程序设计语言实践之路
Posted autoria
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了程序设计语言实践之路相关的知识,希望对你有一定的参考价值。
1
脚本语言比编译语言慢,因为编译语言可以固定一个值的位置,可以通过生成的机器指令访问。脚本语言每次必须从表中查找。
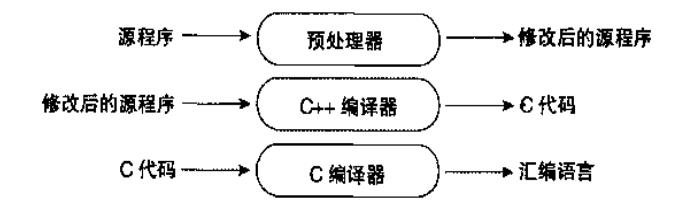
大致的结构:
一个预处理器,用于去除注释、空白,标记出token,展开缩写;
编译器,用于产生汇编语言。
连接器,将库连接。
汇编器:产生机器语言。
早期的AT&T编译器会将c++编译成c语言,再由c语言编译器编译成汇编语言。
编译的整个过程大概如下:
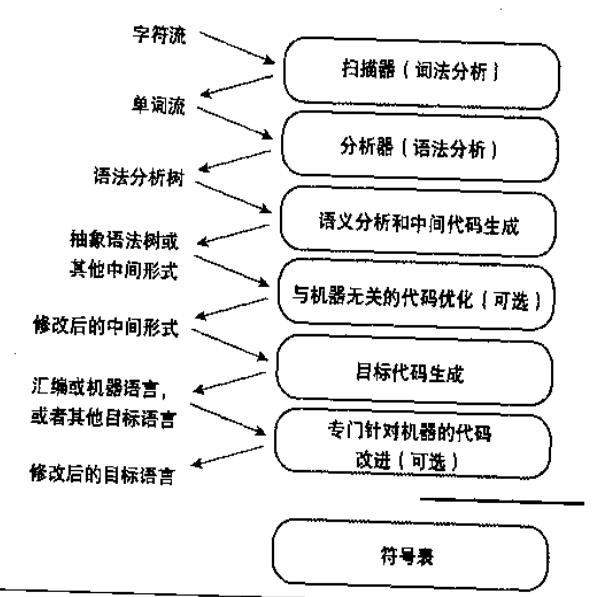
符号表服务于整个编译过程。
以语义分析为分割为前端和后端,前端的任务是分析语义,后端的任务是产生等价的代码。
常把编译过程分为多个passes(每个pass是编译过程中的一小段),每个pass可以对应不同的前后pass。
2.1推导和语法分析树
上下无关文法的记法(BNF)参考自正则表达式,但是正则表达式不能递归表达自己。
一条规则的左边是一个非终结符,右边是一个终结符,对于程序语言而言,终结符就是一个token
空串:ε或λ
拼接:挨着写或者.
(严格来说不包括)选择:|
扩展上下无关文法(EBNF)
(严格来说)比BNF多的部分
+:表示一个或多个
*:表示零个或多个
|:表示多选一
():表示内容被视为一个单位处理
[]:表示内容一次或多次重复,也有人表示内容是可选的
{}:表示内容零次或多次
推导(derivation):将非终结符替换成终结符的一系列过程
句型(sentential form):推导过程中的每一个字符串
最右推导(规范推导):每次替换最右的非终结符
推导的过程可以表示为一个语法分析树,树根就是开始符号,树叶对应最终结果,这样的一棵语法分析数并不唯一
2.2扫描器和语法分析器
 CFG指Context-Free grammar。
CFG指Context-Free grammar。

2.2.1扫描
类型上分为:手写扫描器(多以case语句处理控制流)、表驱动(使用一个数据表和一个驱动程序)
需要识别和实现:词法错误、编译注释(pragma)、向前探查(越复杂的语言可能需要探查越多)
2.2.2自上而下和自下而上的语法分析
一个CFG就是一个CF语言的生成器(generator),而语法分析就是一个语言的识别器(recognizer)。
算法:可以证明任何CFG都可以构造出一个O(n³)的语法分析器,但是一些类型的文法可以实现线性识别,其中最重要的两者是LL、LR。
LL:自左向右,最左推导,或称自上而下。可以手动实现。从根节点向下构造语法分析树,基于输入中的token预测使用产生式。
LR:自左向右,最右推导,或称自下而上。一般用生成器实现。从树叶出发向上构造语法分析树,识别出何时一组树叶已经构成一个节点的所有子节点。
例子:对于串A,B,C;分别使用LL和LR分析,可以看出两者的不同
使用的文法:
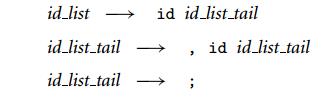
推导的过程: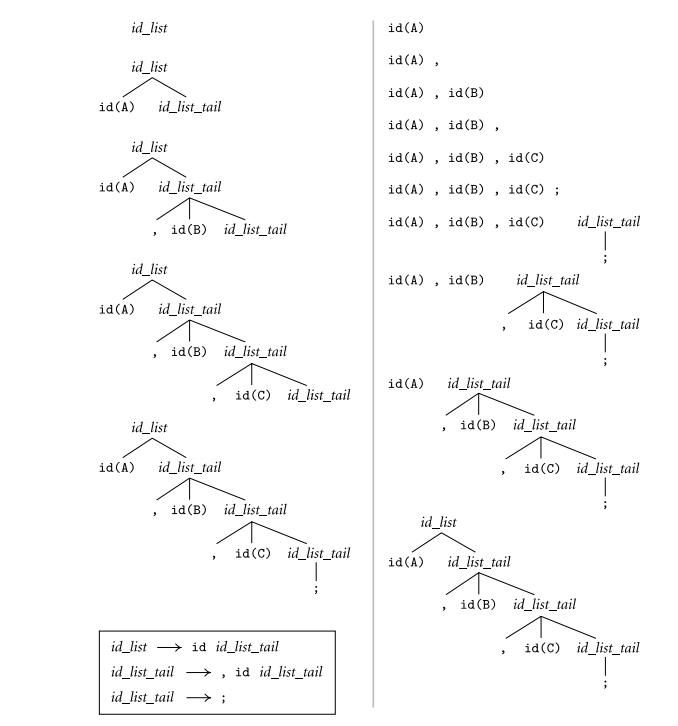
可以看出对串的匹配方向是相反的,自上而下的LL需要“预测”或者说“期待”下一个匹配的字符,LR是出现最右匹配后回溯整个过程。
所以从实现上而言,LL是读一个匹配一个,LR需要”预读“,显然LL更容易实现。
子类
LR:SLR, LALR,完全LR,其中SLR和LALR很容易实现,完全LR具有一般性。
LL:SSL, 完全LL。
形如LL(1)、LR(0)表示进行语法分析时需要向前探查的token个数。
之前所述的文法可以同时作用于LL和LR,但是对LR而言必须全部读入token后才能进行规则匹配,可以改变文法,使其适应LR寻找最右匹配后才匹配的做法。
改变前: 改变后: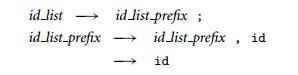
2.2.3递归下降
2.2.4语法错误
术语语法错误恢复指一系列编译器遇到语法错误后继续去寻找错误的手段,其中最简单的一种方法称为应急模式。
常见三种方法:
Wirth的短语级恢复;
依赖于语言异常处理的恢复;
多用于自上而下表驱动语法分析器的local least-cost syntax repair;
2.2.5表驱动的自上而下语法分析

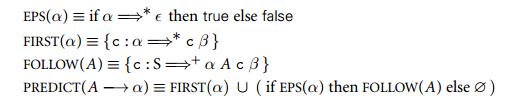
(附一个本书e3上的图片)
用人话说,FIRST()输入的是一个串,寻找的是一个产生式,该产生式符合形式:输入串α=>*token 另一串β ,返回token的集合。可以看出FIRST集合基本上就是把所有产生式展开一下。总之,FIRST()的目的是寻找所有展开的可能。
FOLLOW()接受的是一个非终结符,寻找的是一个产生式,该产生式符合形式:开始符号S=>+串α 非终结符A token 串β,返回token的集合。(本书e1、e2版本中FOLLOW集合中尚且含有ε,e3中不再有,实际上FOLLOW集合应该只包含终结符和$,其中$表示的是输入串结束)
综合FIRST集合和FOLLOW集合的概念,我们就可以定义出PREDICT集合,PREDICT()的输入是一个产生式,产生的集合的元素是token,集合元素可以用FIRST和FOLLOW集合定义。
如果对于同一个产生式有两个PREDIT集合,那么称之为一个predict-predict conflict。
构建各个集合的过程可以从LL文法本身直观的观察开始,比如对于一个计算器的LL文法:
我们可以观察出:
再结合两表推导出更多关于FIRST和FOLLOW,详细不表。
得到完整的FIRST和FOLLOW后我们可以得到PREDICT集合:

并且根据PREDICT集合得到表驱动程序需要的表。
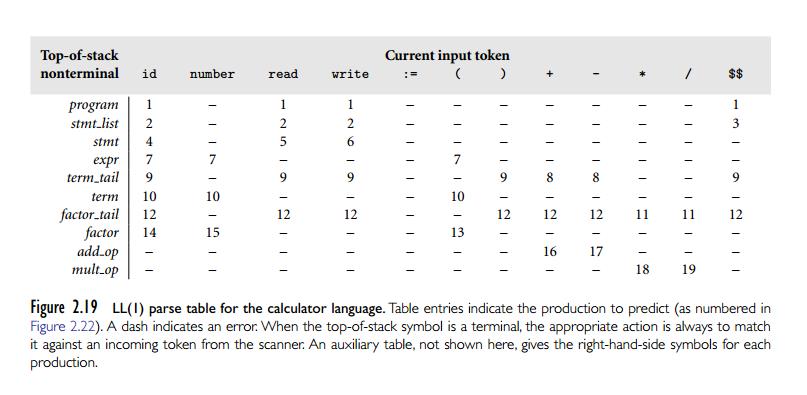
这样,输入流当前的token和栈顶的非终结符匹配时,可以通过表中的值,在PREDICT集合中找到我们预计会出现的产生式。
写LL(1)文法
采用自上而下的分析器时,我们需要解决LL(1)文法常见的两个障碍:左递归和共同前缀
左递归指的是为产生式右部的第一个非终结符和左部一样,表现为: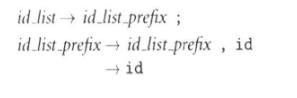
在FIRST(id)和FOLLOW(id_list_prefix)将同样得到id,在PREFIX中,栈顶为id_list_prefix时与输入流id匹配的产生式就有
id_list_prefix->id_list_prefix, id
id_list_prefix->id
解决办法是更改为右递归: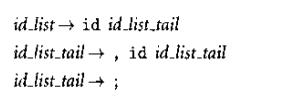
共同前缀指的是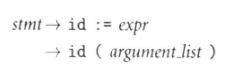 ,这样FIRST(stmt)将会有两个集合都包含id,PREDICT也因此预测两个产生式。
,这样FIRST(stmt)将会有两个集合都包含id,PREDICT也因此预测两个产生式。
解决办法是左因子分解,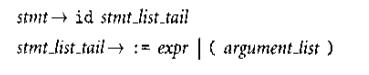
消除左递归和公共前缀不是写出LL(1)文法的灵丹妙药,实际上存在着不能写出LL(1)文法的程序,比如Pascal。
2.2.6自下而上的语法分析
自下而上的语法分析中几乎都是使用表驱动,其中堆栈扮演的角色有所不同,在自上而下文法中,堆栈保存的是希望看到的结构,而在自下而上文法中,堆栈保存的是已经确认的结构。
在自下而上的语法分析中,我们把输入流的token逐一放入堆栈中,当满足一个子树的根时就把叶节点取出来,再放入子树的根,继续考虑2.2.2中的LL文法如下:
推导过程中加下划线的部分称为句柄,表示文法: 的反向推导。
的反向推导。
如果我们使用更适合自下而上语法分析的LR文法,会发现在LR中处理左递归可以减少堆栈的使用。
成功进行LR分析的关键:堆栈顶部出现了句柄
(。。。参考书本)
基本概念:
context-sensitive grammar
S -> aSb
S -> ab
这个文法有两个产生式,每个产生式左边只有一个非终结符S,这就是上下文无关文法,因为你只要找到符合产生式右边的串,就可以把它归约为对应的非终结符。
比如:
aSb -> aaSbb
S -> ab
这就是上下文相关文法,因为它的第一个产生式左边有不止一个符号,所以你在匹配这个产生式中的S的时候必需确保这个S有正确的“上下文”,也就是左边的a和右边的b,所以叫上下文相关文法。
3binding time
约束时间指的就是约束建立的时间, 比如连接时、装入时、运行时,具体见P107。binding time的早晚会影响语言的运行速度,其间例子是smalltalk的对象消息机制,看起来和python的鸭子类型相似。
对象的生存周期与其存储管理的机制有关,一般来说存储管理机制可以分为栈分配、堆分配、静态分配。
约束的静态分配可以是一个广义的概念,不仅仅指程序的静态变量或者字面量,也包括运行时的表格、编译器生成的机器指令等在程序执行中不被改变的对象。一般来讲这些对象都分配在受保护的只读区,写它们会导致中断。
历史:fortran曾经只支持静态的变量(因为当时的机器支持堆栈会浪费很多资源),现在的静态变量一般分为编译时常量(只能由字面量命名)、运行时常量(运行时确定后不改变的常量,如c语言的static变量)
3.2.1基于堆栈的分配
大部分基于堆栈分配的程序都使用sp和fp定位,使用 fp+偏移量 访问一个程序帧里的某个位置。一般而言,参数和返回值总是在fp的正偏移量处,其他信息在负偏移量处。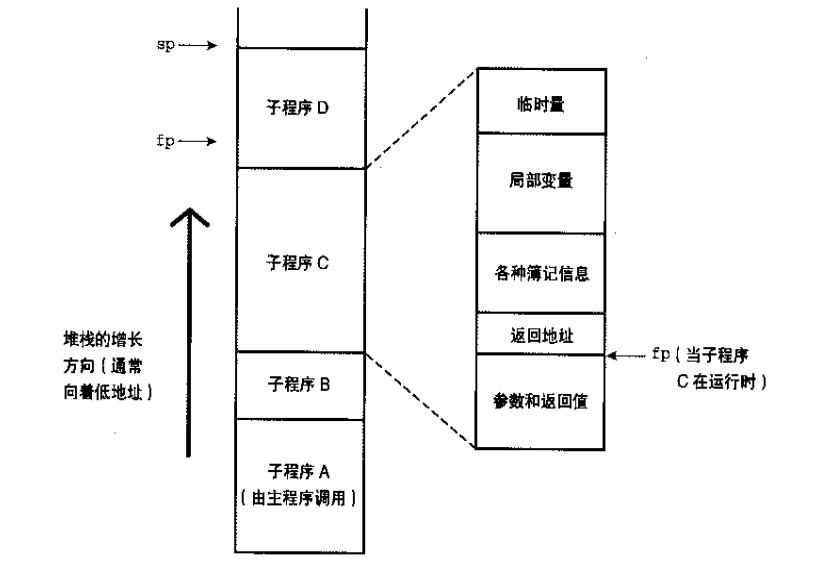
3.2.2堆分配
堆上可以在任何时刻分配内存空间。为此有最优适配和最先适配两种算法。
前者选择第一个最合适的自由块,后者选择整个自由表中最小的自由块。因为分配一个自由块而在自由表中造成的碎片称为外部碎片,在一个自由块中分配后因不使用造成的是内部碎片。
为了减少外部碎片,我们可以为每个自由块都分配一个自由表,概念上我们称为将堆划分为存储池,存储池的大小可以是动态也可以是静态的。动态的存储池分配策略有伙伴系统(Buddy system)和斐波那契堆。
紧缩用来形容合并外部碎片的过程。因为在最坏的情况下,哪怕堆的总大小满足分配的总需求,无论是静态或是动态分配都会遇到无法处理的问题。对于前者,可能是单个特大的分配需求,对于后者,可能是连续大量分配小的空间后再间隔地释放其中一些小的空间,造成很多外部碎片无法被后来的大的分配使用。
3.2.3垃圾回收
垃圾回收会消耗更多运行时的资源,但是手工释放却可能导致悬空引用等更为严重的后果,所以垃圾回收是未来的流行趋势。
3.3作用域规则
一个约束在程序中起作用的区域称为这个约束的作用域
3.3.1静态(词法)作用域
一个关于Fortran作用域的精彩分析,见书。
嵌套作用域

可以解释为一个括号的模型,p1(p2(p3) p4(f1)),一组括号就表示一组作用域,作用域访问的顺序是从自己作用域的最内层开始向上访问(不能平行地访问)。比如f1的作用域最终可以上溯为p1 p2(p3) p4 f1,除了p3都可以访问。实现方法可以是一个静态链:
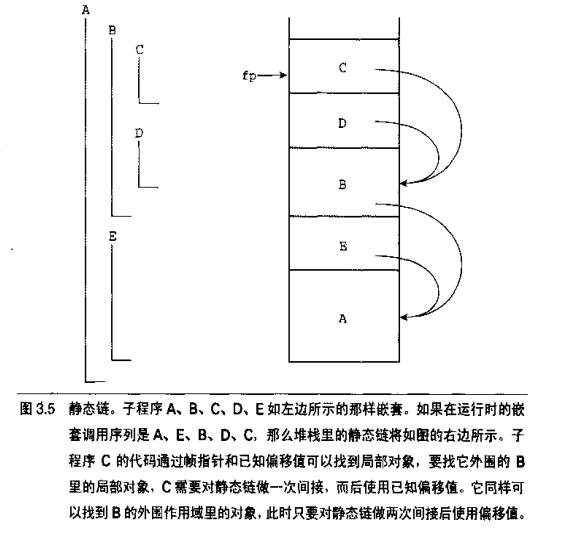
如果一个名字对象约束被嵌套的同名约束所遮蔽了,我们说在当前作用域中,被遮蔽的约束是一个空洞。除非提供一个修饰符指明,大部分程序不允许访问空洞。
重命名:
在大部分解释性语言里,在一个作用域里重新约束一个名字将导致全局的重新约束,这通常用来修正错误(在我看来不应该使用这种方式)。但是ML是个例外

模块
语言使用模块的概念完成封装,模块满足1)内部相互可见 2)内部与外部相互不可见。
普遍类型pervasive:一门语言的数据类型原语,或者说全局可见的类型。
非透明性类型opaquely:对于一个类型仅仅可以使用,而不能知道它的信息,比如大小。
开/闭作用域:名字必须现式导入的模块称为闭作用域的,在Modula和Haskell中模块是闭作用域的;在Ada、Java、C#、Python中,模块是半开作用域的,在B模块中可以使用A.foo访问名称foo,也可以显式导入后直接使用foo。
一些语言甚至连子程序都是闭作用域的,通过使用导入表作为与作用域之间的接口,除此之外,导入表还可以解决别名的问题。别名可能来自于Pascal和C里的变体记录和联合,也可能来自指针,或是向一个子程序中传入一个本来就可以直接访问的变量的引用。在Euclid和Turing的导入表就起到了检测第三种类型别名的作用,Module的导入表则仅仅作为接口而存在。
为了实例化多个模块,一般有两种做法:module manager和将模块扩展为类,前者基本是历史问题,在Clu中模块只能创造一个实例,所以将模块写为一个模块管理器,为模块中的每个子例程标记一个参数用于区分,术语集群也来自于这种管理关系,详情见书第三版modules as managers。后者是OO语言中类的雏形,可以说类是模块加上继承。
模块也被用来支持单独编译,详情见书第三版Modules and separate compilation。
在现代语言中,模块和类的概念已经完全分离,模块用于管理,类用于优化设计。
3.3.2动态作用域
作用域在运行时确定,缺点是运行时时间消耗很大,优点是切换引用环境(这个优点微乎其微,现在几乎都不用动态作用域了)
3.3.3符号表
符号表都是一个保存名字和对象的哈希表,基本上要支持insert和lookup两种操作。为了实现作用域,一个简单的remove操作是不现实的,论述见书第一版3.3.3节。我们使用一堆enter_scope/leave_scope操作维持可见性的轨迹(就是不会把符号表的东西给删了,整个过程会被保留,可以看见,方便纠错)。
这样一个有良好可见性的符号表有多种实现方式,书中给出LeBlanc和Cook的一种实现,详细见书第一版3.3.3节。
3.3.4Associaion List and Central Reference Tables
在动态作用域的语言中为了实现静态语言中的追踪名字约束的功能,一般采用关联表和中心参考表,因动态作用域过时了,详细见书。
第三版拓展
别名aliases:一个对象有多个关联名字
重载overloaded:一个名字可以拥有多个关联名字
别名可能给编译器优化造成困难一个来自本书第三版p145的示例说明
int a, b, *p, *q; ... a = *p; /* read from the variable referred to by p */ *q = 3; /* assign to the variable referred to by q */ b = *p; /* read from the variable referred to by p
如果p和q指向同一个位置,第三句就会受第二句影响,编译器很难判断出是否如此,所以C99中加入了restrict关键字来人为地为编译器标记。
两个和重载概念相近的概念
强迫Coercion:当向上下文需要时,编译器将一种类型的值转换为另一类型的值。有些语言如C++允许用户自定义这种Coercion
多态:作者认为多态大概有三中Explicit parametric polymorphism is also known as genericity. Generic facilities appear in Ada, C++, Clu, Eiffel, Modula-3, Java, and C#, among others. 显式参数多态是泛型
Implicit parametric polymorphism appears in the Lisp and ML families of languages, and in the various scripting languages; 隐式参数多态
subtype polymorphism is fundamental to object-oriented languages, in which subtypes (classes) are said to inherit the methods of their parent types 子类多态,面对对象的基础。
大部分情况下,泛型通过创建多态代码的多个副本来实现。
继承(子类型多态)创建单个副本,并通过在对象中的元数据来判断何时进行不同的处理。
隐式参数多态可以通过以上两种方式创建。
重载为每种方法写一个处理的副本,泛型让编译器为每种副本生成一种处理方法。从语义来说,重载其实是一个名字对应了多个例程,是一种特殊的多态。
3.4引用环境的约束
浅约束:约束的环境与调用时的环境相关,动态作用域的语言默认采用这种手段。
深约束:约束的环境与定义时的环境相关,在Lisp中称为funarg。
3.4.1子程序闭包
闭包:将约束的调用和上下文关联起来的一个整体称为闭包。
在动态作用域语言中,深约束一般是可选的,使用关联表实现深约束较简单,只要保存定义时的作用域的栈顶指针就好;对于中心引用表更麻烦一些,需要复制使用到的数组和对应表的第一项。在静态作用域语言中,一般默认使用深约束,因为一个名字-对象约束与其词法位置相关而与执行流无关。
一个需要处理的问题是,在递归程序之中,一个对象可以同时存在多个实例,静态作用域语言里的闭包必须能记住对应的实例,哪怕调用的实例之后又建立了一些实例。为此,我们使用之前提到的静态链,当一个闭包要访问一个非局部对象的实例时,就可以临时地恢复(而不是再建立)保存起来的静态链,访问对应的实例和上下文。
对于静态作用域的语言而言,约束规则只影响既非局部又非全局的对象的访问,因为一个局部对象的定义和引用是一个作用域,而一个全局对象只有一个实例。
3.4.2一级和二级子程序
一级:可以传入,可以传出,可以赋值
二级:可以传入,但是不能传出也不能赋值
三级:连传入都不允许
之前只考虑了二级子程序,在嵌套子程序中,因为子程序可以被传出,一级子程序可能会出现悬空引用:即一个子程序的引用的生存期比子程序作用域生存期还长。为此不同语言有不同的解决方案,c/c++不支持嵌套子程序的作用域,函数式语言支持局部变量拥有不受限的生存期,除非垃圾收集系统回收它们。显而易见的是,具有受限生存期的局部变量在栈上分配,不受限生存期的局部变量在堆上分配。
对象闭包
对闭包中的环境的引用将仅在传递嵌套子例程时才是重要的,所以对于不支持嵌套子程序的语言,必须采取其他手段。(在很多命令式语言中,为了避免堆分配的资源使用,使用了不受限生存期的局部变量)
在java中,可以写出
interface IntFunc { public int call(int i); } class PlusX implements IntFunc { final int x; PlusX(int n){x=n;} public int call(int i) { returni+x;} } ... IntFunc f = new PlusX(2); System.out.println(f.call(3)); // prints 5
这样的代码称为对象闭包
更多例子见本书第三版p158,#包括一个暂时看不懂的C++例子
4语义分析
属性:语义分析和中间代码生成都可以通过在语法树上的标注(或修饰)的方式描述,这种标注称为属性。
属性文法:
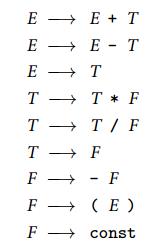 这是一个数学表达式的LR文法的表达式,E指Expr,TT指term_tail,F指Factor。
这是一个数学表达式的LR文法的表达式,E指Expr,TT指term_tail,F指Factor。 为了赋予其数学算式的意义,我们给出一个val属性表示字面值。属性文法指的就是这样一个具有属性表示的上下文无关文法(或者说有semantic rule),属性文法应用于AST时,可以在树的节点之间传递信息。我们主要关注于将属性文法作为一个框架,用于构造语法树、检查语义规则和生成代码。
为了赋予其数学算式的意义,我们给出一个val属性表示字面值。属性文法指的就是这样一个具有属性表示的上下文无关文法(或者说有semantic rule),属性文法应用于AST时,可以在树的节点之间传递信息。我们主要关注于将属性文法作为一个框架,用于构造语法树、检查语义规则和生成代码。
(给出一个属性文法的定义):
复制规则:产生式3、6、8、9的规则是复制规则,说明一个属性是另一个属性的副本。
语义函数:语义函数可以是任何设计者描述的任意复杂的函数,其参数必须是本产生式里某个符号的属性,不能包括常量。结果通常也赋给当前产生式某个符号的属性。我们使用▷表示后跟一个语义函数。
4.3属性流
正如上下无关文法没有描述具体的语法分析一样,属性文法也没有描述属性规则应该按照什么顺序求值,不同的属性文法可能采取不同的求值顺序。
标注(修饰)annotation(decoration):对属性文法的求值过程被称为语法分析树的标注(修饰),由此得到的一个标注了属性的语法分析树也可以称为是一个decoration。
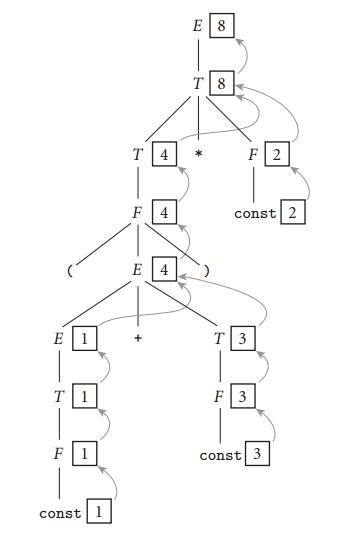 对于表达式(1+3) * 2,我们可以应用的S-attribute的属性文法,就可以得到这样一个解析树的decoraton,可以看到,每个属性都是从其子节点获得的。
对于表达式(1+3) * 2,我们可以应用的S-attribute的属性文法,就可以得到这样一个解析树的decoraton,可以看到,每个属性都是从其子节点获得的。
这里的概念参考网上资料:
Synthesized attributes:假设生产式:S->ABC,综合属性指的是S的值从它的子节点ABC得来,即ABC属性的值合成得到S的属性的值。
Inherited attributes:继承属性和合成属性相反,从父亲和兄弟节点中获得值。
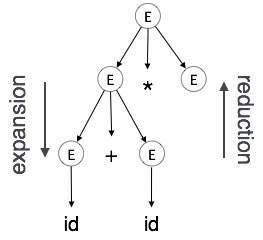
expansion:non-terminal拓展到terminal的过程
reduction:terminal到non-terminal的过程
S-attributed:用来描述一个属性文法里的属性都是synthesized attributes,还是提到属性文法时的这个例子,里面的每个节点的属性都是由子节点的属性给出的。
L-attributed:用来描述一个属性文法里的属性都是inherited attributes或synthesized attributes,但是限制不能通过右兄弟节点获得属性(即满足左结合性),举个例子
S—ABC,B只能从S、A获得属性,而不能从C获得属性。
两者关系: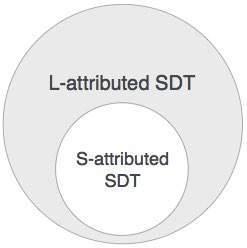
那么什么时候用得到L-attributed呢?之前的算数表达式的文法准确来说是SLR(1)的(而不仅仅是LR),我们来看一个算数表达式的LL(1)的文法:

好吧这只是个减法的LL(1)文法,对于9 - 4 - 3,我们可以得到一个解析树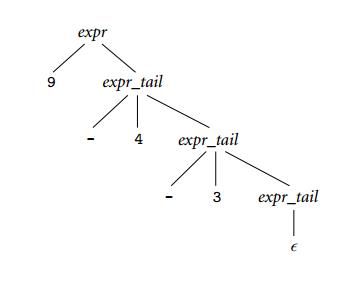
由于减法的左结合性,如果要对这个解析树使用一个S-attributed的属性文法,我们将不得不把所有表达式都保留下来,直到树根处才能使用一个复杂的语义函数计算出结果。
所以我们必须放宽条件,使用non-S-attributed的属性文法,允许传送一个中间值,我们改进记法,在每个节点旁边的左边表示一个中间值,右边表示一个右子树的值,得到一个解析树的decoration如: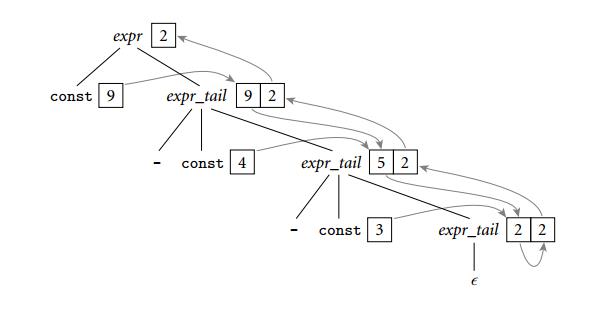
属性文法如:
完整LL(1)属性文法如:
应用于同样的(1+3)*2例子,decoration会很复杂: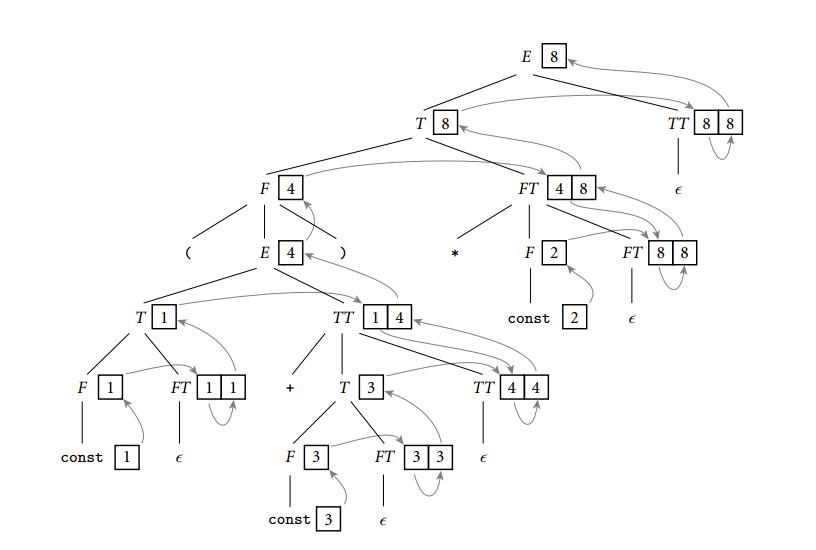
属性流:箭头指向的顺序称为属性流。
由上可见,我们对LL使用L-attributed属性文法,对LR使用S-attributed属性文法,实际上,L-attributed属性文法是对LL文法在语法分析的同时进行语义分析(属性求值)的最一般的一类文法,S-attributed属性文法对LR文法也是如此。
依赖:如果一个属性B.t被送给某个语义函数,函数返回值赋予A.s,我们就称A.s依赖于B.t。根据依赖的定义,我们可以定义L-attributed属性文法应满足两条规则:(1)产生式左部符号的每个综合属性只能依赖于本符号自身的继承属性,或产生式右部符号的属性(综合或继承)(2)产生式右部符号的继承属性只能依赖于其产生式左部符号的继承属性,或者右部中其他左侧符号的属性(综合或继承)。
良好定义的:如果一个属性文法对于任何可能的解析树总能得到确定的一系列值,我们称之为well defined
无环:如果一个属性文法对于任何可能的解析树不会出现一个节点的属性依赖于它自己,我们称之为无环
翻译模式:通过以与树的属性流一致的顺序调用属性语法的规则来decorate解析树的算法被称为翻译模式。
oblivious翻译模式:在解析树上重复传递值,调用任何已经满足参数需求的语义函数,并且在完成没有值改变的传递时停止。这样的方法没有利用到解析树和语法的特点,称之为oblivious的。只有当属性文法是良好定义的情况下,这个方法才是有效的。
dynamic翻译模式:比oblivious更快的方案是,先为特定解析树构造一个结构,例如对属性流图进行拓扑排序,然后以与排序一致的顺序调用规则。
static翻译模式:最快的方式是静态分析,以LR文法为例,对其应用S-attributed属性文法,属性流是严格自下而上的,所以在语法分析的同时机械地完成语义分析。
one-pass compiles:将语法分析、语义分析、代码生成同时进行的编译器。
以上提到的属性文法都用于给解析树做decoration(求值),除此之外,如果我们不交错地进行语法分析和语义分析,我们仍然为上下文添加属性规则(形成属性文法)。这时属性文法用来创建一个语法树,而不是应用语法规则或者生成代码(这里可以看之前的属性文法定义)。


这里的make_leaf/make_un_op/make_bin_op都返回解析树节点的指针,分别包含常数/一元运算符/二元运算符,生成的解析树有点大,不复制过来了。
(参考材料):chrome-extension://ikhdkkncnoglghljlkmcimlnlhkeamad/pdf-viewer/web/viewer.html?file=https%3A%2F%2Fwww.cs.fsu.edu%2F~engelen%2Fcourses%2FCOP402001%2Fnotes4_4.pdf
4.4动作例程 action routine
正如存在根据CFG生成语法分析器的工具,也存在根据AG生成语义分析器的工具。
动作例程:动作例程就是一个语义函数,编译器将在语法分析的某个阶段执行它。对于LL文法而言,当分析器预测一个产生式时,终结符(需要去匹配)、非终结符(用于推导进一步的预测)、指向动作例程的指针。当分析器看到一个指针位于顶部时,就去执行它。对于LR文法而言,只有在确定的产生式之后才能执行动作例程,所以有时我们得访问继承属性或当前产生式之外的信息。
这是一个使用行动例程的LL(1)文法
属性堆栈:在不构造显式分析树的编译器里,需要有另外的机制去分配、释放和访问属性的储存空间。对于一个S-attributed自下而上分析器,可以维持一个直接和语法分析栈对应的属性堆栈。分析栈上每个状态的编号对应的是进入该状态时所移入的符号的属性记录。自上而下分析的情况会更复杂一些
5汇编层计算机体系结构
处理器在做的事情基本上就是1.从存储器取指令 2.对指令解码3.从寄存器或存储器取操作数4.执行操作5.将结果放回寄存器或存储器
数据对齐: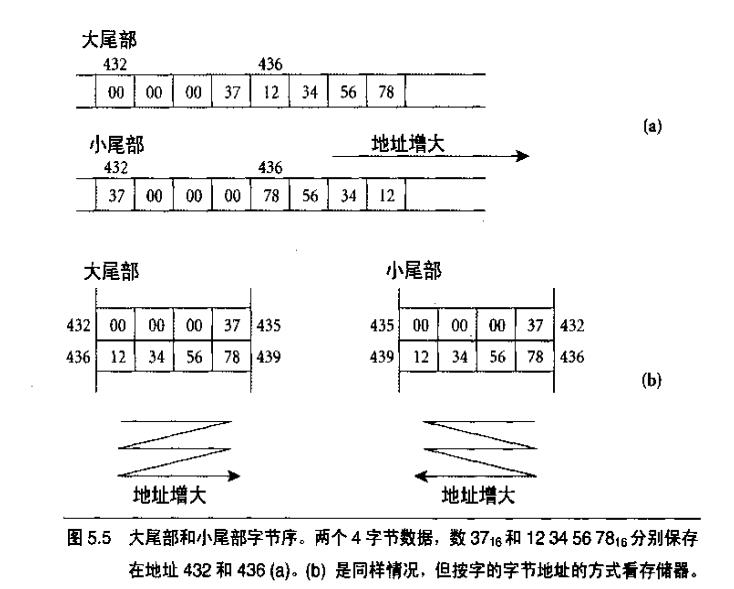
5.6.1维持流水线满
以上是关于程序设计语言实践之路的主要内容,如果未能解决你的问题,请参考以下文章