tensorflow训练好的模型,怎么调用?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了tensorflow训练好的模型,怎么调用?相关的知识,希望对你有一定的参考价值。
调用时,代码如下:

y即为输出的结果。
github传送门:SymphonyPy/Valified_Code_Classify
一个识别非常简单的验证码的程序
保存训练好的模型的代码如下:

训练完一个模型后,为了以后重复使用,通常我们需要对模型的结果进行保存。如果用Tensorflow去实现神经网络,所要保存的就是神经网络中的各项权重值。建议可以使用Saver类保存和加载模型的结果。
1、使用tf.train.Saver.save()方法保存模型
tf.train.Saver.save(sess, save_path, global_step=None, latest_filename=None, meta_graph_suffix='meta', write_meta_graph=True, write_state=True)
sess: 用于保存变量操作的会话。
save_path: String类型,用于指定训练结果的保存路径。
global_step: 如果提供的话,这个数字会添加到save_path后面,用于构建checkpoint文件。这个参数有助于我们区分不同训练阶段的结果。
2、使用tf.train.Saver.restore方法价值模型
tf.train.Saver.restore(sess, save_path)
sess: 用于加载变量操作的会话。
save_path: 同保存模型是用到的的save_path参数。
使用 TensorFlow, 你必须明白 TensorFlow:
使用图 (graph) 来表示计算任务.
在被称之为 会话 (Session) 的上下文 (context) 中执行图.
使用 tensor 表示数据.
通过 变量 (Variable) 维护状态.
使用 feed 和 fetch 可以为任意的操作(arbitrary operation) 赋值或者从其中获取数据.
综述
TensorFlow 是一个编程系统, 使用图来表示计算任务. 图中的节点被称之为 op
(operation 的缩写). 一个 op 获得 0 个或多个 Tensor, 执行计算,
产生 0 个或多个 Tensor. 每个 Tensor 是一个类型化的多维数组.
例如, 你可以将一小组图像集表示为一个四维浮点数数组,
这四个维度分别是 [batch, height, width, channels].
一个 TensorFlow 图描述了计算的过程. 为了进行计算, 图必须在 会话 里被启动.
会话 将图的 op 分发到诸如 CPU 或 GPU 之类的 设备 上, 同时提供执行 op 的方法.
这些方法执行后, 将产生的 tensor 返回. 在 Python 语言中, 返回的 tensor 是
numpy ndarray 对象; 在 C 和 C++ 语言中, 返回的 tensor 是
tensorflow::Tensor 实例.
TensorFlow 调用预训练好的模型—— Python 实现
1. 准备预训练好的模型
- TensorFlow 预训练好的模型被保存为以下四个文件
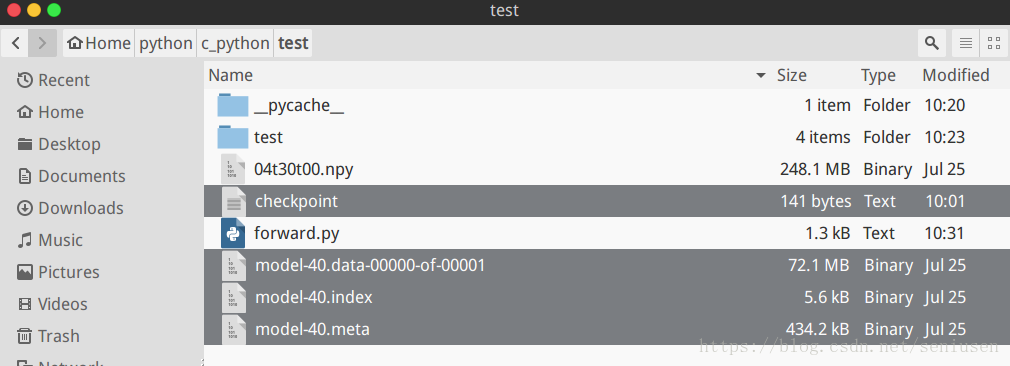
- data 文件是训练好的参数值,meta 文件是定义的神经网络图,checkpoint 文件是所有模型的保存路径,如下所示,为简单起见只保留了一个模型。
model_checkpoint_path: "/home/senius/python/c_python/test/model-40"
all_model_checkpoint_paths: "/home/senius/python/c_python/test/model-40"2. 导入模型图、参数值和相关变量
import tensorflow as tf
import numpy as np
sess = tf.Session()
X = None # input
yhat = None # output
def load_model():
"""
Loading the pre-trained model and parameters.
"""
global X, yhat
modelpath = r‘/home/senius/python/c_python/test/‘
saver = tf.train.import_meta_graph(modelpath + ‘model-40.meta‘)
saver.restore(sess, tf.train.latest_checkpoint(modelpath))
graph = tf.get_default_graph()
X = graph.get_tensor_by_name("X:0")
yhat = graph.get_tensor_by_name("tanh:0")
print(‘Successfully load the pre-trained model!‘)
- 通过 saver.restore 我们可以得到预训练的所有参数值,然后再通过 graph.get_tensor_by_name 得到模型的输入张量和我们想要的输出张量。
3. 运行前向传播过程得到预测值
def predict(txtdata):
"""
Convert data to Numpy array which has a shape of (-1, 41, 41, 41 3).
Test a single example.
Arg:
txtdata: Array in C.
Returns:
Three coordinates of a face normal.
"""
global X, yhat
data = np.array(txtdata)
data = data.reshape(-1, 41, 41, 41, 3)
output = sess.run(yhat, feed_dict={X: data}) # (-1, 3)
output = output.reshape(-1, 1)
ret = output.tolist()
return ret
- 通过 feed_dict 喂入测试数据,然后 run 输出的张量我们就可以得到预测值。
4. 测试
load_model()
testdata = np.fromfile(‘/home/senius/python/c_python/test/04t30t00.npy‘, dtype=np.float32)
testdata = testdata.reshape(-1, 41, 41, 41, 3) # (150, 41, 41, 41, 3)
testdata = testdata[0:2, ...] # the first two examples
txtdata = testdata.tolist()
output = predict(txtdata)
print(output)
# [[-0.13345889747142792], [0.5858198404312134], [-0.7211828231811523],
# [-0.03778800368309021], [0.9978875517845154], [0.06522832065820694]]- 本例输入是一个三维网格模型处理后的 [41, 41, 41, 3] 的数据,输出一个表面法向量坐标 (x, y, z)。
获取更多精彩,请关注「seniusen」!
以上是关于tensorflow训练好的模型,怎么调用?的主要内容,如果未能解决你的问题,请参考以下文章