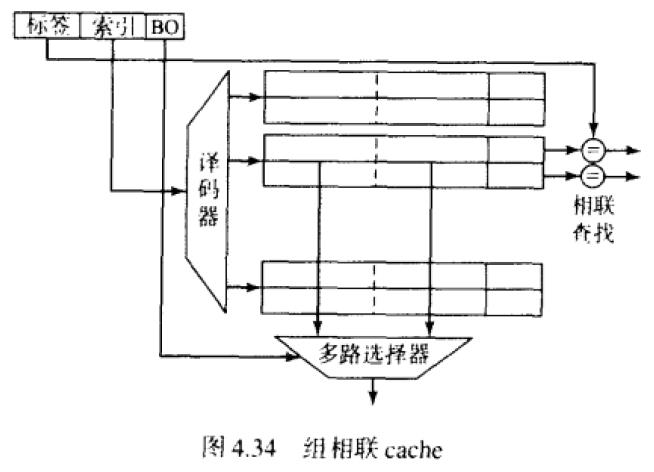
组相连的cache结构:标签,索引,块内地址
虚拟存储器要求,必须有一个虚拟地址到物理地址的转换,
1)颗粒度一般以页表(page table)为单位,以字为单位,表项太多。
2)由于页表也是保存在存储器中,所以每次访问存储器的操作,需要两次访存操作。
TLB就是对页表的缓存,也可以使用组相连的方式来实现。
以上是关于超标量技术的主要内容,如果未能解决你的问题,请参考以下文章