读高性能JavaScript编程 第二章 让我知道了代码为什么要这样写
Posted 皖苏
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了读高性能JavaScript编程 第二章 让我知道了代码为什么要这样写相关的知识,希望对你有一定的参考价值。
代码为什么要这样写?
function initUI(){
var doc = document,
bd = doc.body,
links = doc.getElementsByTagName_r("a"),
i = 0,
len = links.length;
while(i < len){
update(links[i++]);
}
doc.getElementById("go-btn").onclick = function(){
start();
};
bd.className = "active";
}
而不这样?
//avoid
function initUI(){ var bd = document.body, links = document.getElementsByTagName_r("a"), i = 0, len = links.length; while(i < len){ update(links[i++]); } document.getElementById("go-btn").onclick = function(){ start(); }; bd.className = "active"; }
很明显 我们都知道第一个提取了局部变量doc保存document对象所以性能要比第二个好,为什么呢?
首先要了解 js引擎的四种Data Access (数据访问)。
1、访问 Literal values 直接量 eg:字符串,数字,布尔值,对象,数组,函数,正则表达式,具有特殊意义的空值,以及未定义。
2、访问 Variables 变量 var创建用于存储数据值。
3、访问 Array items 数组项 具有数字索引的数组对象。
4、访问 Object members 对象成员 具有字符索引的js对象。
从上面的例子我们也能猜到 访问 局部变量(doc)比访问对象成员和数组项更快。(这里暂时不考虑 dom scripting ,因为第三章会讲。)
那么为什么访问对象成员 和数组项要慢呢? 书中说的很详细,我只介绍一下自己的理解和摘录。
大多数 javascript 代码以面向对象的形式编写。无论通过创建自定义对象还是使用内置的对象,诸如
文档对象模型(DOM)和浏览器对象模型(BOM)之中的对象。
对象成员包括属性和方法,在 JavaScript 中,二者差别甚微。对象的一个命名成员可以包含任何数据类
型。既然函数也是一种对象,那么对象成员除传统数据类型外,也可以包含一个函数。当一个命名成员引
用了一个函数时,它被称作一个“方法”,而一个非函数类型的数据则被称作“属性”。JavaScript中的对象是基于原形的。原形是其他对象的基础,定义并实现了一个新对象所必须具有的成
员。这一概念完全不同于传统面向对象编程中“类”的概念,它定义了创建新对象的过程。原形对象为所有
给定类型的对象实例所共享,因此所有实例共享原形对象的成员。一个对象通过一个内部属性绑定到它的原形。Firefox,Safari,和 Chrome 向开发人员开放这一属性,称
作__proto__;其他浏览器不允许脚本访问这一属性。任何时候你创建一个内置类型的实例,如 Object 或
Array,这些实例自动拥有一个 Object 作为它们的原形。因此,对象可以有两种类型的成员:实例成员(也称作“own”成员)和原形成员。实例成员直接存在于
实例自身,而原形成员则从对象原形继承。
这些很难理解,但是看了后很透彻。紧接着最后一句话,你调用实例成员肯定比调用原型成员要快,比如
var book = {
title: "High Performance JavaScript",
publisher: "Yahoo! Press"
};
alert(book.toString());
alert(book.title);
book 本身是没有toString 的 但是程序编译并不报错,因为toString是它的原型成员。
假设book.title === book.toString()(上面已经讲了属性和方法的区分其实并不严格) book.toString() 依旧比 book.title 更慢。
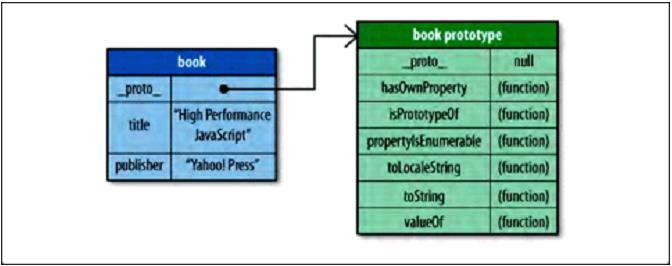
book创建后 其 原型绑定在 _proto_ 内部属性上 , 观察这个原型可以看到 toString() 这个标识符 book 本身并没有toString这个function
而是从它的原型上继承得来。有一个前提问题:在调用 book.title 的时候,js引擎如何知道 title是否是未定义的呢?
在函数执行过程中,每遇到一个变量,标识符识别/解析这些变量的方法是按顺序搜索运行期上下文的作用域链查找同名标识符,如果找不到就是未定义,
所以通常返还未定义注定是检索了整个作用域链。正是这种类似的深度搜索影响了性能。
如果在作用域链里 toString 比 title更靠后那么就 可以确定title 会比toString更先找到。
什么是运行期上下文,什么是作用域链?
每一个 JavaScript 函数都被表示为对象。进一步说,它是一个函数实例。函数对象正如其他对象那样,
拥有你可以编程访问的属性,和一系列不能被程序访问,仅供 JavaScript 引擎使用的内部属性。其中一个
内部属性是[[Scope]],由ECMA-262 标准第三版定义。内部[[Scope]]属性包含一个函数被创建的作用域中对象的集合。此集合被称为函数的作用域链,它决定
哪些数据可由函数访问。此函数作用域链中的每个对象被称为一个可变对象,每个可变对象都以“键值对”的形式存在。当一个函数创建后,它的作用域链被填充以对象,这些对象代表创建此函数的环境中可访问
的数据。例如下面这个全局函数:function add(num1, num2){
var sum = num1 + num2;
return sum;
}
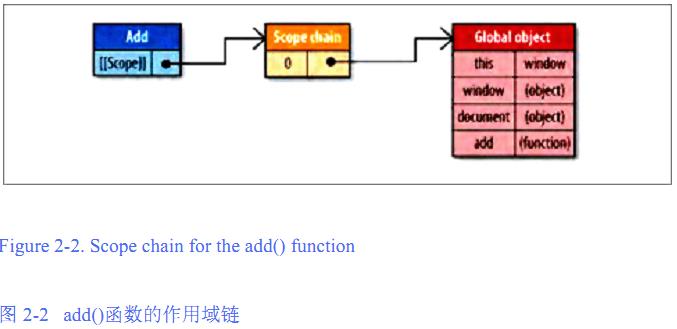
图中 只给出了 全局对象 在作用域链的位置,并没有不包括所有的。
注意:scope chain (作用域链) 里的 这些可变对象都是以键值对的形式存在的。
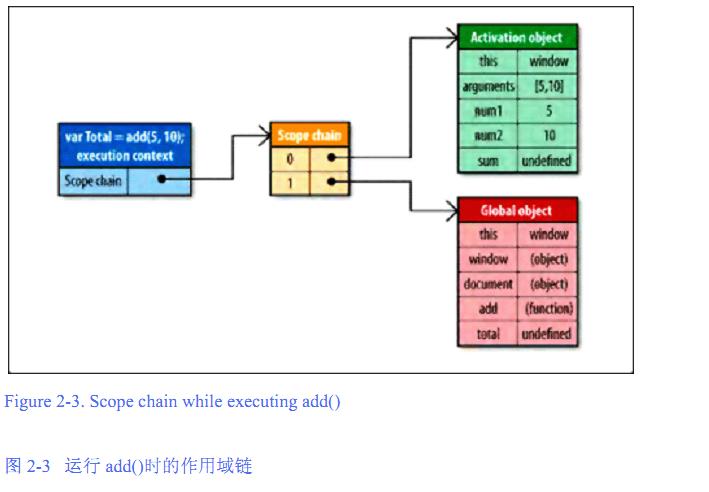
图中的 activation object 被译为 激活对象 此对象是在 此add函数被调用时创建的 例如:运行此代码 var s = add(1,2);
运行此段代码时会创建一个内部对象(之前已经提到,上图左侧篮框就是)称作 execution context 就是上面讲的运行期上下文。 它定义了一个函数运行是的环境。
而值得一提的是 对函数的每次运行而言,每个运行期上下文都是独一的,所以多次调用同一个函数就会导致多次创建运行期上下文。当函数执行完毕,运行期上下文就被销毁.
运行期上下文也是有scope chain的。这个作用域链被用于 标识符解析 。 换句话说,标识符解析就是在扫描运行期上下文的作用域链,运行期上下文的作用域链是如何构成的呢?
当 运行期上下文被创建的时候 它的作用域链被初始化 连同 函数的[[scope]]属性 中所包含的对象 会按照顺序被复制到 运行期上下文的作用域链里。最后你看到的就是
激活对象了。 如图它被推向了作用域链的前端。 而标识符识别是从前到后的。
简单讲最终结果是 toString 标识符所在的位置 是作用域的后端 而 title 标识符实在作用域链的更前端,所以toString会更慢。
回到最开始的话题你会发现 你仅仅是 把 document 缓存到一个 局部变量 doc 里就可以减少 一次或者更多次非常深的 标识符扫描。 因为在function 执行时产生的运行期上下文局部变量总是更靠前的。
同时可以意识到 成员嵌套越深扫描作用域链越深。成员嵌套越深,访问速度越慢。location.href总是快于 window.location.href
这有点类似于 尾递归的作用了。
书中详细说了 标识符性能、 动态作用域、闭包可能导致内存泄漏、改变作用域链。以及有关原型、原型链。总之受益匪浅。
以上是关于读高性能JavaScript编程 第二章 让我知道了代码为什么要这样写的主要内容,如果未能解决你的问题,请参考以下文章