计算机体系架构
Posted _9_8
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计算机体系架构相关的知识,希望对你有一定的参考价值。
两种架构:
体系结构:是指指令集体系结构。
微体系结构:是指体系结构的具体逻辑实现,不同的微体系结构有不同的流水线设计,不同的分支预测技术。
微体系结构的多样性使得同一种体系结构能够不断的推陈出新,提高微处理器的性能,同时保证代码的兼容性。
预定义的指令集也叫做指令集体系结构(ISA,Instruction Set Architecture)。
ISA是软件与硬件之间的接口,程序与处理器之间的接口。
ISA是设计的规范,微处理器是设计的实现。
指令集体系结构(ISA)作为软件与硬件,程序与处理器之间的一种约定,起着十分重要的作用。使得程序与机器之间可以独立的发展。
ISA通常要定义一套汇编指令,每一条指令都指定一种操作类型和多个操作数,早期的ISA将操作数放在一个栈结构中,在栈顶操作。
现代多数的ISA将操作数放在多端口的寄存器文件中。
相较于微体系结构,ISA架构为了匹配编译器和操作系统,一般不会有太大改变。微体系结构每3-5年就会有较大的发展。
CISC的代表,intel和amd的X86,RISC的代表,IBM(power pc),ARM,MIPS
IA-32和X86-32是intel的32位架构,X86-64是AMD开发的针对IA-32的扩展64位架构,IA-64是intel提出的全新的64位架构。
X86表示的是一套向后兼容的指令集,包括32bit,16bit,X86是intel授权给amd,X86-64是amd授权给intel,交叉授权。
X86最初是由intel提出的,在intel接到ibm的订单后,由于产能限制和ibm的供应链担忧,ibm要求intel将X86的指令授权给了amd和cyrix,
之后amd通过交叉授权解决了和intel的专利问题,cyrix则被via收购,但是仍然只有X86的使用权,之后兆芯收购via,但是并没有X86的
授权,只有via控股大于兆芯,才有X86的使用权。
冯诺依曼体系结构,不区分数据和指令,指令的地址线,数据线与数据的地址线,数据线,分时复用。
哈佛体系结构,指令存储和数据存储分开,每个存储器独立编码,独立访问。共有四组数据总线。
改进型的哈佛体系结构,指令与数据共享同一个地址空间,但是缓存是分开的。
哈佛体系结构相较于冯诺依曼,主要解决了程序运行时的瓶颈问题, 冯诺依曼体系结构,流水线中的取指令,取数据,无法并行,
其他的思想并没有变,指令由操作码(指明操作类型),地址(指明数据)组成,都按二进制的格式存在存储器中。
冯诺依曼结构多应用在计算机早期,实现简单,成本低。但是支持动态程序。
哈佛结构,较复杂,对外围设备的连接和处理要求高,外围存储器的扩展性不高。
目前的计算机,多是cpu内部使用哈佛结构,外部使用冯诺依曼结构。即改进型哈佛结构
超线程技术:CPU在执行单线程任务时,并不是核心的每个单元都在工作,超线程技术就是让这些闲置的执行单元去做另一个线程的工作。
但是当他们需要同一个特定的执行单元的时候,就没无法同时执行了,
intel的超线程技术,一般是一核两线程,IBM的power7有8核32线程,power8有12核96线程。
该技术的瓶颈并不在计算单元,而在调度单元随着超线程的增加,负担太大。
高端微处理器设计的步骤:
1):微体系结构设计,为获得预期的性能而对关键技术进行的研究和确定,通常用一个性能模型来进行评估。规定处理器的功能性行为。
性能模型,在时钟周期的颗粒度上,模拟处理器的行为,计算执行一个测试程序(benchmark)所需要的时钟周期数目。
2):逻辑设计,通过RTL的verilog代码描述,设计实现内部主要的模块以及模块之间的互联。
ISA中还有一个内在的接口定义,区别哪些是编译时静态完成的,哪些是运行时动态完成的程序。

所有在编译时由软件和编译器静态完成的任务和优化,被认为是DSI之上的。
所有在运行时,由硬件动态完成的任务和优化,被认为是DSI之下的。
处于DSI之上的软件和DSI之下的硬件是相互独立的。
处理器的性能法则:
处理器性能是依据执行一段特殊代码所需要的时间来衡量的,可以分为三大类:
1):程序需要的指令数;
2):每条指令的时钟数(Cycles Per Instruction)
3):每个时钟周期需要的时间;
处理器的性能优化:
1):编译器优化,减少不必要的冗余代码,从而减少指令数;
2):使用更为先进的工艺,减少信号传输延时,减小机器时钟周期;
3):增加复杂指令,来减少指令数,但是增加执行部件复杂性,增加指令的时钟数;
4):深度流水线来减小每条指令的时钟数(CPI),但是分支预测出错会使得CPI变大;
目前主要的提升性能的方式还是减小CPI,两种方法:
1):使用RISC,但是指令数目增加;
2):增加指令流水;
指令级并行处理(ILP):
指令级并行可以定义为多条指令的并行执行,
传统的串行处理器每次只执行一条指令。
流水线处理器可以重叠执行多条指令,实现指令级并行。
传统的CISC处理器每处理一条指令,需要10个机器周期,CPI=10
流水线处理器(RISC),通过多条指令的重叠执行,将平均CPI降低到接近1。
标量流水线处理器,在每个周期最多只能发射一条指令。吞吐量在最好状态,CPI等于1。
超标量流水线处理器,每个周期可以进行多条指令的发射,CPI可以小于1。
标量处理器是一种最简单的计算机处理器类型,在同一时间内只处理一条数据,标量处理器是一种单指令单数据流(SISD)处理器。
分为复杂指令集CISC(Complex Instruction Set Computing),对编译器设计要求不高,但是芯片设计复杂,耗电量大。(X86)
精简指令集RISC(Reduced Instruction Set Computing),需要强大的编译器使得多个部件并行执行,采用流水线pipeline,
指令乱序out-oder instruction来发挥CPU性能。(包括MIPS/PowerPC/ARM)
向量处理器,也称为阵列处理器,在科学计算领域应用广泛。多数商业CPU都包括一些向量处理器指令,如SIMD。
向量处理器早于ILP处理器而商业化,采用一种不同的策略来控制多个深度流水的功能部件,典型的向量操作是两个64位浮点数据相加得到新的64位的元素向量。
每条向量指令等同于一个循环,可以执行上百次操作,向量间的各个元素计算相互独立。
标量并行处理器的性能建模:(每个计算中,只有一个处理器处于使用状态),(由向量处理器和标量处理器组成)
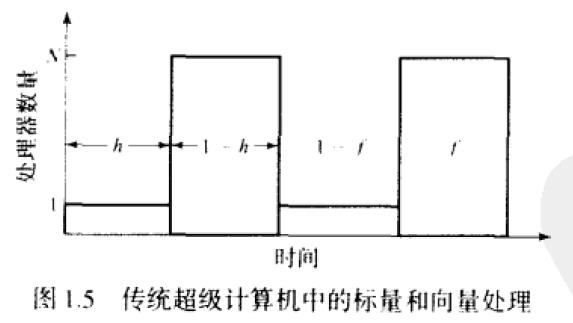
Amdahl定律的效率公式:E = 1-h+h/N,N是机器中处理器的数量,h为进行标量运算的时间片。当h从100%稍微下降一点时,流水线处理器的性能下降的很厉害。
并行处理器的性能模型可以用于流水线处理器,机器并行度N代表流水线的深度,执行过程分为流水线填充阶段,完全流水阶段,流水线排空阶段。

假设流水线一旦停顿,流水线中只存在一条指令,相当于流水线暂停N个时钟,模型可以简化为:
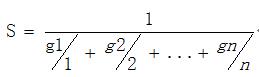
其中gi表示流水线中有i条指令的时间片,即流水线停顿(N-i)个周期的时间片。
指令级并行相对于其他的程序段和计算任务的同时处理,称为”细粒度并行”,为开发ILP设计的处理器称为ILP处理器。
ILP处理器可以根据一些列参数进行分类:
1):操作延时(OL),指令执行需要的机器时钟周期数。
2):机器并行度(MP),能够同时在流水线中运行的最大指令数。
3):发射延迟(IL),一条新的指令初始化后进入流水线。
4):发射并行度(IP),每个时钟周期内可以发射的最大指令数。
对于4级流水的基准的标量流水线处理器,相对于标量的非流水处理器,流水线处理器获得了更高的吞吐率。
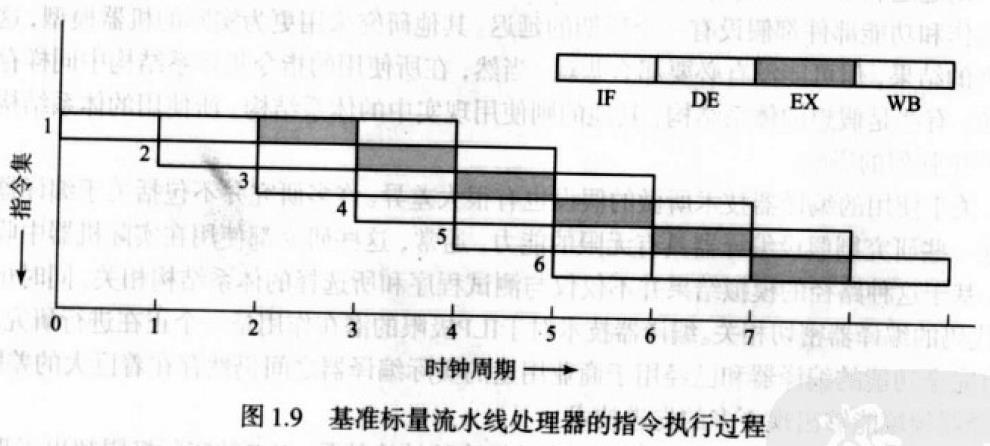
超流水处理器比基准处理器有着更高的流水度,在超流水处理器中,处理器的时钟周期比基准处理器短,并定义为“次时钟周期“,
一个基准处理器的时钟周期中有m个次时钟周期。

超流水处理器发射指令的速度比执行的速度要快,每个次时钟都会发射指令,但是一条指令的执行可能需要m个次时钟。
从技术上来看,如果传统流水线处理器需要多个时钟来执行简单指令,那应当归类为超流水处理器。
超流水处理器可以被看作m*k段的深度流水线处理器,某条指令的结果不能被后续的m-1条指令利用。
超标量处理器是基准标量流水线处理器的扩展,IP=n条指令/时钟周期,流水线深度n*k,具有相同深度的超流水处理器和超标量处理器具有同样的并行度。

超标量也可以超流水,并行度进一步提高:MP=n*m*k
以上是关于计算机体系架构的主要内容,如果未能解决你的问题,请参考以下文章
[架构之路-119]-《软考-系统架构设计师》-计算机体系结构 -1- 基本原理(体系结构指令系统与流水线层次存储)
[架构之路-120]-《软考-系统架构设计师》-计算机体系结构 -2- 一文了解ARM SOC体系结构原理(CPU工作原理指令内存中断堆栈IO初始化)