Hession反序列化导致CPU占用飙高
Posted 他山之石头
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hession反序列化导致CPU占用飙高相关的知识,希望对你有一定的参考价值。
背景
今天发布一个线上服务,暂且称之为O,发布完后,依赖O服务的2个服务C和W大量Time报警,并且这两个服务的CPU占用都飙到了40%左右,平时只有10%的样子。
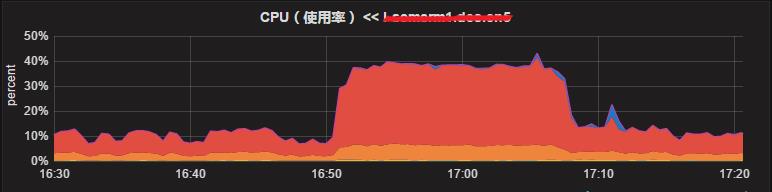
这时去看O服务的监控,Time并没有升高,QPS反倒降了一半。同时C和W服务器日志中出现了大量的WARNING,信息如下:
java.lang.ClassNotFoundException: com.我是不可描述的信息.PropertyAo
Dec 02, 2016 6:24:33 PM com.alibaba.com.caucho.hessian.io.SerializerFactory getDeserializer
WARNING: Hessian/Burlap: 'com.我是不可描述的信息.PropertyAo' is an unknown class in WebappClassLoader
context:
delegate: false
repositories:
/WEB-INF/classes/
----------> Parent Classloader:
org.apache.catalina.loader.StandardClassLoader@21bf4c80短时间内找不到原因,且C服务是核心服务,找QA童鞋把O服务回滚,C和W报警恢复,CPU占用回到正常。
定位
可能见过这个WARNING的朋友已经知道了我这次发布干了啥,其实就是在API返回的模型中增加了两个自定义类型的属性,如下:
private List<PropertyAo> properties1;
private List<PropertyAo> properties2;这两个属性W中会用到,之所以会有上面提到的WARNING,是由于我先发布了O服务,O服务中设置了这两个属性,而W服务还没有发布,这样Hession在反序列化的时候,检测到了PropertyAo不存在,所以给出了WARNING。但这与CPU飙高有关系吗?
与同事讨论了一番,他提到了Hession反序列化时会使用到反射,他之前遇到过CPU占用飙高的情况(是由于反射代码被大量调用),这点提醒了我,顺着com.alibaba.com.caucho.hessian.io.SerializerFactory getDeserializer这个方法看到了这样的实现:
try {
Class cl = Class.forName(type, false, _loader);
deserializer = getDeserializer(cl);
} catch (Exception e) {
log.warning("Hessian/Burlap: '" + type + "' is an unknown class in " + _loader + ":\\n" + e);
log.log(Level.FINER, e.toString(), e);
}可以看到Hession是通过名字去拿到Class,这里使用了反射,当反射失败时就会打出上面的warning。这时聪明的你可能想到了,即使没有失败也是在使用反射啊,继续向下看代码:
if (deserializer != null) {
if (_cachedTypeDeserializerMap == null)
_cachedTypeDeserializerMap = new HashMap(8);
synchronized (_cachedTypeDeserializerMap) {
_cachedTypeDeserializerMap.put(type, deserializer);
}
}反射成功就会将其cache起来,也就是说,如果反射成功,只会调用一次反射,反射失败,则每次都会执行反射。
验证
先将C升级到最新api,然后发布,再发布O服务,C表现正常,W的CPU又开始飙高,执行jstack看一下事故现场,可以看到一些线程正在执行反射,栈信息如下:
"New I/O worker #17" daemon prio=10 tid=0x00007fb1ed33b000 nid=0x63fe runnable [0x00007fb22fcfa000]
java.lang.Thread.State: RUNNABLE
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:270)
at com.alibaba.com.caucho.hessian.io.SerializerFactory.getDeserializer(SerializerFactory.java:500)解决
- 当服务端模型升级时,尤其是新增自定义类型时,尽量让所有消费端升级,但当消费端过多时,这个方案成本太高,且不友好
- 改进SerializerFactory,把反射失败的情况也缓存,避免重复反射,已推动公司内部解决
- 给Dubbo提了issue,不过估计不会解决
结论
Hession默认的反序列化实现满足下面2点条件时,就会导致CPU占用飙高:
- 服务端新增了自定义类型
- 对该服务接口的调用QPS较高,我的应用中是100+
其本质原因还是由于反射,所以开发过程中慎用反射,反射得到的信息尽量Cache,避免频繁反射。
本文来自:高爽|Coder,原文地址:http://blog.csdn.net/ghsau/article/details/53414694,转载请注明。
以上是关于Hession反序列化导致CPU占用飙高的主要内容,如果未能解决你的问题,请参考以下文章