人脸检测—Retinanetface
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人脸检测—Retinanetface相关的知识,希望对你有一定的参考价值。
参考技术A 最近一直了解人脸检测的算法,所以也尝试学多人脸检测框架。所以这里将拿出来和大家分享一下Retinaface 与普通的目标检测算法类似,在图片上预先设定好一些先验框,这些先验框会分布在整个图片上,网络内部结构会对这些先验框进行判断看是否包含人脸,同时也会调整位置进行调整并且给每一个先验框的一个置信度。
在 Retinaface 的先验框不但要获得人脸位置,还需要获得每一个人脸的五个关键点位置
接下来我们对 Retinaface 执行过程其实就是在图片上预先设定好先验框,网络的预测结果会判断先验框内部是否包含人脸并且对先验框进行调整获得预测框和五个人脸关键点。
MobileNet 网络是由 google 团队在 2017 年提出的,专注移动端和嵌入式设备中轻量级 CNN 网络,在大大减少模型参数与运算量下,对于精度只是小幅度下降而已。
在主干网络输出的相当输出了不同大小网格,用于检测不同大小目标,先验框默认数量为 2,这些先验框用于检测目标,然后通过调整得到目标边界框。
深度可分离卷积好处就是可以减少参数数量,从而降低运算的成本。经常出现在一些轻量级的网络结构(这些网络结构适合于移动设备或者嵌入式设备),深度可分离卷积是由DW(depthwise)和PW(pointwise)组成
这里我们通过对比普通卷积神经网络来解释,深度可分离卷积是如何减少参数
我们先看图中 DW 部分,在这一个部分每一个卷积核通道数 1 ,每一个卷积核对应一个输入通道进行计算,那么可想而知输出通道数就与卷积核个数以及输入通道数量保持一致。
简单总结一下有以下两点
PW 卷积核核之前普通卷积核类似,只不过 PW 卷积核大小为 1 ,卷积核深度与输入通道数相同,而卷积核个数核输出通道数相同
普通卷积
深度可分离卷积
[计算机视觉]人脸应用:人脸检测人脸对比五官检测眨眼检测活体检测疲劳检测
人脸应用在计算机视觉体系中占很大一块,在深度学习火起来之前,基于传统机器学习的人脸应用就已经很成熟了,有很多商用应用场景。本文用一个可以实际运行的Demo来说明人脸应用中常见的技术概念,包含‘人脸检测’、‘人脸对比’、‘人脸表征检测(五官定位)’、‘眨眼检测’、‘活体检测’以及‘疲劳检测’。
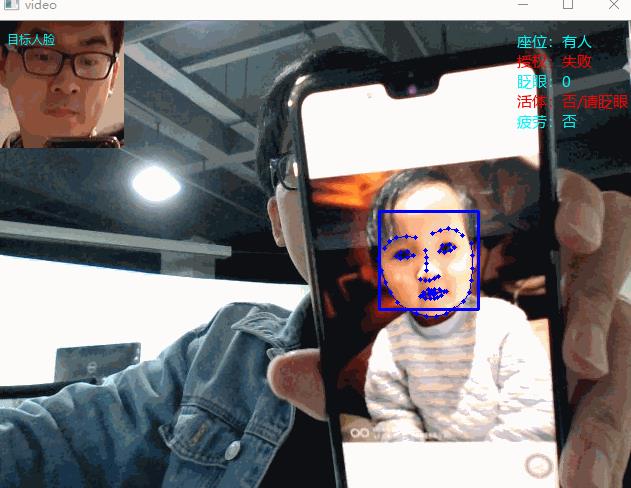
人脸检测
严格来讲,人脸检测只包含对照片中的人脸进行定位,人脸检测只获取照片中人脸的矩形方框(Left、Top、Right、Bottom),再没有其他的内容。现如今网上大部分“人脸检测”概念模糊,包含的东西很多,比如除了刚才说的定位,还包括后面要说的人脸对比,这个严格上讲是错的。

人脸对比
当你使用人脸检测技术发现图片(视频帧)中包含一个人脸,那么如何判断该人脸是谁呢?这个就是我们常见的人脸授权应用,将一个人脸与数据库的其他人脸进行对比,看它与数据库中已有人脸哪个最相似。传统机器学习中,人脸对比过程需要先提取人脸特征编码,寻找一个特征向量来代替原有人脸RGB图片,再通过计算两个人脸特征向量距离来判断人脸是否相似(传统机器学习中的特征工程可以参考上一篇文章)。如果距离小于某值,则认为是同一个人脸,反之亦然。
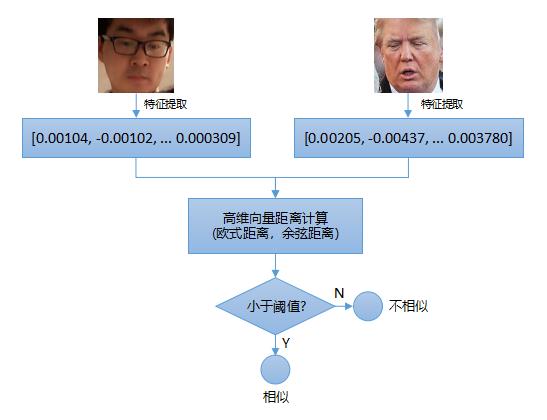
上图显示传统机器学习方法中人脸对比的过程,过程相对来说比较复杂,需要提取合适的特征向量,该特征对原RGB人脸图片有一定代表性。基于深度学习的方式去做人脸对比就相对来说简单很多,可以直接是一个端到端的流程:
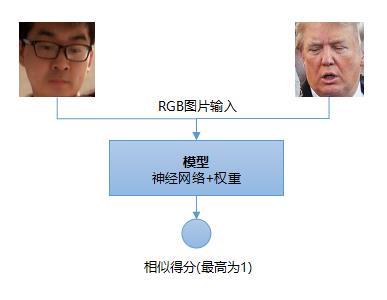
当然也有的做法是先通过神经网络提取人脸特征,然后再用传统机器学习的方式去训练类似SVM模型去做分类。
人脸表征检测(五官定位)
一般人脸应用使用前面说到的‘人脸检测’、‘人脸对比’两种技术就足够了,比如人脸打卡、人脸自动马赛克、人脸开锁等应用。但是更复杂的一些人脸应用只有人脸检测和对比是不够的,比如后面要说的活体检测、疲劳检测等场景。这些时候不仅要判断人脸的位置(矩形方框),还需要检测出人脸五官位置,比如眉毛形状、眼睛区域、鼻子位置、嘴巴位置等等,有了五官位置数据之后,我们就可以基于这些数据做一些更复杂的应用了,比如实时判断视频中的人是否眨眼、是否闭眼、是否说话、是否低头抬头等等。下图为人脸表征检测得到的结果:

上图显示通过机器学习提取到一张人脸表征的68个点,分别为:
(1)左眉毛5个点
(2)右眉毛5个点
(3)左眼睛6个点
(4)右眼睛6个点
(5)鼻梁4个点
(6)鼻尖5个点
(7)上嘴唇/下嘴唇20个点
(8)下巴17个点
我们可以通过下标(python中可以使用切片)快速获取对应的坐标点,该坐标点代表脸部表征在原输入图片中的实际位置(像素单位)。

眨眼检测
对视频每帧做人脸表征检测,得到视频每帧画面中人脸五官的位置数据后,我们可以通过分析人眼区域(六个点组成一个闭合的椭圆形)的闭合程度来判断是否发生眨眼,那么如何衡量每个眼睛的闭合程度呢?根据前人研究:http://vision.fe.uni-lj.si/cvww2016/proceedings/papers/05.pdf可知,通过每只眼的6个点即可判断眼睛的闭合程度:
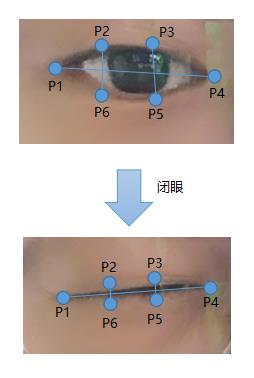
眼睛在打开到闭合时,下面这个表达式的值快速趋近于零:
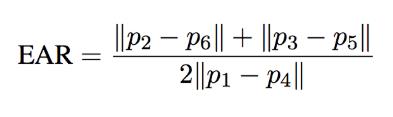
上面表达式EAR(Eye Aspect Ratio)的值等于垂直方向两个线段长度之和除以水平方向线段长度*2,这个值在闭眼的瞬间可以趋近于零,在睁眼的瞬间,恢复到原来值。EAR的变化过程如下图所示:

我们只需要监控EAR的值是否快速波动并且趋近于零来判断是否闭眼,是否快速恢复来判断是否睁眼。如果闭眼和睁眼时间间隔很短(只占几个视频帧,每秒25帧算),那么就认定为眨眼。
活体检测
人脸应用中,为了防止人们使用照片等伪造人脸通过授权,一般都需要对画面中的人脸进行活体过滤,即判断当前视频画面中的人脸是否是真人,而不是照片等其他代替物。通过前面介绍的眨眼检测技术,我们可以实现一个非常简单的‘活体检测’算法,算法每隔一个随机时间段(比如几秒,时间不固定,防止人们录制视频来伪造)就要求视频画面中的人眨眼,如果画面中的人积极配合算法发出的指令,那么可以认为画面中是真人,否则可能就是伪造人脸。

需要说明的是,活体检测仅仅通过以上这种方式可能还不是足够安全,一般还可以结合其他活体检测技术,比如相机深度检测、脸部光线检测、以及利用深度学习技术直接对人脸进行二分类(活体/非活体)。
疲劳检测
疲劳检测这个应用场景太大了,比如可以用于长途汽车司机疲劳监控告警、值班人员疲劳监控告警等。主要原理还是通过前面介绍的眨眼检测技术,将其稍微改进一下,我们就可以对闭眼进行检测,如果闭眼超过一段时间(比如1秒),那么就认为疲劳发生,发出告警。眨眼判断很简单,闭眼判断更简单,这些所有的判断逻辑全部基于人脸表征提取的数据:

需要明确的是,本文所有算法的准确性全部依赖于模型训练的好坏,人脸检测是否准确、人脸特征提取是否合适、人脸表征检测结果是否准确。机器学习就是这样,结果的好坏完全取决于模型训练的好坏(特征提取的好坏)。比如本文这个demo中可以容易看到,人脸表征检测对戴眼镜的人脸效果不是很好,需要更多这方面的训练数据。有问题的朋友请留言,感兴趣的朋友请关注公众号,分享原创CV/DL相关文章。
以上是关于人脸检测—Retinanetface的主要内容,如果未能解决你的问题,请参考以下文章
行人检测和人脸检测和人脸关键点检测(C++/Android源码)
opencv中检测出人脸之后,需要把检测出的人脸区域提取出来,用作人脸识别,那么如何提取人脸区域