caffe-mnist别手写数字
Posted 北海盗
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了caffe-mnist别手写数字相关的知识,希望对你有一定的参考价值。
【来自:http://www.cnblogs.com/denny402/p/5685909.html】
整个工作目录建在:/home/ubunt16041/caffe/examples/abc_mnist/
再建一个mnist目录,所有的都放在mnist目录下。
(/home/ubuntu16041/caffe/examples/abc_mnist/mnist/)
图片下载好,test.txt,train.txt都有了。
mnist.py用来生成训练需要的文件:
# -*- coding: utf-8 -*-
import caffe
from caffe import layers as L,params as P,proto,to_proto
#设定文件的保存路径
root=\'/home/ubuntu16041/caffe/examples/abc_mnist/\' #根目录
train_list=root+\'mnist/train/train.txt\' #训练图片列表
test_list=root+\'mnist/test/test.txt\' #测试图片列表
train_proto=root+\'mnist/train.prototxt\' #训练配置文件
test_proto=root+\'mnist/test.prototxt\' #测试配置文件
solver_proto=root+\'mnist/solver.prototxt\' #参数文件
#编写一个函数,生成配置文件prototxt
def Lenet(img_list,batch_size,include_acc=False):
#第一层,数据输入层,以ImageData格式输入
data, label = L.ImageData(source=img_list, batch_size=batch_size, ntop=2,root_folder=root,
transform_param=dict(scale= 0.00390625))
#第二层:卷积层
conv1=L.Convolution(data, kernel_size=5, stride=1,num_output=20, pad=0,weight_filler=dict(type=\'xavier\'))
#池化层
pool1=L.Pooling(conv1, pool=P.Pooling.MAX, kernel_size=2, stride=2)
#卷积层
conv2=L.Convolution(pool1, kernel_size=5, stride=1,num_output=50, pad=0,weight_filler=dict(type=\'xavier\'))
#池化层
pool2=L.Pooling(conv2, pool=P.Pooling.MAX, kernel_size=2, stride=2)
#全连接层
fc3=L.InnerProduct(pool2, num_output=500,weight_filler=dict(type=\'xavier\'))
#激活函数层
relu3=L.ReLU(fc3, in_place=True)
#全连接层
fc4 = L.InnerProduct(relu3, num_output=10,weight_filler=dict(type=\'xavier\'))
#softmax层
loss = L.SoftmaxWithLoss(fc4, label)
if include_acc: # test阶段需要有accuracy层
acc = L.Accuracy(fc4, label)
return to_proto(loss, acc)
else:
return to_proto(loss)
def write_net():
#写入train.prototxt
with open(train_proto, \'w\') as f:
f.write(str(Lenet(train_list,batch_size=64)))
#写入test.prototxt
with open(test_proto, \'w\') as f:
f.write(str(Lenet(test_list,batch_size=100, include_acc=True)))
#编写一个函数,生成参数文件
def gen_solver(solver_file,train_net,test_net):
s=proto.caffe_pb2.SolverParameter()
s.train_net =train_net
s.test_net.append(test_net)
s.test_interval = 938 #60000/64,测试间隔参数:训练完一次所有的图片,进行一次测试
s.test_iter.append(500) #50000/100 测试迭代次数,需要迭代500次,才完成一次所有数据的测试
s.max_iter = 9380 #10 epochs , 938*10,最大训练次数
s.base_lr = 0.01 #基础学习率
s.momentum = 0.9 #动量
s.weight_decay = 5e-4 #权值衰减项
s.lr_policy = \'step\' #学习率变化规则
s.stepsize=3000 #学习率变化频率
s.gamma = 0.1 #学习率变化指数
s.display = 20 #屏幕显示间隔
s.snapshot = 938 #保存caffemodel的间隔
s.snapshot_prefix = root+\'mnist/lenet\' #caffemodel前缀
s.type =\'SGD\' #优化算法
s.solver_mode = proto.caffe_pb2.SolverParameter.CPU #加速
#写入solver.prototxt
with open(solver_file, \'w\') as f:
f.write(str(s))
#开始训练
def training(solver_proto):
solver = caffe.SGDSolver(solver_proto)
solver.solve()
#
if __name__ == \'__main__\':
write_net()
gen_solver(solver_proto,train_proto,test_proto)
training(solver_proto)
运行:python mnist.py
接下来就是生成deploy.prototxt文件:
deploy.py
# -*- coding: utf-8 -*-
from caffe import layers as L,params as P,to_proto
root=\'/home/ubuntu16041/caffe/examples/abc_mnist/\'
deploy=root+\'mnist/deploy.prototxt\' #文件保存路径
def create_deploy():
#少了第一层,data层
conv1=L.Convolution(bottom=\'data\', kernel_size=5, stride=1,num_output=20, pad=0,weight_filler=dict(type=\'xavier\'))
pool1=L.Pooling(conv1, pool=P.Pooling.MAX, kernel_size=2, stride=2)
conv2=L.Convolution(pool1, kernel_size=5, stride=1,num_output=50, pad=0,weight_filler=dict(type=\'xavier\'))
pool2=L.Pooling(conv2, pool=P.Pooling.MAX, kernel_size=2, stride=2)
fc3=L.InnerProduct(pool2, num_output=500,weight_filler=dict(type=\'xavier\'))
relu3=L.ReLU(fc3, in_place=True)
fc4 = L.InnerProduct(relu3, num_output=10,weight_filler=dict(type=\'xavier\'))
#最后没有accuracy层,但有一个Softmax层
prob=L.Softmax(fc4)
return to_proto(prob)
def write_deploy():
with open(deploy, \'w\') as f:
f.write(\'name:"Lenet"\\n\')
f.write(\'input:"data"\\n\')
f.write(\'input_dim:1\\n\')
f.write(\'input_dim:3\\n\')
f.write(\'input_dim:28\\n\')
f.write(\'input_dim:28\\n\')
f.write(str(create_deploy()))
if __name__ == \'__main__\':
write_deploy()
照样运行,就可以生成了。
最后就是测试:test.py


1 #coding=utf-8 2 3 import caffe 4 import numpy as np 5 root=\'/home/ubuntu16041/caffe/examples/abc_mnist/\' #根目录 6 deploy=root + \'mnist/deploy.prototxt\' #deploy文件 7 caffe_model=root + \'mnist/lenet_iter_9380.caffemodel\' #训练好的 caffemodel 8 img=root+\'mnist/test/8/00061.png\' #随机找的一张待测图片 9 labels_filename = root + \'mnist/test/labels.txt\' #类别名称文件,将数字标签转换回类别名称 10 11 net = caffe.Net(deploy,caffe_model,caffe.TEST) #加载model和network 12 13 #图片预处理设置 14 transformer = caffe.io.Transformer({\'data\': net.blobs[\'data\'].data.shape}) #设定图片的shape格式(1,3,28,28) 15 transformer.set_transpose(\'data\', (2,0,1)) #改变维度的顺序,由原始图片(28,28,3)变为(3,28,28) 16 #transformer.set_mean(\'data\', np.load(mean_file).mean(1).mean(1)) #减去均值,前面训练模型时没有减均值,这儿就不用 17 transformer.set_raw_scale(\'data\', 255) # 缩放到【0,255】之间 18 transformer.set_channel_swap(\'data\', (2,1,0)) #交换通道,将图片由RGB变为BGR 19 20 im=caffe.io.load_image(img) #加载图片 21 net.blobs[\'data\'].data[...] = transformer.preprocess(\'data\',im) #执行上面设置的图片预处理操作,并将图片载入到blob中 22 23 #执行测试 24 out = net.forward() 25 26 labels = np.loadtxt(labels_filename, str, delimiter=\'\\t\') #读取类别名称文件 27 prob= net.blobs[\'Softmax1\'].data[0].flatten() #取出最后一层(Softmax)属于某个类别的概率值,并打印 28 print prob 29 order=prob.argsort()[-1] #将概率值排序,取出最大值所在的序号 30 print \'the class is:\',labels[order] #将该序号转换成对应的类别名称,并打印
至此,完成对某个手写字的识别。要想识别另外的手写字,就在test.py里面改!
-----
显示曲线效果的:【http://www.cnblogs.com/denny402/p/5686067.html】
look.py
1 # -*- coding: utf-8 -*- 2 """ 3 Created on Tue Jul 19 16:22:22 2016 4 5 @author: root 6 """ 7 8 import numpy as np 9 import matplotlib.pyplot as plt 10 import caffe 11 12 #caffe.set_device(0) 13 #caffe.set_mode_gpu() 14 15 # 使用SGDSolver,即随机梯度下降算法 16 solver = caffe.SGDSolver(\'/home/ubuntu16041/caffe/examples/abc_mnist/mnist/solver.prototxt\') 17 18 # 等价于solver文件中的max_iter,即最大解算次数 19 niter = 9380 20 # 每隔100次收集一次数据 21 display= 100 22 23 # 每次测试进行100次解算,10000/100 24 test_iter = 100 25 # 每500次训练进行一次测试(100次解算),60000/64 26 test_interval =938 27 28 #初始化 29 train_loss = np.zeros(np.ceil(niter * 1.0 / display)) 30 test_loss = np.zeros(np.ceil(niter * 1.0 / test_interval)) 31 test_acc = np.zeros(np.ceil(niter * 1.0 / test_interval)) 32 33 # iteration 0,不计入 34 solver.step(1) 35 36 # 辅助变量 37 _train_loss = 0; _test_loss = 0; _accuracy = 0 38 # 进行解算 39 for it in range(niter): 40 # 进行一次解算 41 solver.step(1) 42 # 每迭代一次,训练batch_size张图片 43 _train_loss += solver.net.blobs[\'SoftmaxWithLoss1\'].data 44 if it % display == 0: 45 # 计算平均train loss 46 train_loss[it // display] = _train_loss / display 47 _train_loss = 0 48 49 if it % test_interval == 0: 50 for test_it in range(test_iter): 51 # 进行一次测试 52 solver.test_nets[0].forward() 53 # 计算test loss 54 _test_loss += solver.test_nets[0].blobs[\'SoftmaxWithLoss1\'].data 55 # 计算test accuracy 56 _accuracy += solver.test_nets[0].blobs[\'Accuracy1\'].data 57 # 计算平均test loss 58 test_loss[it / test_interval] = _test_loss / test_iter 59 # 计算平均test accuracy 60 test_acc[it / test_interval] = _accuracy / test_iter 61 _test_loss = 0 62 _accuracy = 0 63 64 # 绘制train loss、test loss和accuracy曲线 65 print \'\\nplot the train loss and test accuracy\\n\' 66 _, ax1 = plt.subplots() 67 ax2 = ax1.twinx() 68 69 # train loss -> 绿色 70 ax1.plot(display * np.arange(len(train_loss)), train_loss, \'g\') 71 # test loss -> 黄色 72 ax1.plot(test_interval * np.arange(len(test_loss)), test_loss, \'y\') 73 # test accuracy -> 红色 74 ax2.plot(test_interval * np.arange(len(test_acc)), test_acc, \'r\') 75 76 ax1.set_xlabel(\'iteration\') 77 ax1.set_ylabel(\'loss\') 78 ax2.set_ylabel(\'accuracy\') 79 plt.show()
就会出现一个:
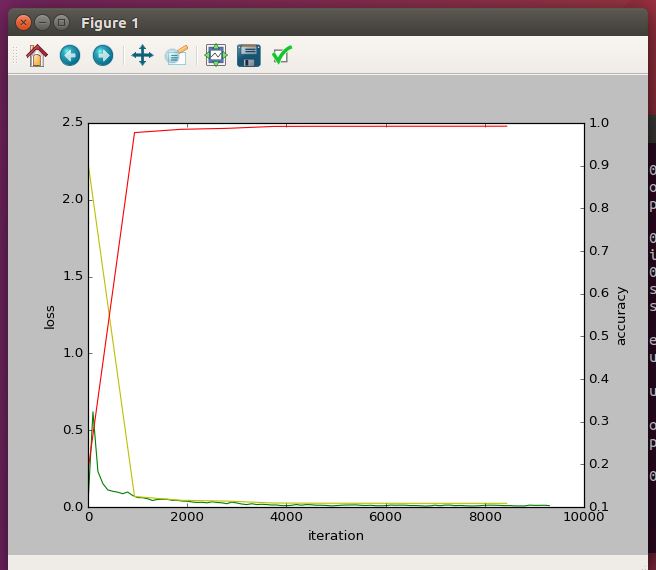
ok,接下来就要读读代码啦,今天我叫搬运工:)。。。
【windows可以参考这个:http://blog.csdn.net/zb1165048017/article/details/52217772
http://www.cnblogs.com/yixuan-xu/p/5862657.html
】
以上是关于caffe-mnist别手写数字的主要内容,如果未能解决你的问题,请参考以下文章